RabbitMQ 第八课 RabbitMQ集群架构模式
一 主备模式 Warren(兔子窝)
实现RabbitMQ的多个节点中实现高可用集群,一般在并发和数据量不高的情况下,这种模型非常的好用且简单。主备模式也称之为Warren(兔子窝)模式
特点:主节点提供读写,备用节点不提供任何读写的,只用来实现当主节点宕机的情况下能顶上去。(主从模式:主节点提供读写,从节点只读。)

HaProxy配置
listen rabbitmq_cluster bind 0.0.0.0:5672 # 配置TCP模式 mode tcp #简单的轮询 balance roundrobin # 主节点 server bhz76 192.168.11.76:5672 check inter 5000 rise 2 fall 2 server bhz76 192.168.11.77:5672 backup check inter 5000 rise 2 fall 2 # 备用节点 备注:rabbitmq集群节点配置 #inter每隔5秒对mq集群做健康检查,2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制
二 远程模式(Shovel)
(这种方式比较早了,已经有更好的替代方式了)
远程模式是可以实现双活的一种模式,简称Shovel模式,所谓Shovel就是我们可以把消息进行不同数据中心的复制工作,我们可以跨地域的让两个mq集群互联
远距离通信和复制,所谓Shovel就是 我们可以把消息进行不同数据中心的复制工作,我们可以跨地域的让两个mq集群互联。
Shovel架构模型:

Shovel集群的拓扑图:
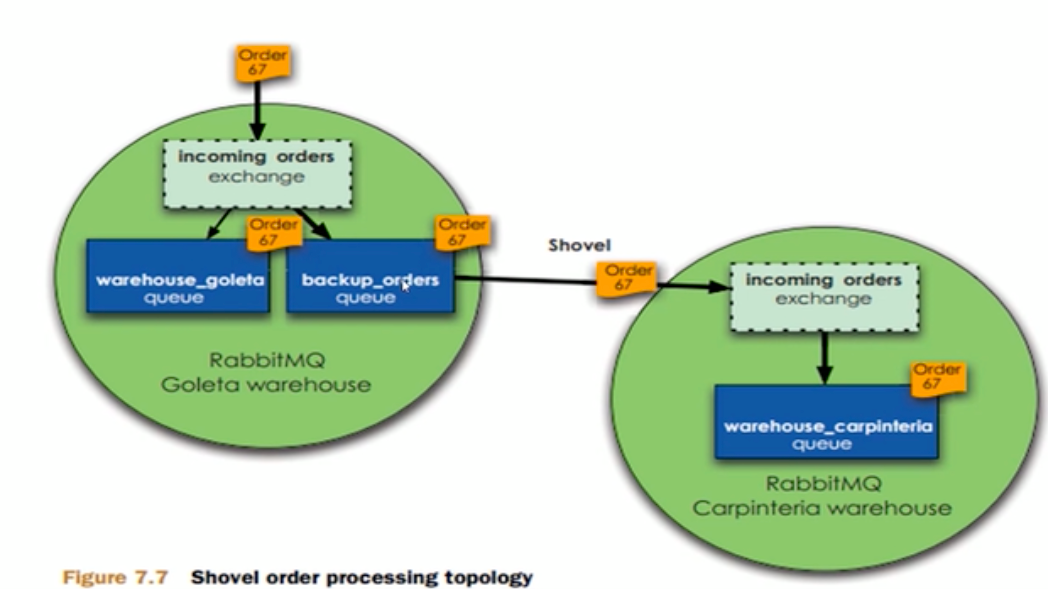
Shovel集群的配置,首先启动Rabbitmq插件,命令如下:
rabbitmq-plugins enable amqp_client rabbitmq-plugins enable amqp_shovel 创建rabbitmq.config文件:touch /etc/rabbitmq/rabbitmq.config 添加配置见rabbitmq.config 租后我们需要原服务器和目的地服务器都使用相同的配置文件(rabbitmq.config)

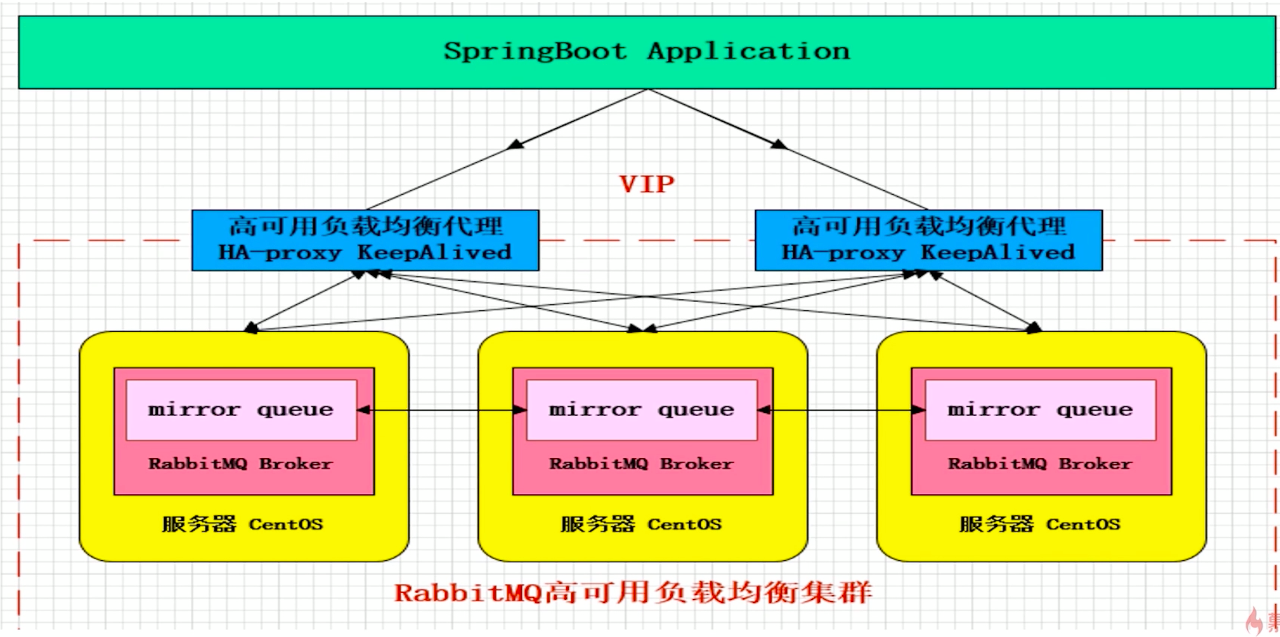
三、镜像模式(实际用)
集群模式非常经典的就是Mirror镜像模式,保证100%数据不丢失,在实际工作中也是用的最多的。并且实现集群非常的简单,一般互联网大厂都会构建这种镜像集群模式。
Mirror镜像队列:目的是为了保证rabbitmq数据的高可靠性解决方案,主要就是实现数据的同步,一般来讲是2-3个节点实现数据同步(对于100%数据可靠性解决方案一般是3节点),集群架构如下:
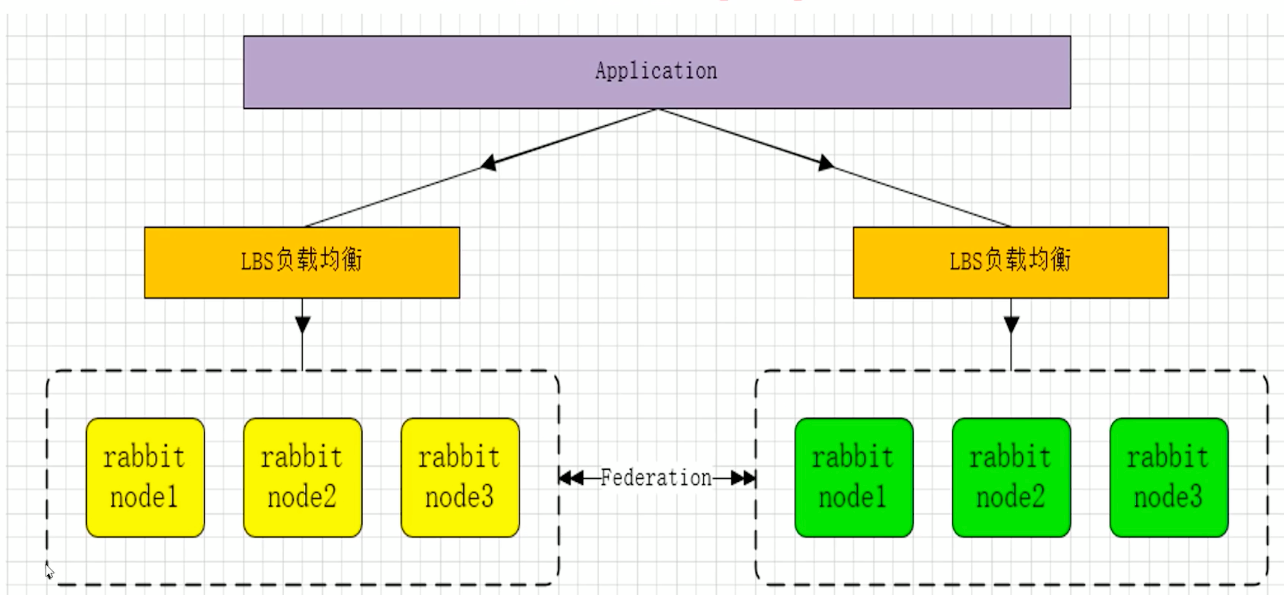
四、多活模式
这种模式也是实现异地数据复制的主流模式,因为Shovel模式配置比较复杂,所以一般来说实现异地集群都是使用这种双活或者多活模式来去实现的。这种模型需要依赖Rabbitmq的federation插件,可以实现持续的可靠的AMQP数据通信,多活模式在实际配置与应用非常简单。
RabbitMQ部署架构采用双中心模式(多中心),那么在两套(或多套)数据中心各部署一套RabbitMQ集群,各个中心的RabbitMQ服务除了需要为业务提供正常的消息服务外,中心之间还需要实现部分队列消息共享。可以避免一个集群挂掉,整个系统就挂掉了。多活集群架构如下:
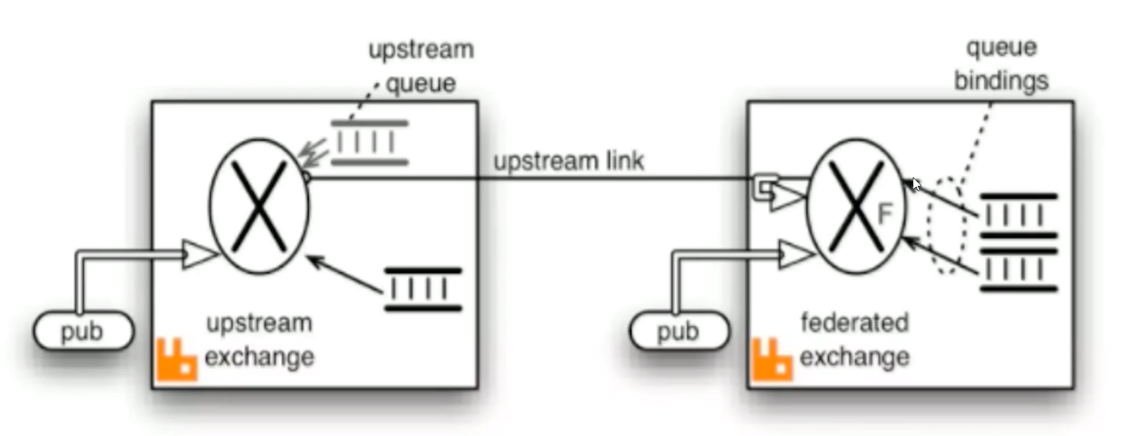
Federation插件
是一个不需要构建Cluster,而在Brokers之间传输消息的高性能插件,Federation插件可以在Brokers或者Couster之间传输消息,连接的双方可以使用不同的users和Virtual hosts,双方也可以使用版本不同的RabbitMQ和Erlang。Federation插件使用AMQP协议通讯,可以接受不连续的传输。
Federation Exchanges,可以看出DownStream从Upstream主动拉取消息,但并不是拉取所有消息,必须在Downstream上已经明确定义Bings关系的Exchange,也就是有实际的物理Queue来接收消息,才会从Upstream拉取消息到Downstream。使用AMQP协议实施代理间通信,Downstream会将绑定消息组合在一起,绑定/解除绑定命令将发送到Upstream交换机。因此,Federation Exchange 只接收具有订阅的消息,本处贴出官方图来说明:

1 基础知识
1.1 集群总体概述
Rabbitmq Broker集群是多个erlang节点的逻辑组,每个节点运行Rabbitmq应用,他们之间共享用户、虚拟主机、队列、exchange、绑定和运行时参数。
1.2 集群复制信息
除了message queue(存在一个节点,从其他节点都可见、访问该队列,要实现queue的复制就需要做queue的HA)之外,任何一个Rabbitmq broker上的所有操作的data和state都会在所有的节点之间进行复制。
1.3 集群运行前提
1、集群所有节点必须运行相同的erlang及Rabbitmq版本。
2、hostname解析,节点之间通过域名相互通信,本文为3个node的集群,采用配置hosts的形式。
1.4 集群互通方式
1、集群所有节点必须运行相同的erlang及Rabbitmq版本hostname解析,节点之间通过域名相互通信,本文为3个node的集群,采用配置hosts的形式。
1.5 端口及其用途
1、5672 客户端连接端口。
2、15672 web管控台端口。
3、25672 集群通信端口。
1.6 集群配置方式
通过rabbitmqctl手工配置的方式。
1.7 集群故障处理
1、rabbitmq broker集群允许个体节点宕机。
2、对应集群的的网络分区问题(network partitions)集群推荐用于LAN环境,不适用WAN环境;要通过WAN连接broker,Shovel or Federation插件是最佳解决方案(Shovel or Federation不同于集群:注Shovel为中心服务远程异步复制机制,稍后会有介绍)。
1.8 节点运行模式
为保证数据持久性,目前所有node节点跑在disk模式,如果今后压力大,需要提高性能,考虑采用ram模式。
1.9 集群认证方式
通过Erlang Cookie,相当于共享秘钥的概念,长度任意,只要所有节点都一致即可。rabbitmq server在启动的时候,erlang VM会自动创建一个随机的cookie文件。cookie文件的位置: /var/lib/rabbitmq/.erlang.cookie 或者/root/.erlang.cookie。我们的为保证cookie的完全一致,采用从一个节点copy的方式,实现各个节点的cookie文件一致。
1 集群搭建
1.1 集群节点安装
1、安装依赖包
PS:安装rabbitmq所需要的依赖包
yum install build-essential openssl openssl-devel unixODBC unixODBC-devel make gcc gcc-c++ kernel-devel m4 ncurses-devel tk tc xz
2、下载安装包
wget www.rabbitmq.com/releases/erlang/erlang-18.3-1.el7.centos.x86_64.rpm wget http://repo.iotti.biz/CentOS/7/x86_64/socat-1.7.3.2-5.el7.lux.x86_64.rpm wget www.rabbitmq.com/releases/rabbitmq-server/v3.6.5/rabbitmq-server-3.6.5-1.noarch.rpm
3、安装服务命令
rpm -ivh erlang-18.3-1.el7.centos.x86_64.rpm rpm -ivh socat-1.7.3.2-5.el7.lux.x86_64.rpm rpm -ivh rabbitmq-server-3.6.5-1.noarch.rpm
4、修改集群用户与连接心跳检测
注意修改vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/ebin/rabbit.app文件 修改:loopback_users 中的 <<"guest">>,只保留guest 修改:heartbeat 为1
5、安装管理插件
//首先启动服务 /etc/init.d/rabbitmq-server start stop status restart //查看服务有没有启动: lsof -i:5672 rabbitmq-plugins enable rabbitmq_management //可查看管理端口有没有启动: lsof -i:15672 或者 netstat -tnlp|grep 15672
6、服务指令
/etc/init.d/rabbitmq-server start stop status restart 验证单个节点是否安装成功:http://192.168.11.71:15672/ Ps:以上操作三个节点(71、72、73)同时进行操作
PS:选择76、77、78任意一个节点为Master(这里选择76为Master),也就是说我们需要把76的Cookie文件同步到77、78节点上去,进入/var/lib/rabbitmq目录下,把/var/lib/rabbitmq/.erlang.cookie文件的权限修改为777,原来是400;然后把.erlang.cookie文件copy到各个节点下;最后把所有cookie文件权限还原为400即可。
1.2 文件同步步骤
/etc/init.d/rabbitmq-server stop //进入目录修改权限;远程copy77、78节点,比如: scp /var/lib/rabbitmq/.erlang.cookie 到192.168.11.77和192.168.11.78中
1.3 组成集群步骤
1、停止MQ服务
PS:我们首先停止3个节点的服务
rabbitmqctl stop
PS:接下来我们就可以使用集群命令,配置76、77、78为集群模式,3个节点(76、77、78)执行启动命令,后续启动集群使用此命令即可。2、组成集群操作
rabbitmq-server -detached
3、slave加入集群操作(重新加入集群也是如此,以最开始的主节点为加入节点)
//注意做这个步骤的时候:需要配置/etc/hosts 必须相互能够寻址到 bhz77:rabbitmqctl stop_app bhz77:rabbitmqctl join_cluster --ram rabbit@bhz76 bhz77:rabbitmqctl start_app bhz78:rabbitmqctl stop_app bhz78:rabbitmqctl join_cluster rabbit@bhz76 bhz78:rabbitmqctl start_app //在另外其他节点上操作要移除的集群节点 rabbitmqctl forget_cluster_node rabbit@bhz24
4、修改集群名称
PS:修改集群名称(默认为第一个node名称):
rabbitmqctl set_cluster_name rabbitmq_cluster1
5、查看集群状态
PS:最后在集群的任意一个节点执行命令:查看集群状态
rabbitmqctl cluster_status
PS: 访问任意一个管控台节点:http://192.168.11.71:15672 如图所示6、管控台界面
1.4 配置镜像队列
PS:设置镜像队列策略(在任意一个节点上执行)
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
PS:将所有队列设置为镜像队列,即队列会被复制到各个节点,各个节点状态一致,RabbitMQ高可用集群就已经搭建好了,我们可以重启服务,查看其队列是否在从节点同步。
1.5 安装Ha-Proxy
1、Haproxy简介
HAProxy是一款提供高可用性、负载均衡以及基于TCP和HTTP应用的代理软件,HAProxy是完全免费的、借助HAProxy可以快速并且可靠的提供基于TCP和HTTP应用的代理解决方案。
HAProxy适用于那些负载较大的web站点,这些站点通常又需要会话保持或七层处理。
HAProxy可以支持数以万计的并发连接,并且HAProxy的运行模式使得它可以很简单安全的整合进架构中,同时可以保护web服务器不被暴露到网络上。
2、Haproxy安装
PS:79、80节点同时安装Haproxy,下面步骤统一
//下载依赖包 yum install gcc vim wget //下载haproxy wget http://www.haproxy.org/download/1.6/src/haproxy-1.6.5.tar.gz //解压 tar -zxvf haproxy-1.6.5.tar.gz -C /usr/local //进入目录、进行编译、安装 cd /usr/local/haproxy-1.6.5 make TARGET=linux31 PREFIX=/usr/local/haproxy make install PREFIX=/usr/local/haproxy mkdir /etc/haproxy //赋权 groupadd -r -g 149 haproxy useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy //创建haproxy配置文件 touch /etc/haproxy/haproxy.cfg
3、Haproxy配置文件haproxy.cfg详解
vim /etc/haproxy/haproxy.cfg
#logging options global log 127.0.0.1 local0 info maxconn 5120 chroot /usr/local/haproxy uid 99 gid 99 daemon quiet nbproc 20 pidfile /var/run/haproxy.pid defaults log global #使用4层代理模式,”mode http”为7层代理模式 mode tcp #if you set mode to tcp,then you nust change tcplog into httplog option tcplog option dontlognull retries 3 option redispatch maxconn 2000 contimeout 5s ##客户端空闲超时时间为 60秒 则HA 发起重连机制 clitimeout 60s ##服务器端链接超时时间为 15秒 则HA 发起重连机制 srvtimeout 15s #front-end IP for consumers and producters listen rabbitmq_cluster bind 0.0.0.0:5672 #配置TCP模式 mode tcp #balance url_param userid #balance url_param session_id check_post 64 #balance hdr(User-Agent) #balance hdr(host) #balance hdr(Host) use_domain_only #balance rdp-cookie #balance leastconn #balance source //ip #简单的轮询 balance roundrobin #rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查, 2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制 server bhz76 192.168.11.76:5672 check inter 5000 rise 2 fall 2 server bhz77 192.168.11.77:5672 check inter 5000 rise 2 fall 2 server bhz78 192.168.11.78:5672 check inter 5000 rise 2 fall 2 #配置haproxy web监控,查看统计信息 listen stats bind 192.168.11.79:8100 mode http option httplog stats enable #设置haproxy监控地址为http://localhost:8100/rabbitmq-stats stats uri /rabbitmq-stats stats refresh 5s
4、启动haproxy
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg //查看haproxy进程状态 ps -ef | grep haproxy
5、访问haproxy
PS:访问如下地址可以对rmq节点进行监控:http://192.168.1.27:8100/rabbitmq-stats
6、关闭haproxy
killall haproxy ps -ef | grep haproxy
1.6 安装KeepAlived
1、Keepalived简介
Keepalived,它是一个高性能的服务器高可用或热备解决方案,Keepalived主要来防止服务器单点故障的发生问题,可以通过其与Nginx、Haproxy等反向代理的负载均衡服务器配合实现web服务端的高可用。Keepalived以VRRP协议为实现基础,用VRRP协议来实现高可用性(HA).VRRP(Virtual Router Redundancy Protocol)协议是用于实现路由器冗余的协议,VRRP协议将两台或多台路由器设备虚拟成一个设备,对外提供虚拟路由器IP(一个或多个)。
2、Keepalived安装
PS:下载地址:http://www.keepalived.org/download.html
//安装所需软件包 yum install -y openssl openssl-devel //下载 wget http://www.keepalived.org/software/keepalived-1.2.18.tar.gz //解压、编译、安装 tar -zxvf keepalived-1.2.18.tar.gz -C /usr/local/ cd keepalived-1.2.18/ && ./configure --prefix=/usr/local/keepalived make && make install //将keepalived安装成Linux系统服务,因为没有使用keepalived的默认安装路径(默认路径:/usr/local),安装完成之后,需要做一些修改工作 //首先创建文件夹,将keepalived配置文件进行复制: mkdir /etc/keepalived cp /usr/local/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/ //然后复制keepalived脚本文件: cp /usr/local/keepalived/etc/rc.d/init.d/keepalived /etc/init.d/ cp /usr/local/keepalived/etc/sysconfig/keepalived /etc/sysconfig/ ln -s /usr/local/sbin/keepalived /usr/sbin/ ln -s /usr/local/keepalived/sbin/keepalived /sbin/ //可以设置开机启动:chkconfig keepalived on,到此我们安装完毕! chkconfig keepalived on
3、Keepalived配置
PS:修改keepalived.conf配置文件
vim /etc/keepalived/keepalived.conf
PS: 79节点(Master)配置如下
! Configuration File for keepalived global_defs { router_id bhz79 ##标识节点的字符串,通常为hostname } vrrp_script chk_haproxy { script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置 interval 2 ##检测时间间隔 weight -20 ##如果条件成立则权重减20 } vrrp_instance VI_1 { state MASTER ## 主节点为MASTER,备份节点为BACKUP interface eth0 ## 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同(我这里是eth0) virtual_router_id 79 ## 虚拟路由ID号(主备节点一定要相同) mcast_src_ip 192.168.11.79 ## 本机ip地址 priority 100 ##优先级配置(0-254的值) nopreempt advert_int 1 ## 组播信息发送间隔,俩个节点必须配置一致,默认1s authentication { ## 认证匹配 auth_type PASS auth_pass bhz } track_script { chk_haproxy } virtual_ipaddress { 192.168.11.70 ## 虚拟ip,可以指定多个 } }
PS: 80节点(backup)配置如下
! Configuration File for keepalived global_defs { router_id bhz80 ##标识节点的字符串,通常为hostname } vrrp_script chk_haproxy { script "/etc/keepalived/haproxy_check.sh" ##执行脚本位置 interval 2 ##检测时间间隔 weight -20 ##如果条件成立则权重减20 } vrrp_instance VI_1 { state BACKUP ## 主节点为MASTER,备份节点为BACKUP interface eno16777736 ## 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同(我这里是eno16777736) virtual_router_id 79 ## 虚拟路由ID号(主备节点一定要相同) mcast_src_ip 192.168.11.80 ## 本机ip地址 priority 90 ##优先级配置(0-254的值) nopreempt advert_int 1 ## 组播信息发送间隔,俩个节点必须配置一致,默认1s authentication { ## 认证匹配 auth_type PASS auth_pass bhz } track_script { chk_haproxy } virtual_ipaddress { 192.168.1.70 ## 虚拟ip,可以指定多个 } }
4、执行脚本编写
PS:添加文件位置为/etc/keepalived/haproxy_check.sh(79、80两个节点文件内容一致即可)
#!/bin/bash COUNT=`ps -C haproxy --no-header |wc -l` if [ $COUNT -eq 0 ];then /usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg sleep 2 if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then killall keepalived fi fi
5、执行脚本赋权
PS:haproxy_check.sh脚本授权,赋予可执行权限.
chmod +x /etc/keepalived/haproxy_check.sh
6、启动keepalived
PS:当我们启动俩个haproxy节点以后,我们可以启动keepalived服务程序:
//启动两台机器的keepalived service keepalived start | stop | status | restart //查看状态 ps -ef | grep haproxy ps -ef | grep keepalived
7、高可用测试
PS:vip在27节点上
PS:27节点宕机测试:停掉27的keepalived服务即可。
PS:查看28节点状态:我们发现VIP漂移到了28节点上,那么28节点的haproxy可以继续对外提供服务!
1.7 集群配置文件
创建如下配置文件位于:/etc/rabbitmq目录下(这个目录需要自己创建)
环境变量配置文件:rabbitmq-env.conf
配置信息配置文件:rabbitmq.config(可以不创建和配置,修改)
rabbitmq-env.conf配置文件:
---------------------------------------关键参数配置-------------------------------------------
RABBITMQ_NODE_IP_ADDRESS=本机IP地址 RABBITMQ_NODE_PORT=5672 RABBITMQ_LOG_BASE=/var/lib/rabbitmq/log RABBITMQ_MNESIA_BASE=/var/lib/rabbitmq/mnesia # 配置参考参数如下: RABBITMQ_NODENAME=FZTEC-240088 节点名称 RABBITMQ_NODE_IP_ADDRESS=127.0.0.1 监听IP RABBITMQ_NODE_PORT=5672 监听端口 RABBITMQ_LOG_BASE=/data/rabbitmq/log 日志目录 RABBITMQ_PLUGINS_DIR=/data/rabbitmq/plugins 插件目录 RABBITMQ_MNESIA_BASE=/data/rabbitmq/mnesia 后端存储目录
更详细的配置参见: http://www.rabbitmq.com/configure.html#configuration-file
配置文件信息修改:
/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.4/ebin/rabbit.app和rabbitmq.config配置文件配置任意一个即可,我们进行配置如下:
vim /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.4/ebin/rabbit.app
# -------------------------------------关键参数配置---------------------------------------- tcp_listerners 设置rabbimq的监听端口,默认为[5672]。 disk_free_limit 磁盘低水位线,若磁盘容量低于指定值则停止接收数据,默认值为{mem_relative, 1.0},即与内存相关联1:1,也可定制为多少byte. vm_memory_high_watermark,设置内存低水位线,若低于该水位线,则开启流控机制,默认值是0.4,即内存总量的40%。 hipe_compile 将部分rabbimq代码用High Performance Erlang compiler编译,可提升性能,该参数是实验性,若出现erlang vm segfaults,应关掉。 force_fine_statistics, 该参数属于rabbimq_management,若为true则进行精细化的统计,但会影响性能 #------------------------------------------------------------------------------------------
更详细的配置参见:http://www.rabbitmq.com/configure.html
