
Netty源码细节-accept、read(Linux os层 + Netty层代码细节)(转)
原文:http://budairenqin.iteye.com/blog/2215899
这篇分析一下accept的细节, 我觉得网络IO相关开发很多时候不能仅仅局限于java层, 尤其从accept开始一个连接诞生了, 什么拥塞控制啊, 滑动窗口啊等等一系列底层的问题可能就开始会渐渐困扰到你了, 这一章尝试先从linux内核的tcp实现开始分析accept
源码来自linux-2.6.11.12, 还参考了[TCP_IP.Architecture,.Design.and.Implementation.in.Linux]一书
accept概述
accept属于tcp被动打开环节(被动打开请参考tcp状态变迁图), 被动打开的前提是你这一端listen, listen时创建了一个监听套接字, 专门负责监听, 不负责传输数据.
当一个SYN到达服务器时, linux内核并不会创建sock结构体, 只是创建一个轻量级的request_sock结构体,里面能唯一确定是哪一个客户端发来的SYN的信息.
接着服务端发送SYN + ACK给客户端, 总结下来是两个步骤:
1.建立request_sock
2.回复SYN + ACK
接着客户端需要回复ACK, 此时服务端从ACK这个包中取出相应信息去查找之前相同客户端发过来的SYN时候创建的request_sock结构体, 到这里内核才会为这条连接创建真正的重量级sock结构体.
但是sock还只是socket的子集(socket结构体中有一个指针sock * sk), 此时一条连接至少还需要绑定一个fd(文件描述符)才能传输数据, accept系统调用后将绑定一个fd.
accept流程图:
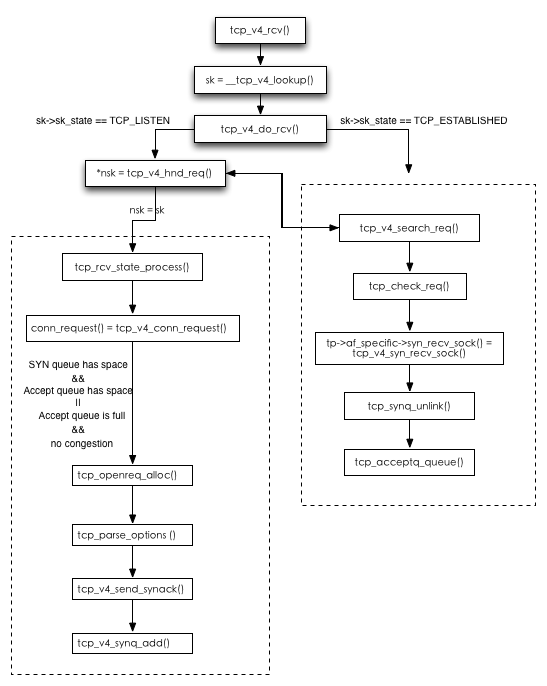
1.tcp_v4_rcv()是传输层报文处理入口, 主要做以下事情:
a)从报文中获取TCP头部数据, 验证TCP首部检验和
b)根据TCP首部中的信息来设置TCP控制块中的值,这里要进行字节序的转换
c)接着会调用__tcp_v4_lookup()
2.__tcp_v4_lookup()用来查找传输控制块sk, 如果未找到则直接给对端发RST(我们java层常看到的connection reset by peer就是RST导致, 很多情况下会给对端发送RST,找不到sk只是RST众多导火索中的一个).
3.接着检查第二步中找到的传输控制块sk, 如果进程没有访问sk, 会接着调用tcp_v4_do_rcv()来正常接收, tcp_v4_do_rcv()是传输层处理TCP段的主入口
4.如果sk->sk_state == TCP_LISTEN, 代表是监听套接字, 则应该处理被动连接(注意下accept的连接就是被动连接)
5.sock *nsk = tcp_v4_hnd_req(sk, skb);
tcp_v4_hnd_req()处理半连接状态的ACK消息, 这里分两种情况:
1)tcp_v4_hnd_req()直接返回了nsk并且nsk == sk(这代表现在是第一次握手), 此时沿着上图左边虚线框里的路径继续往下执行.
2)tcp_v4_hnd_req()里面调用tcp_v4_search_req()根据TCP四元组(源端口、源地址、目的地址)在父传输控制块的散列表中查找相应的连接请求块,
那说明两次握手已完成, 直接调用tcp_check_req()进行三次握手确认.
此时沿着右边虚线框执行.
**一.先分析左边第一条链路, 也就是处理SYN**
a)首先是tcp_rcv_state_process(), 除了ESTABLISHED和TIME_WAIT状态外,其他状态下的TCP段处理都由这个函数实现. 如果是处理SYN, 它会调用tcp_v4_conn_request()来处理.
b)tcp_v4_conn_request()函数里会做如下检查:
1)SYN queue是不是满了? 如果满了并且没有启用syncookie功能, 则直接丢弃连接
2)accept queue是不是满了?如果满了并且SYN请求队列中至少有一个握手过程中没有重传,则丢弃
c)通过了b)中的检查, 说明可以接收并处理请求, 调用tcp_openreq_alloc()先分配一个请求块.
d)接着调用tcp_parse_options()解析TCP段中的选项
e)然后初始化好连接请求块后就可以调用tcp_v4_send_synack()像客户端发送SYN + ACK了
f)最后调用tcp_v4_synq_add()将这个sk加入SYN queue中.
最后注意下其实sk只是一个轻量级的request_sock, 毕竟sock结构体比request_sock大的多, 犯不着三次握手都没建立起来我就建立一个大的结构体.
现在一个sock已经进入SYN queue, 目前的阶段是握手的第二步, 收到SYN并且回复对端SYN + ACK(希望你记得上一章我们讲backlog时提到过的两个队列, SYN queue就是其中一个)
**二.接下来第二条链路, 右边的虚线框**
a) tcp_v4_search_req()通过TCP四元组查到了对应的请求块, 说明两次握手已经完成, 进行第三次握手确认, 也就是处理ACK.
b)如果检查第三次握手的ACK段是有效的, 则调用tcp_v4_syn_recv_sock()创建子传输控制块.
c)tcp_v4_syn_recv_sock()方法里有很多初始化操作
1)创建子传输控制块,并进行初始化(这里是真正的重量级sock了)
2)设置路由缓存,确定输出网络接口的特性
3)根据路由中的路径MTU信息,设置控制块MSS
4)与本地端口进行绑定
最后会返回一个真正的重量级sock(注意区别前边提到的sk == request_sock)
d)接着调用tcp_synq_unlink()将sk从SYN queue中移除, 告别半连接身份
e)现在通过tcp_acceptq_queue()把这个重量级的sock加入的accept queue, 到此这个TCP连接已经可以被我们的应用层netty拿去玩了.
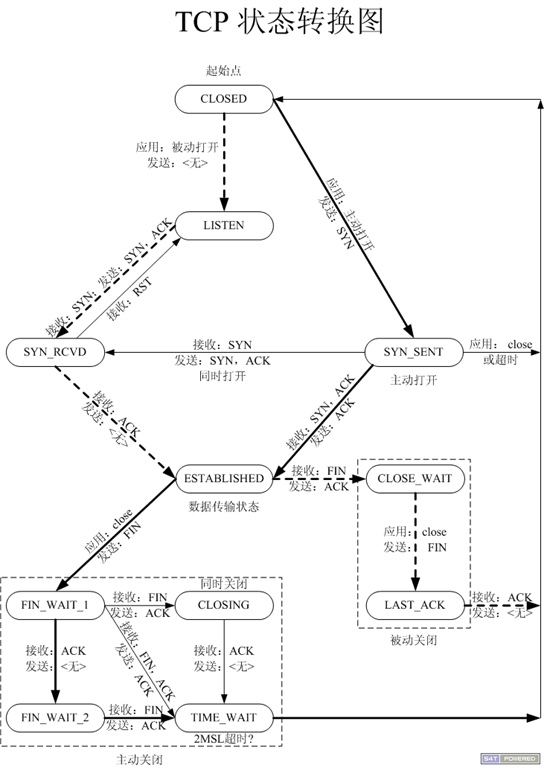
好吧, 我知道上面的文字中很多东西没有详细展开, 只关注java层的同学可能看着稍微吃力, 下面贴上两个图, 一个tcp三路握手, 一个tcp状态变迁图

第一个图来自耗子叔的[TCP那些事]http://coolshell.cn/articles/11564.html, 三次握手过程
第二个图在网上随便搜的, 来源不清楚了, 不过最终的源头肯定是[TCP/IP详解]一书了, 这是一个TCP状态变迁图,
我们上面分析的accept过程属于被动打开, 可以仔细对照图看一下.图中所有的TCP状态这里不解释了, 篇幅控制不住了,
大家参照[TCP/IP详解]一书.
现在铺垫完了, 开始分析netty的accept过程. 又要拿出第一章(EventLoop)的代码了, 多路复用IO的dispatch:
private static void processSelectedKey(SelectionKey k, AbstractNioChannel ch) { final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe(); // ...... try { int readyOps = k.readyOps(); // Also check for readOps of 0 to workaround possible JDK bug which may otherwise lead // to a spin loop if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) { unsafe.read(); if (!ch.isOpen()) { // Connection already closed - no need to handle write. return; } } if ((readyOps & SelectionKey.OP_WRITE) != 0) { // Call forceFlush which will also take care of clear the OP_WRITE once there is nothing left to write ch.unsafe().forceFlush(); } if ((readyOps & SelectionKey.OP_CONNECT) != 0) { // remove OP_CONNECT as otherwise Selector.select(..) will always return without blocking // See https://github.com/netty/netty/issues/924 int ops = k.interestOps(); ops &= ~SelectionKey.OP_CONNECT; k.interestOps(ops); unsafe.finishConnect(); } } catch (CancelledKeyException ignored) { unsafe.close(unsafe.voidPromise()); } }
以后分析read, write等逻辑是都要从这个代码开始, 现在我们只关心OP_ACCEPT, 由前两章的分析我们知道, 这里调用的是NioMessageUnsafe#read()
public void read() { // ...... final int maxMessagesPerRead = config.getMaxMessagesPerRead(); final ChannelPipeline pipeline = pipeline(); boolean closed = false; Throwable exception = null; try { try { for (;;) { int localRead = doReadMessages(readBuf); if (localRead == 0) { break; } if (localRead < 0) { closed = true; break; } // stop reading and remove op if (!config.isAutoRead()) { break; } if (readBuf.size() >= maxMessagesPerRead) { break; } } } catch (Throwable t) { exception = t; } setReadPending(false); int size = readBuf.size(); for (int i = 0; i < size; i ++) { pipeline.fireChannelRead(readBuf.get(i)); } readBuf.clear(); pipeline.fireChannelReadComplete(); if (exception != null) { if (exception instanceof IOException && !(exception instanceof PortUnreachableException)) { closed = !(AbstractNioMessageChannel.this instanceof ServerChannel); } pipeline.fireExceptionCaught(exception); } if (closed) { if (isOpen()) { close(voidPromise()); } } } finally { if (!config.isAutoRead() && !isReadPending()) { removeReadOp(); } } } }
1. maxMessagesPerRead的默认值在NioMessageUnsafe中为16, 尽可能的一次多accept些连接, 在os层我们提到了accept queue会满, 所以应用层越早拿走accept queue中的连接越好.
2. 接下来重头戏是doReadMessages
protected int doReadMessages(List<Object> buf) throws Exception { SocketChannel ch = javaChannel().accept(); try { if (ch != null) { buf.add(new NioSocketChannel(this, ch)); return 1; } } catch (Throwable ignored) {} return 0; }
a)javaChannel().accept()会通过accept系统调用从os的accept queue中拿出一个连接并包装成SocketChannel
b)接着又包装一层netty的NioSocketChannel之后放进buf中.
c)NioSocketChannel构造方法将SocketChannel感兴趣的事件设置成OP_READ, 并设置成非阻塞模式.
3. 我们回到unsafe#read()方法, 如果每次调用doReadMessages都能拿到一个channel, 那么一直拿到16个以上的channel再跳出循环, 原因在第一点中已经说了.
如果localRead == 0, 表示此时os 的 accept queue中可能已经没有就绪连接了, 所以也跳出循环.
4. 接下来触发channelRead event:
pipeline.fireChannelRead(readBuf.get(i));
channelRead是inbound event, 回想之前pipeline中的顺序(head-->
ServerBootstrapAcceptor-->tail),
会调用ServerBootstrapAcceptor的channelRead()
public void channelRead(ChannelHandlerContext ctx, Object msg) { final Channel child = (Channel) msg; child.pipeline().addLast(childHandler); // 设置child options, attrs try { childGroup.register(child).addListener(new ChannelFutureListener() { @Override public void operationComplete(ChannelFuture future) throws Exception { if (!future.isSuccess()) { forceClose(child, future.cause()); } } }); } catch (Throwable t) { forceClose(child, t); } }
前两篇开篇实例有如下代码:
b.childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) throws Exception { ChannelPipeline p = ch.pipeline(); p.addLast(new EchoServerHandler()); } });
1.child.pipeline().addLast(childHandler)就是将这里我们自己用户逻辑相关的handler加入到 channel 的pipeline里面(注意这是worker的pipeline, 前面提到的都是boss 的 pipeline)
2.设置child options, attrs
3.接下里从workerGroup中拿出一个workerEventLoop并将channel注册到其中, register()的逻辑和第二篇讲bind时bossEventLoop的注册基本是一样的, 这里我们不再重复讲了.
到这里, 一次accept流程, 就完成了, 现在这个channel就有workerEventLoop来处理读写等事件了.

