Sqlserver on linux 高可用集群搭建
一、环境准备
1 部署环境:
服务器数量:3台
Ip地址:192.168.1.191(主)
192.168.1.192(从)
192.168.1.193(从)
操作系统:CentOS Linux release 7.6.1810 (Core)
Cpu:2核
内存:4G
存储20GB
2 部署前准备工作:
2.1 关闭防火墙
Bash(all):
iptables -F
systemctl stop firewalld
systemctl disable firewalld
2.2 修改hosts文件
Bash(all):
vim /etc/hosts
192.168.1.191 m191
192.168.1.192 m192
192.168.1.193 m193
2.3 修改主机名
Bash(all):
Hostname m191
Hostname m191
Hostname m191
2.4 更新主机名
Bash(all):
bash
二、安装 SQL Server
1 安装mssql server:
1.1 下载 Microsoft SQL Server 2019 Red Hat 存储库配置文件:
sudo curl -o /etc/yum.repos.d/mssql-server.repo https://packages.microsoft.com/config/rhel/7/mssql-server-2019.repo
1.2 运行以下命令,安装 SQL Server:
sudo yum install -y mssql-server
程序包安装完成后,请运行 mssql-conf setup 命令并按提示设置 SA 密码,然后选择版本(我选择的是6)。
sudo /opt/mssql/bin/mssql-conf setup
请确保为 SA 帐户指定强密码(最少 8 个字符,包括大写和小写字母、十进制数字和/或非字母数字符号)。
1.3 配置完成后,请验证服务是否正在运行:
systemctl status mssql-server
1.4 若要允许远程连接,请在 RHEL 上打开防火墙上的 SQL Server 端口。
默认的 SQL Server 端口为 TCP 1433。 如果对防火墙使用 FirewallD,可以使用以下命令:
sudo firewall-cmd --zone=public --add-port=1433/tcp --permanent
sudo firewall-cmd --reload
在此情况下,SQL Server 2019 RHEL 计算机上运行并已准备好使用 !
1.5启动 SQL Server 代理(默认已安装,没有可单独安装)
yum install mssql-server-agent
/opt/mssql/bin/mssql-conf set sqlagent.enabled true
2 安装 SQL Server 命令行工具
若要创建数据库,需要使用一个能够在 SQL Server 上运行 Transact-SQL 语句的工具进行连接。 以下步骤安装 SQL Server 命令行工具: sqlcmd和bcp。
2.1 下载 Microsoft Red Hat 存储库配置文件。
sudo curl -o /etc/yum.repos.d/msprod.repo https://packages.microsoft.com/config/rhel/7/prod.repo
2.2 如果你有旧版mssql 工具安装,请删除任何较旧的 unixODBC 包。
sudo yum remove unixODBC-utf16 unixODBC-utf16-devel
2.3 运行以下命令以安装 mssql-tools 和 unixODBC 开发人员包。
sudo yum install -y mssql-tools unixODBC-devel
2.4 将 /opt/mssql-tools/bin/ 添加到 PATH 环境变量。
这样就可以在运行工具时不指定完整路径。 请运行以下命令,以便修改登录会话和交互/非登录会话的 PATH:
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bash_profile
echo 'export PATH="$PATH:/opt/mssql-tools/bin"' >> ~/.bashrc
source ~/.bashrc
3 本地连接
3.1 以下步骤使用 sqlcmd 本地连接到新的 SQL Server 实例。
使用 SQL Server 名称 (-S),用户名 (-U) 和密码 (-P) 的参数运行 sqlcmd。 在本教程中,用户进行本地连接,因此服务器名称为 localhost。 用户名为 SA,密码是在安装过程中为 SA 帐户提供的密码。
bash复制
sqlcmd -S localhost -U SA -P '<YourPassword>'
提示
可以在命令行上省略密码,以收到密码输入提示。
提示
如果以后决定进行远程连接,请指定 -S 参数的计算机名称或 IP 地址,并确保防火墙上的端口 1433 已打开。
如果成功,应会显示 sqlcmd 命令提示符:1>。
如果连接失败,请首先尝试根据错误消息诊断问题。 。
3.2 创建和查询数据
下面各部分将逐步介绍如何使用 sqlcmd 新建数据库、添加数据并运行简单查询。
3.2.1 新建数据库
以下步骤创建一个名为 TestDB 的新数据库。
在 sqlcmd 命令提示符中,粘贴以下 Transact-SQL 命令以创建测试数据库:
SQL复制
CREATE DATABASE TestDB
在下一行中,编写一个查询以返回服务器上所有数据库的名称:
SQL复制
SELECT Name from sys.Databases
前两个命令没有立即执行。 必须在新行中键入 GO 才能执行以前的命令:
SQL复制
GO
3.3.2 插入数据
接下来创建一个新表 Inventory,然后插入两个新行。
在 sqlcmd 命令提示符中,将上下文切换到新的 TestDB 数据库:
SQL复制
USE TestDB
创建名为 Inventory 的新表:
SQL复制
CREATE TABLE Inventory (id INT, name NVARCHAR(50), quantity INT)
将数据插入新表:
SQL复制
INSERT INTO Inventory VALUES (1, 'banana', 150); INSERT INTO Inventory VALUES (2, 'orange', 154);
要执行上述命令的类型 GO:
SQL复制
GO
3.2.3 选择数据
现在,运行查询以从 Inventory 表返回数据。
通过 sqlcmd 命令提示符输入查询,以返回 Inventory 表中数量大于 152 的行:
SQL复制
SELECT * FROM Inventory WHERE quantity > 152;
执行命令:
SQL复制
GO
退出 sqlcmd 命令提示符
要结束 sqlcmd 会话,请键入 QUIT:
SQL复制
QUIT
三、SQL Server 证书及权限配置
Sql server版本:Microsoft SQL Server 2019 (CTP2.4) - 15.0.1400.75 (X64) Mar 16 2019 11:53:26 Copyright (C) 2019 Microsoft Corporation Enterprise Edition (64-bit) on Linux (CentOS Linux 7 (Core)) <X64>
1 激活Always On Availability Group功能
Bash(all):
sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1
sudo systemctl restart mssql-server
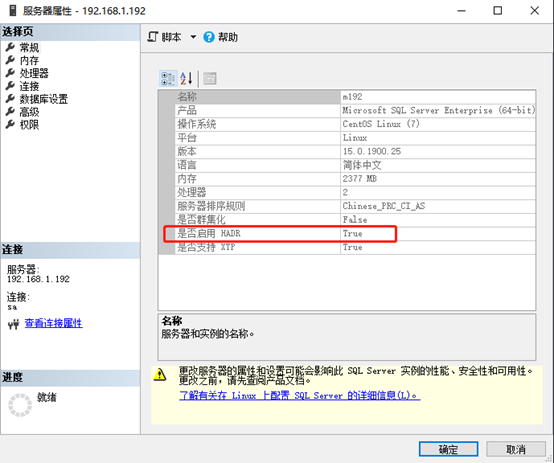
1.1所有服务器:为 SQL Server AlwaysOn AG 安装Linux资源代理
群集资源代理程序 mssql-server-ha 是 Pacemaker 和 SQL Server 之间的接口
Bash(all)
yum install -y mssql-server-ha
yum info mssql-server-ha
2 启用AlwaysOn_health事件会话
Sql(all):
ALTER EVENT SESSION AlwaysOn_health ON SERVER WITH (STARTUP_STATE=ON);
GO
3 在所有节点上创建书库镜像端点(endPoint)用户
(linux上需要创建一个登录名(login)为dbm_login和用户名(user)为dbm_user的用户,它专用于端点,注意使用强密码)
Sql(all):
CREATE LOGIN dbm_login WITH PASSWORD = '1111.aaa';
CREATE USER dbm_user FOR LOGIN dbm_login;
4 在主节点创建证书
Sql(主):
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '1111.aaa';
CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm';
BACKUP CERTIFICATE dbm_certificate
TO FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
ENCRYPTION BY PASSWORD = '1111.aaa'
);
4.1 此时,在主上面的数据目录下会产生两个文件:
Bash(主):
dbm_certificate.cer ##证书
dbm_certificate.pvk ##私钥

4.2 然后将这两个文件复制到所有从服务器上相同目录中
Bash(主):
cd /var/opt/mssql/data/
scp dbm_certificate.* 192.168.1.192:/var/opt/mssql/data/
scp dbm_certificate.* 192.168.1.193:/var/opt/mssql/data/

4.3 对从服务器上的证书进行授权
Bash(从);
cd /var/opt/mssql/data/
chown mssql.mssql dbm_certificate.*
5 在辅助节点上创建证书
Sql(从):
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '1111.aaa';
CREATE CERTIFICATE dbm_certificate
AUTHORIZATION dbm_user
FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer'
WITH PRIVATE KEY (
FILE = '/var/opt/mssql/data/dbm_certificate.pvk',
DECRYPTION BY PASSWORD = '1111.aaa'
);
6 创建数据库镜像端点
Sql(all);
CREATE ENDPOINT [Hadr_endpoint]
AS TCP (LISTENER_PORT = 5022)
FOR DATABASE_MIRRORING (
ROLE = ALL,
AUTHENTICATION = CERTIFICATE dbm_certificate,
ENCRYPTION = REQUIRED ALGORITHM AES
);
ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED;
GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login];
执行完毕之后在(all)上面查看是否启用了对应的端口并开放端口5022

sudo firewall-cmd --zone=public --add-port=5022/tcp --permanent
sudo firewall-cmd --reload
7 在主节点上创建AG
7.1 检查sqlserver主机名成
Sql(all);
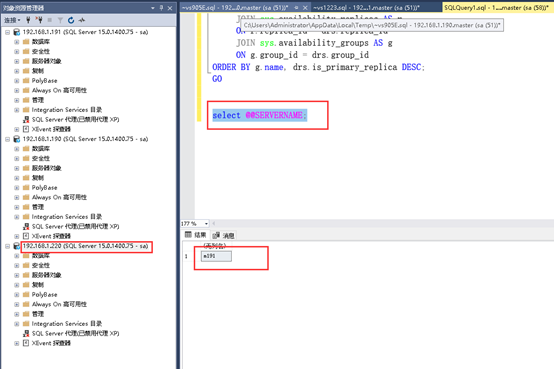
select @@SERVERNAME;
正确的话会显示:
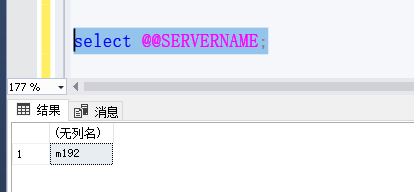
不正确的话用命令进行修改;
8.1.1 select * from Sys.SysServers; //查看所有系统名称
8.1.2 sp_dropserver 'localhost' //删除servername-localhost
8.1.3 sp_addserver 'm192','LOCAL' //修改主机名为m190、
修改完毕之后一定要重启sqlserver服务才会生效。
7.2 在主节点上创建AG
Sql(主):
CREATE AVAILABILITY GROUP [AG1]
WITH (DB_FAILOVER = ON, CLUSTER_TYPE = EXTERNAL)
FOR REPLICA ON
N'm191'
WITH (
ENDPOINT_URL = N'tcp://m192:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'm192'
WITH (
ENDPOINT_URL = N'tcp://m192:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
),
N'm193'
WITH (
ENDPOINT_URL = N'tcp://m193:5022',
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
FAILOVER_MODE = EXTERNAL,
SEEDING_MODE = AUTOMATIC,
SECONDARY_ROLE (ALLOW_CONNECTIONS = ALL)
);
ALTER AVAILABILITY GROUP [AG1] GRANT CREATE ANY DATABASE;
7.3 将从节点添加进去
Sql(从):
ALTER AVAILABILITY GROUP [AG1] JOIN WITH (CLUSTER_TYPE = EXTERNAL);
ALTER AVAILABILITY GROUP [AG1] GRANT CREATE ANY DATABASE
7.4 测试创建数据库db1
Sql(主):
CREATE DATABASE [db1];
ALTER DATABASE [db1] SET RECOVERY FULL;
BACKUP DATABASE [db1]
TO DISK = N'/var/opt/mssql/data/db1.bak';
ALTER AVAILABILITY GROUP [AG1] ADD DATABASE [db1];
7.5 在从节点上面再次点击db1,发现可以点开
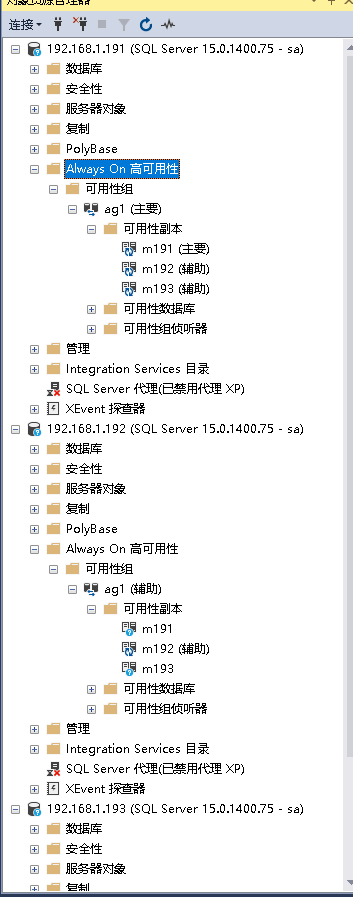
至此AG配置已经完成,但是塔仅同步并不能shi先真正的高可用,还需要进行故障转移,毕竟在企业中你不可能只管理一个数据库,下章《配置集群管理器Pacemaker》,是主推的高可用技术,AlwaysON当然也要提供一定的功能来实现这种“透明”切换,它提供了虚拟IP(vip)的感念。
7.6 AG操作
删除可用性组
DROP AVAILABILITY GROUP group_name
四、配置集群管理器Pacemaker
1 安装必备工具包
Red Hat Enterprise Linux (RHEL)
Bash(all)
- 使用以下语法注册服务器。 系统会提示输入有效的用户名和密码。
sudo subscription-manager register
列出可用的注册池。
sudo subscription-manager list –available
运行以下命令,将 RHEL 高可用性与订阅相关联
sudo subscription-manager attach --pool=<PoolID>
其中,“PoolId”是上一步中高可用性订阅的池 ID 。
使存储库能够使用高可用性加载项。
sudo subscription-manager repos --enable=rhel-ha-for-rhel-7-server-rpms
Bash(all):
yum install pacemaker pcs resource-agents corosync fence-agents-all -y
2 对所有节点配置公共密码
Bash(all):
passwd hacluster (这里密码一定要设置成一样的,我这设置的是123456.com)
3 启动相应服务
Bash(all):
sudo systemctl enable pcsd
sudo systemctl start pcsd
sudo systemctl enable pacemaker

3.1在所有群集节点上,打开 Pacemaker 防火墙端口。 若要使用 firewalld 打开这些端口,请运行以下命令:
firewall-cmd --add-service=high-availability --zone=public --permanent
firewall-cmd --zone=public --add-port=2224/tcp --permanent
firewall-cmd --zone=public --add-port=3121/tcp –permanent
firewall-cmd --zone=public --add-port=5405/udp --permanent
firewall-cmd --reload
4 创建集群
为防止集群中的异常文件残留,需要先删除已经存在的集群。
Bash(all):
sudo pcs cluster destroy
sudo systemctl enable pacemaker
创建对应的集群,此处需要一个节点(一般在主节点)运行
Bash(主):
sudo pcs cluster auth m191 m192 m193 -u hacluster -p 123456.com
sudo pcs cluster setup --name AG1 m191 m192 m193
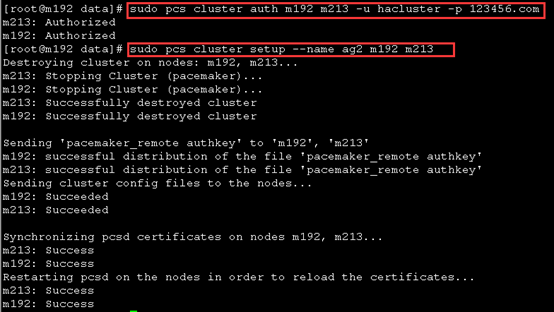
chown -R hacluster.haclient /var/log/cluster
pcs cluster start --all
pcs cluster enable –all
4.1查看当前集群状态:
pcs cluster status
4.2检查pacemaker服务:
ps aux | grep pacemaker
4.3检验Corosync的安装及当前corosync状态:
corosync-cfgtool -s
corosync-cmapctl | grep members
pcs status corosync
4.4检查配置是否正确(假若没有输出任何则配置正确):
crm_verify -L -V
4.5禁用STONITH(all):
pcs property set stonith-enabled=false
4.6无法仲裁时候,选择忽略(all):
pcs property set no-quorum-policy=ignore

5 所有节点隔离(STONITH)资源
隔离的目的是确保在配置资源过程中引起服务中断时,不会发生数据损坏,为了测试环境相对简单,需要禁用隔离,在实际环境中需要与管理员和设备供应商讨论是否需要启用。
Bash(all):
sudo pcs property set stonith-enabled=false
6 在所有节点安装资源包
Bash(all):
yum install mssql-server-ha –y
sudo systemctl restart mssql-server
7 设置群集属性群集重新检查间隔(可不配置)
cluster-recheck-interval 指示检查群集资源参数、 约束或其他群集选项中的更改的轮询间隔。 如果副本出现故障,群集将尝试重新启动的时间间隔,由绑定的副本failure-timeout值和cluster-recheck-interval值。 例如,如果failure-timeout设置为 60 秒和cluster-recheck-interval设置为 120 秒,在重新启动尝试的时间间隔大于 60 秒,但不超过 120 秒。 我们建议将故障超时设置为 60 秒和群集重新检查的间隔超过 60 秒的值。 不建议将群集重新检查间隔设置为较小的值。
若要将属性值更新为2 minutes运行:
sudo pcs property set cluster-recheck-interval=2min
(包括 RHEL 7.3 和 7.4) 的所有使用最新可用 Pacemaker 包 1.1.18-11.el7 分布引入开始失败-是的致命群集设置的行为更改其值为 false。 此更改会影响故障转移工作流。 如果主副本发生服务中断,群集应故障转移到其中一个可用的辅助副本。 相反,用户会注意到该群集会一直尝试启动失败的主副本。 如果该主永远不会处于联机状态 (由于的永久中断),群集永远不会故障转移到另一个可用的辅助副本。 由于此更改,以前推荐的配置来设置开始失败-是的致命将不再有效,需要恢复回其默认值设置true。 此外,需要更新,以包含 AG 资源failover-timeout属性。
若要将属性值更新为true运行:
sudo pcs property set start-failure-is-fatal=true
若要更新ag_cluster资源属性failure-timeout到60s运行:
pcs resource update AG1 meta failure-timeout=60s
8.1 在所有节点上创建基于Pacemaker的使用账户
Sql(all):
USE [master]
GO
CREATE LOGIN [pacemakerLogin] with PASSWORD= N'1111.aaa';
ALTER SERVER ROLE [sysadmin] ADD MEMBER [pacemakerLogin]
9 所有节点保存登陆信息
Bash(all):
sudo echo 'pacemakerLogin' >> ~/pacemaker-passwd
sudo echo '1111.aaa' >> ~/pacemaker-passwd
sudo mv ~/pacemaker-passwd /var/opt/mssql/secrets/passwd
sudo chown root:root /var/opt/mssql/secrets/passwd
sudo chmod 400 /var/opt/mssql/secrets/passwd [ge1]
10 搭建主节点配置AG,创建虚拟IP
搭建好集群之后,就可以创建虚拟Ip,这里选用192.168.1.220为VIP
Bash(主)
sudo pcs resource create ag_cluster ocf:mssql:ag ag_name=AG1 meta failure-timeout=60s master notify=true
sudo pcs resource create virtualip ocf:heartbeat:IPaddr2 ip=192.168.1.220
执行完之后查看是否绑定成功
ip addr show
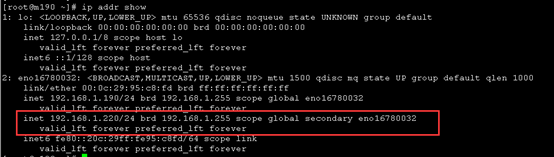
11 设置主节点(或副本)执行集群依赖关系和启动顺序
11.1目的在于当集群拥有两个以上的节点,且发生故障转移时,应选择哪一节点作为新的主节点。
11.1.1用户问题pcs resource move到可用性组主副本从节点 1 到节点 2。
11.1.2节点 1 上虚拟 IP 资源停止。
11.1.3节点 2 上虚拟 IP 资源启动。
此时,IP 地址暂时指向节点 2,同时节点 2 仍为故障转移前的次要副本。
11.1.4节点 1 上的可用性组主要副本降级为次要副本。
11.1.5节点 2 上的可用性组次要副本升级为主要副本。
Bash(主)
sudo pcs constraint colocation add virtualip ag_cluster-master INFINITY with-rsc-role=Master
sudo pcs constraint order promote ag_cluster-master then start virtualip

11.2 查看集群状态
sudo pcs status
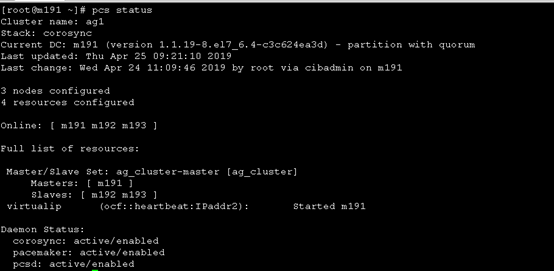
12 访问VIP
这次使用vip访问sqlserver服务器,一般情况下,1433端口可以不加(sa,密码123456.com)
如下图我们顺利完成了搭建,在无故障的情况下,当前DB(注意我们使用vip连接,也就是可能你不知道具体的主节点在哪里)如图;
Sql(VIP):
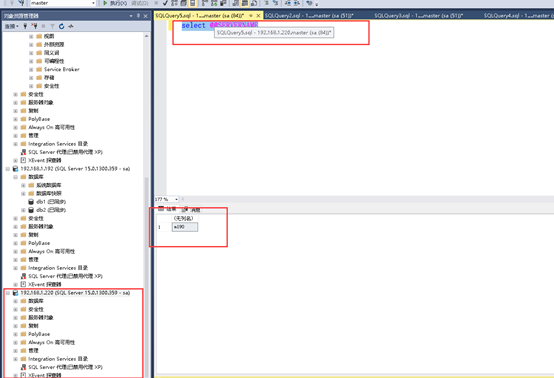
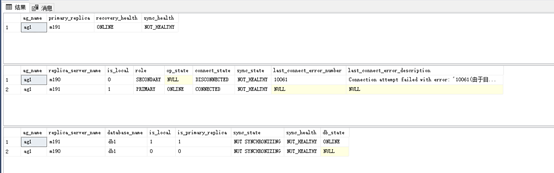
13 首先我们要了解当前状态,使用下面语句查看AG信息
Sql(VIP):
-- group info
SELECT
g.name as ag_name,
rgs.primary_replica,
rgs.primary_recovery_health_desc as recovery_health,
rgs.synchronization_health_desc as sync_health
From sys.dm_hadr_availability_group_states as rgs
JOIN sys.availability_groups AS g
ON rgs.group_id = g.group_id
--replicas info
SELECT
g.name as ag_name,
r.replica_server_name,
rs.is_local,
rs.role_desc as role,
rs.operational_state_desc as op_state,
rs.connected_state_desc as connect_state,
rs.synchronization_health_desc as sync_state,
rs.last_connect_error_number,
rs.last_connect_error_description
From sys.dm_hadr_availability_replica_states AS rs
JOIN sys.availability_replicas AS r
ON rs.replica_id = r.replica_id
JOIN sys.availability_groups AS g
ON g.group_id = r.group_id
--DB level
SElECT
g.name as ag_name,
r.replica_server_name,
DB_NAME(drs.database_id) as [database_name],
drs.is_local,
drs.is_primary_replica,
synchronization_state_desc as sync_state,
synchronization_health_desc as sync_health,
database_state_desc as db_state
FROM sys.dm_hadr_database_replica_states AS drs
JOIN sys.availability_replicas AS r
ON r.replica_id = drs.replica_id
JOIN sys.availability_groups AS g
ON g.group_id = drs.group_id
ORDER BY g.name, drs.is_primary_replica DESC;
GO
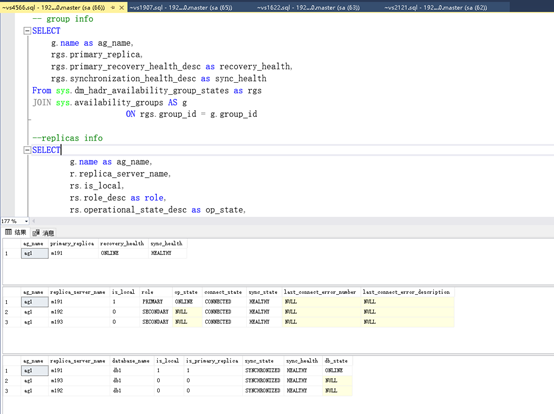
-
14 模拟故障转移
使用命令停掉主节点的sql server服务(我们期望它能发生自动故障转移,并且希望在本例中主节点能转移到m191或m192上面,同时又保证VIP能继续使用,等待少许时间后/故障转移需要一定的时间,特别是繁忙的大型系统,可能需要数秒到几分钟/)
14.1 故障转移(手动)
Sql(主):
将m192转换为主数据库
sudo pcs resource move ag_cluster-master m192 --master

14.2 查看vip地址是否可以漂移到m192上
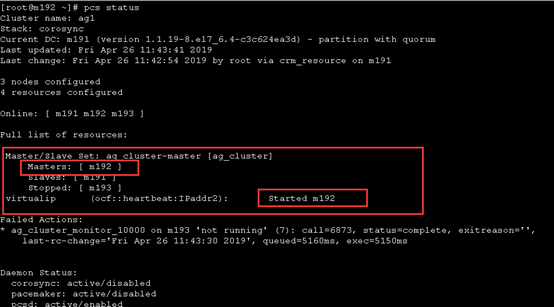
14.3 至此,集群模式搭建完成
[ge1] Only readable by root

 浙公网安备 33010602011771号
浙公网安备 33010602011771号