

复习笔记
一、Java基础
- JVM内存模型
三部分:类加载器子系统、运行时数据区、执行引擎
类加载器:启动类加载器 扩展类加载器 应用程序类加载器 自定义类加载器;双亲委派模式,加载请求最终委派到启动类加载器,父类加载器无法完成加载,子类加载器才会进行加载,保证安全性,避免重复加载
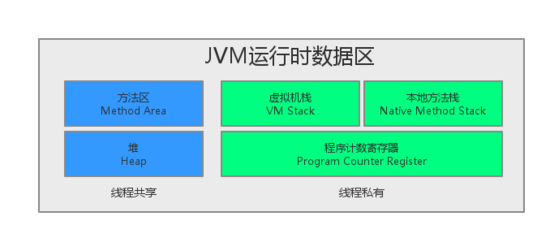
内存模型:![]()
方法区:存放类的信息(字段信息、方法信息、静态变量、ClassLoader引用、Class引用等),常量池也在方法区
堆:存放对象实例和数组值。堆和方法区被所有线程共享,所以在进行实例化等操作时,要解决同步问题
Java栈:有栈帧组成,一个栈帧对应一个方法调用;栈帧又是有局部变量区和操作数栈两部分组成;java栈主要用于存储:方法参数、局部变量、中间运算结果;线程私有,无序考虑栈同步访问问题
本地方法栈:保存native方法进入区域的地址
PC寄存器:存放下一条要执行的指令在方法内的偏移量
执行引擎:JVM执行Java字节码的核心,执行方式:解释执行、编译执行、自适应优化执行等 - JVM垃圾回收
Java的所有释放都由 GC 来做,GC除了做回收内存之外,另外一个重要的工作就是内存的压缩,增加了安全性,当然也有弊端,比如性能这个大问题
根据生命周期,把对象分为:年轻代、年老代、持久代(持久代在方法区中,负责保存反射对象)
年轻代:刚实例化的对象,该区被填满时,GC会将对象移到Old区;会被频繁回收
年老代:年轻代堆空间中长期存活的对象会转移到年老代堆空间中
回收方式:年轻代的是 次收集(Minor GC);年老代的是 全收集(Full GC),System.gc()是全收集
当年轻代堆空间满了的时候,会触发次收集将还存活的对象移到年老代堆空间。当年老代堆空间满了的时候,会触发一个覆盖全范围的对象堆的全收集
不同的引用类型, GC会采用不同的方法进行回收https://www.cnblogs.com/yw-ah/p/5830458.html
强引用:如A a = new A(),宁愿OutOfMemoryError也不会回收
软引用:SoftReference<Object> sf = new SoftReference<Object>(obj);内存不够时回收
弱引用:WeakReference<Object> wf = new WeakReference<Object>(obj);第二次垃圾回收时回收
虚引用:PhantomReference<Object> pf = new PhantomReference<Object>(obj);垃圾回收时回收,主要用于检测对象是否已经从内存中删除 - java7开始,switch支持了String,所以现在switch支持 byte short int char String enum
- 方法重载:方法名一样、参数不一样、不能通过返回类型判断;在同一个类中
- 方法重写(覆盖):返回类型、方法名、参数都要一致;F f = new S(); f.m1()调用的是子类中的m1
- 隐藏:静态方法只能被继承、不能被覆盖,父类和子类中存在相同的静态方法,这时候发生的是隐藏,F f =new S();f.m2(),调用父类中的m2 ;S f = new S();f.m2()调用子类中的m2,也就是说不会发生动态绑定
- this 两个用途
表示当前对象
构造方法中调用另外一个构造方法、必须在第一行。调其他构造方法的目的是减少代码的重复 - super
要的到子类对象就必须先生成父类对象,可以在子类的构造函数中用super(),指定父类的构造方法,必须在第一行
表示父类对象 - static代码块在类被加载时执行、且只会执行一次,不能在静态代码块中使用this
二、多线程
- 为什么要有多线程
CPU在等待I/O的时候,是空闲的,这时候可以让他去做一些其他事,就能够更好的使用CPU的资源 - 多线程并发
在程序中,对共享变量的使用一般遵循一定的模式,即读取、修改和写入三步组成。这三步执行中可能线程执行切换,造成非原子操作。锁机制是把这三步变成一个原子操作
在多线程并发编程中synchronized和Volatile都扮演着重要的角色,Volatile是轻量级的synchronized,它保证了共享变量的“可见性”。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值(线程访问变量是否是最新值)。它在某些情况下比synchronized的开销更小
volatile:
java的内存分为主存和工作内存,线程共享主存,但线程有各自的工作内存;线程访问主存中的共享变量时,会复制一个副本到工作内存,修改的也是副本,使用缓存,修改之后并不会马上刷新到主存中去,其他线程就不会看到共享变量修改后的值;通过volatile关键字修饰变量之后,不使用缓存,会立即刷新到主存,其他线程可以获取到最新值 volatile 并不会有锁的特性,volatile只能保证可见性,不能保证原子性
volatile和synchronized区别:
a.volatile关键字是线程同步的轻量实现,性能比synchronized好,volatile只能修饰变量,synchronized可以修饰方法和代码块
b.volatile能保证可见性,不能保证原子性;synchronized可以保证原子性和可见性,会将公共内存和私有内存的数据做同步处理
c.volatile不会阻塞线程、synchronized会阻塞线程
d volatile解决的是变量在多个线程之间的可见性,synchronized解决的是多个线程之间访问资源的同步性
如:i++ 即i=i+1 不是原子操作(一条指令完成),首先要从内存中取出i 再计算i 再将i写入内存
synchronized和volatile,以及wait、notify等方法抽象层次低,在程序开发中使用比较繁琐,易出错
而多线程之间的交互来说,存在某些固定的模式,如生产者-消费者和读者-写者模式,把这些模式抽象成高层API,使用起来会非常方便
java.util.concurrent包为多线程提供了高层的API,满足日常开发中的常见需求
Lock接口 :
ReentrantLock类
ReadLock类
WriteLock类
Condition接口,Lock接口代替了synchronized,Condition接口替代了object的wait、nofity
synchronized和Lock的差别
Lock有比synchronized更精确的线程语义和更好的性能。synchronized会自动释放锁,而Lock一定要求程序员手工释放,并且必须在finally从句中释放 - 线程池
由于频繁的创建、销毁线程会降低系统的性能,因此使用线程池来管理线程,使得线程可以重复利用,执行完一个任务并不被销毁,可以继续执行其他任务
核心类:ThreadPoolExecutor
属性:coreThreadSize核心线程数、 maxinumThreadSize最大线程数、keepAliveTime线程池线程数大于核心线程数时,空闲线程的存活时间 workQueue阻塞队列用来存储等待执行的任务,handler拒绝处理任务时的策略。threadFactory线程工厂,主要用来创建线程。还有其他属性
方法:execute()向线程池提交一个任务,交给线程池去处理;submit()也是提交任务,但是能返回任务执行的结果;shutdown()关闭线程池,不接受新任务,等待正在执行的线程完成;shutdownNow()关闭线程池,不接受新任务,终止正在执行的线程
工作原理:
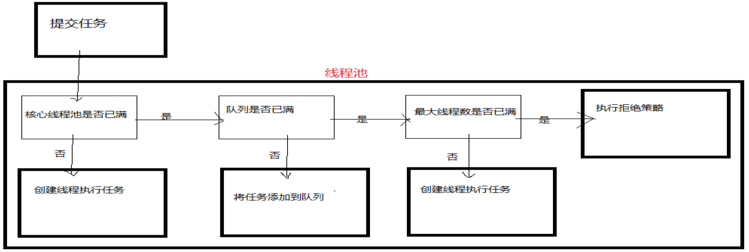
一个任务到来之后,查看线程池中线程数目,如果小于核心线程数,就创建线程执行任务,如果大于核心线程数,就再看工作队列是否满,不满就把任务添加到工作队列,如果工作队列也满了,就查看池中线程数是否小于最大线程数,如果小于,就创建线程执行任务,如果已经等于了最大线程数,就执行拒绝策略![]()
- 数组
保存相同类型的数据,定义的时候要指定长度,而且是固定的,有length属性 - 集合
长度可以动态增长
List 有序、可重复;可通过下标和迭代器遍历
ArrayList 底层数组实现,方法不同步,非线程安全,查询快,增删慢
LinkedList 底层双向链表实现,方法不同步,非线程安全,查询慢,增删快
Vector 底层数组实现,方法同步,线程安全
Set 无序、不可重复;没下标,只能通过迭代器遍历;加入Set的Object类型的元素要实现equals和hashCode方法
HashSet 底层基于哈希算法的哈希表实现,性能优于TreeSet,需要排序时用TreeSet;可以有一个null
TreeSet 底层二叉树实现,自动排好序的,不允许null
Map 是一个接口,并不继承Collection;键值;key不重复
HashMap 继承自AbstractMap类;底层哈希算法的哈希表实现,内部维护单链表;对key要重写equals和hashCode方法,非线程安全;key value都可以为null
LinkedHashMap 内部维护一个双向链表,有序,非线程安全
HashTable 继承自Dictionary类;,线程安全,key value都不能为null
如何选择
需要有序存储:List
保证唯一性:Set
以键值存储:Map
三、常用API
- Object
toString() 返回对象的字符串表示
equals()两个引用是否指向统一个对象,等价于==
hashCode() 两个引用指向同一个对象,即equals()为true,哈希码值就相同;指向不同的对象,哈希码就不同 - String
重写了equals()方法,用于比较内容是否相同,hashcode()也重写了,即使哈希码相同,也可能是不同对象
StringBuffer线程安全
StringBuilder非线程安全,但速度比前者快
String常用方法:
toCharArray()将字符串转换为字符数组 - 日期
Date 获得日期
SimpleDateFormat 指定格式 日期转为字符串:format(dat);字符串转为日期:parse(str)
Calendar 单例,通过getInstance()获得; calendar.setTime(new Date());初始化;format(calendar.getTime())//格式化;calender.get(Calendar.YEAR)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号