Dubbo:基本原理机制
“ 分布式应用场景有高并发,高可扩展和高性能的要求。还涉及到,序列化/反序列化,网络,多线程以及设计模式的问题。幸好 Dubbo 框架将上述知识进行了封装,让程序员能够把注意力放到业务上。
为了更好地了解和使用 Dubbo,今天来介绍一下 Dubbo 的主要组件和实现原理。
分布式服务框架:
- 高性能和透明化的RPC远程服务调用方案
- SOA服务治理方案
- Apache MINA 框架基于Reactor模型通信框架,基于tcp长连接
Dubbo缺省协议采用单一长连接和NIO异步通讯,适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
分析源代码,基本原理如下:
- client一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
- 将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
- 向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
- 将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
- 当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
- 服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
- 监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。
当前线程怎么让它“暂停”,等结果回来后,再向后执行?
答:先生成一个对象obj,在一个全局map里put(ID,obj)存放起来,再用synchronized获取obj锁,再调用obj.wait()让当前线程处于等待状态,然后另一消息监听线程等到服 务端结果来了后,再map.get(ID)找到obj,再用synchronized获取obj锁,再调用obj.notifyAll()唤醒前面处于等待状态的线程。
正如前面所说,Socket通信是一个全双工的方式,如果有多个线程同时进行远程方法调用,这时建立在client server之间的socket连接上会有很多双方发送的消息传递,前后顺序也可能是乱七八糟的,server处理完结果后,将结果消息发送给client,client收到很多消息,怎么知道哪个消息结果是原先哪个线程调用的?
答:使用一个ID,让其唯一,然后传递给服务端,再服务端又回传回来,这样就知道结果是原先哪个线程的了。
Dubbo 分层
Dubbo 是一款高性能 Java RPC 架构。它实现了面向接口代理的 RPC 调用,服务注册和发现,负载均衡,容错,扩展性等等功能。
Dubbo 大致上分为三层,分别是:
- 业务层
- RPC 层
- Remoting 层
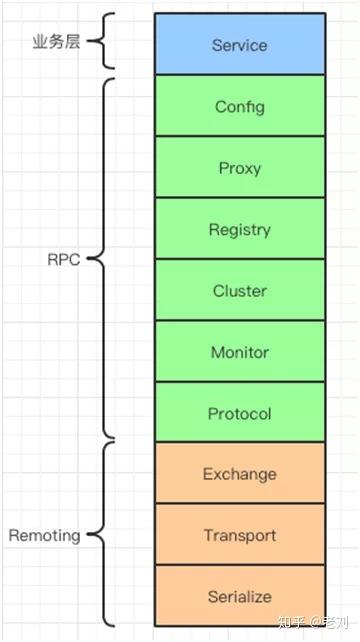 Dubbo 的三层结构
Dubbo 的三层结构
从上图中可以看到,三层结构中包含了 Dubbo 的核心组件。他们的基本功能如下,对于比较常用的组件,会在后面的篇幅中详细讲解。
组件功能列表
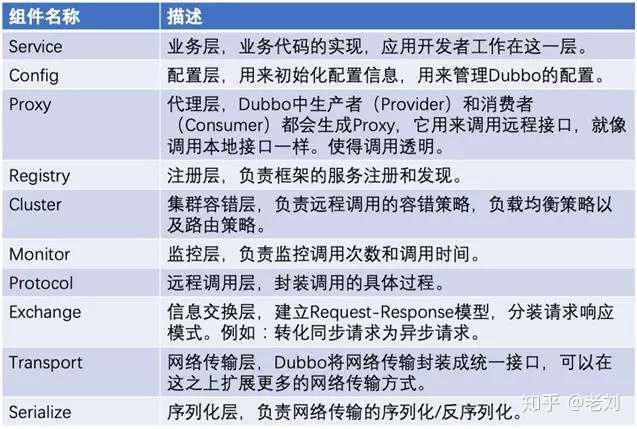
这里将这些组件罗列出来,能有一个感性的认识。具体开发的时候,知道运用哪些组件。
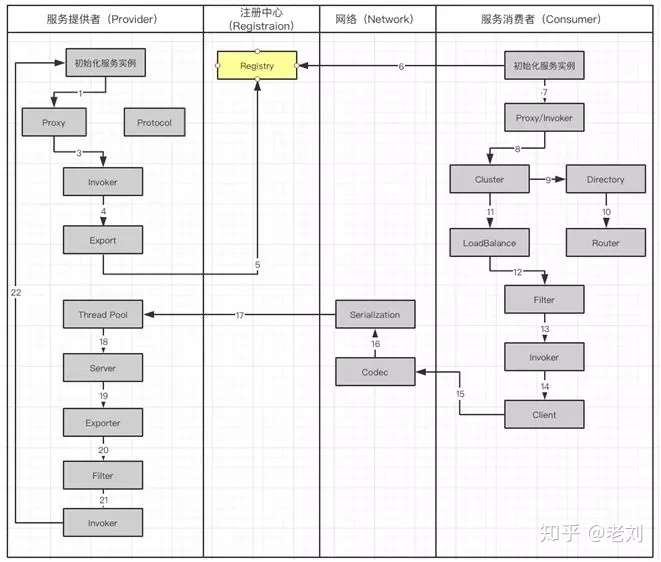
Dubbo 调用工作流
Dubbo 框架是用来处理分布式系统中,服务发现与注册以及调用问题的,并且管理调用过程。
上面介绍了 Dubbo 的框架分层,下图的工作流就展示了他们是如何工作的。
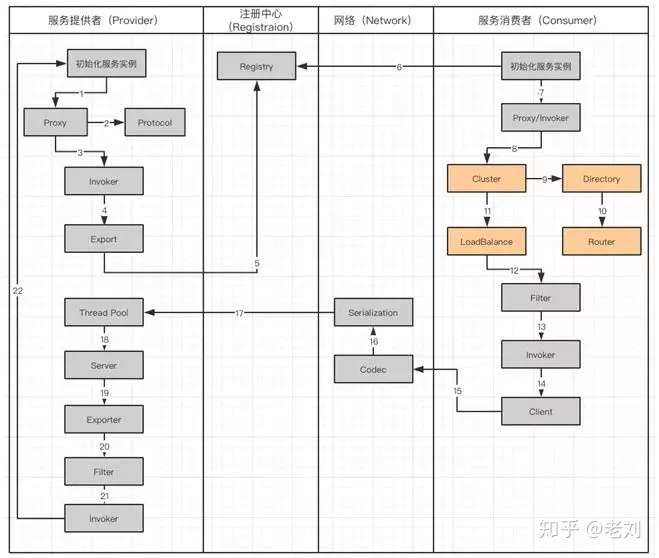
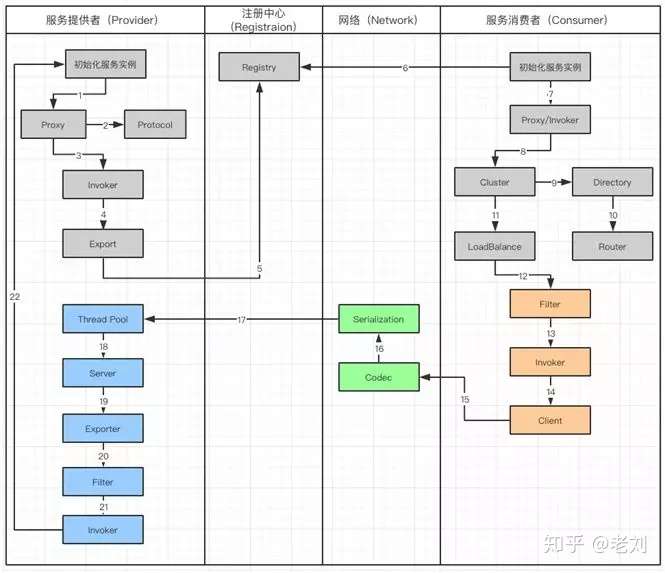
Dubbo 服务调用流程图
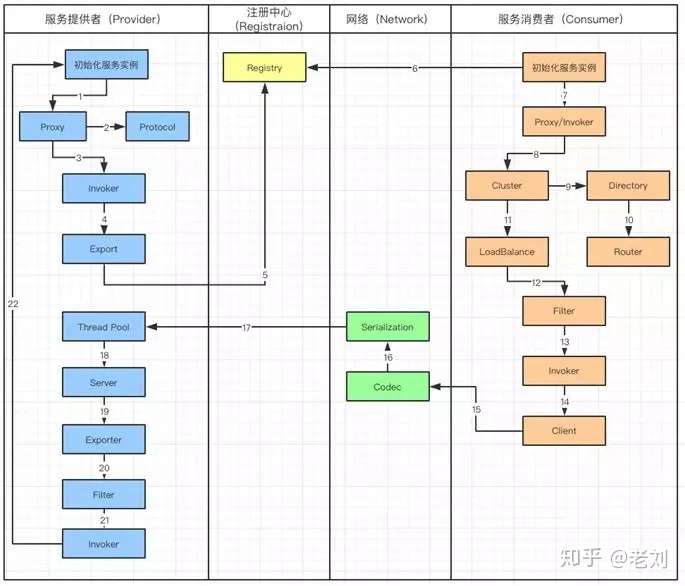
工作流涉及到服务提供者(Provider),注册中心(Registration),网络(Network)和服务消费者(Consumer):
- 服务提供者在启动的时候,会通过读取一些配置将服务实例化。
- Proxy 封装服务调用接口,方便调用者调用。客户端获取 Proxy 时,可以像调用本地服务一样,调用远程服务。
- Proxy 在封装时,需要调用 Protocol 定义协议格式,例如:Dubbo Protocol。
- 将 Proxy 封装成 Invoker,它是真实服务调用的实例。
- 将 Invoker 转化成 Exporter,Exporter 只是把 Invoker 包装了一层,是为了在注册中心中暴露自己,方便消费者使用。
- 将包装好的 Exporter 注册到注册中心。
- 服务消费者建立好实例,会到服务注册中心订阅服务提供者的元数据。元数据包括服务 IP 和端口以及调用方式(Proxy)。
- 消费者会通过获取的 Proxy 进行调用。通过服务提供方包装过程可以知道,Proxy 实际包装了 Invoker 实体,因此需要使用 Invoker 进行调用。
- 在 Invoker 调用之前,通过 Directory 获取服务提供者的 Invoker 列表。在分布式的服务中有可能出现同一个服务,分布在不同的节点上。
- 通过路由规则了解,服务需要从哪些节点获取。
- Invoker 调用过程中,通过 Cluster 进行容错,如果遇到失败策略进行重试。
- 调用中,由于多个服务可能会分布到不同的节点,就要通过 LoadBalance 来实现负载均衡。
- Invoker 调用之前还需要经过 Filter,它是一个过滤链,用来处理上下文,限流和计数的工作。
- 生成过滤以后的 Invoker。
- 用 Client 进行数据传输。
- Codec 会根据 Protocol 定义的协议,进行协议的构造。
- 构造完成的数据,通过序列化 Serialization 传输给服务提供者。
- Request 已经到达了服务提供者,它会被分配到线程池(ThreadPool)中进行处理。
- Server 拿到请求以后查找对应的 Exporter(包含有 Invoker)。
- 由于 Export 也会被 Filter 层层包裹
- 通过 Filter 以后获得 Invoker
- 最后,对服务提供者实体进行调用。
上面调用步骤经历了这么多过程,其中出现了 Proxy,Invoker,Exporter,Filter。
实际上都是调用实体在不同阶段的不同表现形式,本质是一样的,在不同的使用场景使用不同的实体。
例如 Proxy 是用来方便调用者调用的。Invoker 是在调用具体实体时使用的。Exporter 用来注册到注册中心的等等。
后面我们会对具体流程进行解析。如果时间不够无法阅读完全文,可以把上面的图保存。
服务暴露实现原理
上面讲到的服务调用流程中,开始服务提供者会进行初始化,将暴露给其他服务调用。服务消费者也需要初始化,并且在注册中心注册自己。
服务提供者和服务消费者暴露服务
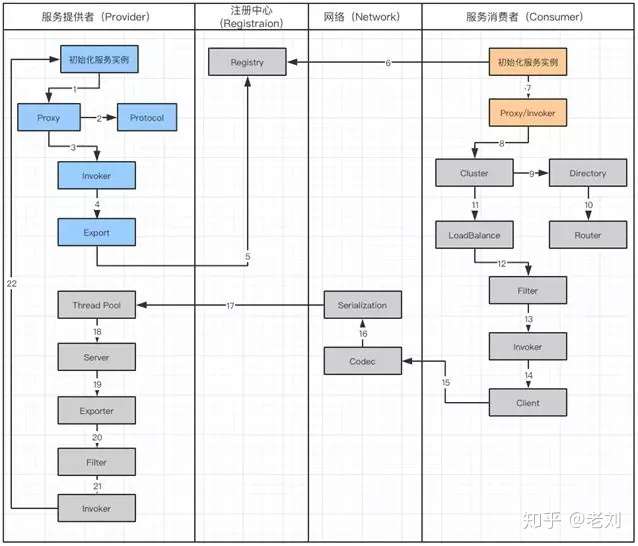
首先来看看服务提供者暴露服务的整体机制:
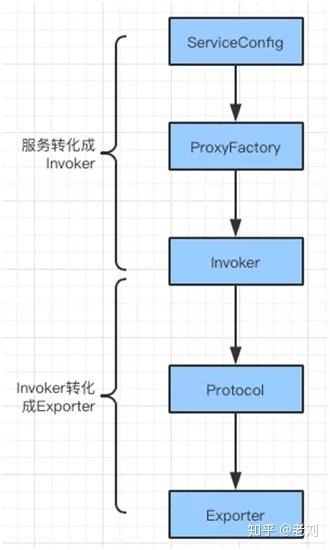
开篇的大图中列举了 Config 核心组件,在服务提供者初始化的时候,会通过 Config 组件中的 ServiceConfig 读取服务的配置信息。
这个配置信息有三种形式,分别是 XML 文件,注解(Annoation)和属性文件(Properties 和 yaml)。
在读取配置文件生成服务实体以后,会通过 ProxyFactory 将 Proxy 转换成 Invoker。
此时,Invoker 会被定义 Protocol,之后会被包装成 Exporter。最后,Exporter 会发送到注册中心,作为服务的注册信息。上述流程主要通过 ServiceConfig 中的 doExport 完成。
下面是针对多协议多注册中心进行源代码分析:
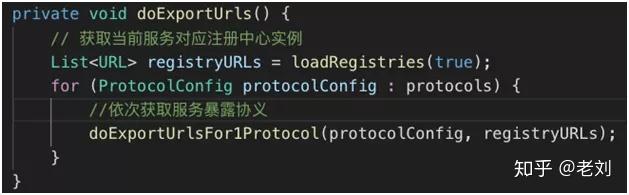
doExportUrls 方法
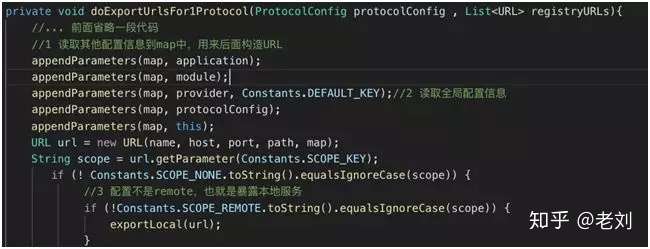
doExportUrlsFor1Protocol 方法-1
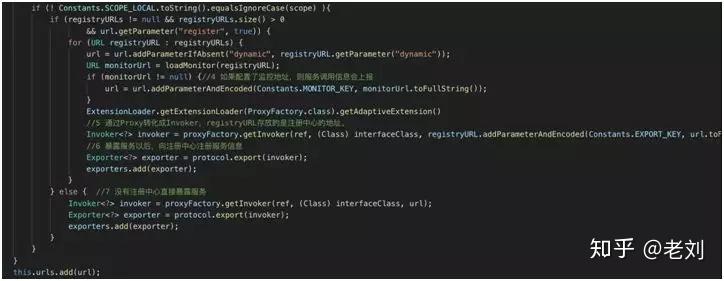
doExportUrlsFor1Protocol 方法-2
上面截取了服务提供者暴露服务的代码片段,从注释上看整个暴露过程分为七个步骤:
- 读取其他配置信息到 map 中,用来后面构造 URL。
- 读取全局配置信息。
- 配置不是 remote,也就是暴露本地服务。
- 如果配置了监控地址,则服务调用信息会上报。
- 通过 Proxy 转化成 Invoker,RegistryURL 存放的是注册中心的地址。
- 暴露服务以后,向注册中心注册服务信息。
- 没有注册中心直接暴露服务。
一旦服务注册到注册中心以后,注册中心会通过 RegistryProtocol 中的 Export 方法将服务暴露出去,并依次做以下操作:
- 委托具体协议进行服务暴露,创建 NettyServer 监听端口,并保持服务实例。
- 创建注册中心对象,创建对应的 TCP 连接。
- 注册元数据到注册中心。
- 订阅 Configurators 节点。
- 如果需要销毁服务,需要关闭端口,注销服务信息。
说完了服务提供者的暴露再来看看服务消费者。
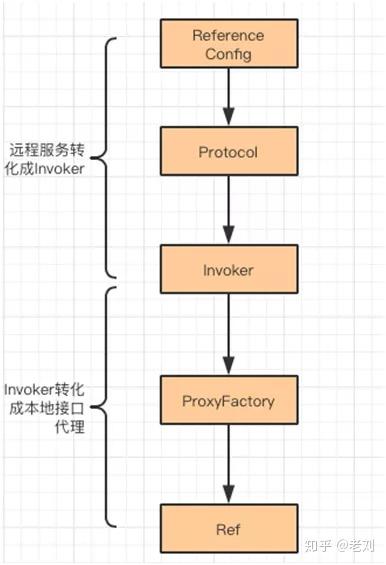
服务消费者首先持有远程服务实例生成的 Invoker,然后把 Invoker 转换成用户接口的动态代理引用。
框架进行服务引用的入口点在 ReferenceBean 中的 getObject 方法,会将实体转换成 ReferenceBean,它是集成与 ReferenceConfig 类的。
这里一起来看看 createProxy 的源代码:
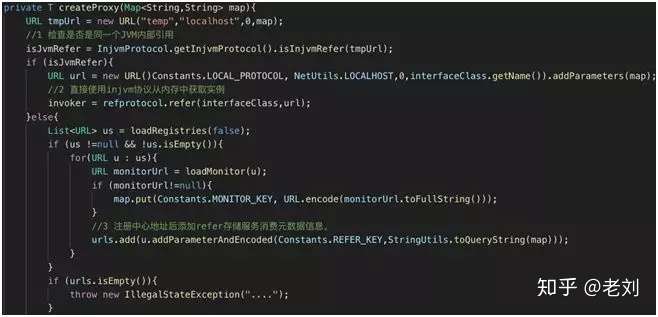
getProxy 代码片段 1
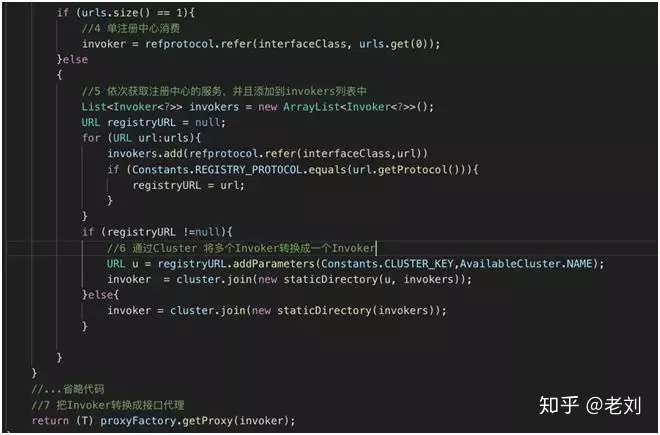
getProxy 代码片段 2
从上面代码片段可以看出,消费者服务在调用服务提供者时,做了以下动作:
- 检查是否是同一个 JVM 内部引用。
- 如果是同一个 JVM 的引用,直接使用 injvm 协议从内存中获取实例。
- 注册中心地址后,添加 refer 存储服务消费元数据信息。
- 单注册中心消费。
- 依次获取注册中心的服务,并且添加到 Invokers 列表中。
- 通过 Cluster 将多个 Invoker 转换成一个 Invoker。
- 把 Invoker 转换成接口代理。
注册中心
说完服务暴露,再回头来看看注册中心。Dubbo 通过注册中心实现了分布式环境中服务的注册和发现。
其主要作用如下:
- 动态载入服务。服务提供者通过注册中心,把自己暴露给消费者,无须消费者逐个更新配置文件。
- 动态发现服务。消费者动态感知新的配置,路由规则和新的服务提供者。
- 参数动态调整。支持参数的动态调整,新参数自动更新到所有服务节点。
- 服务统一配置。统一连接到注册中心的服务配置。
配置中心工作流--注册调用流程图
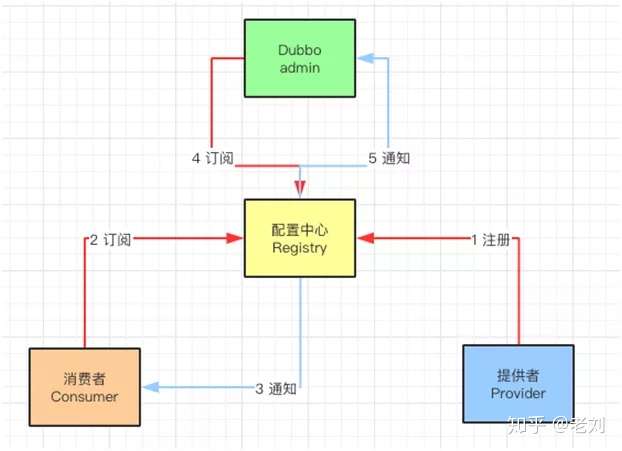
先看看注册中心调用的流程图:
- 提供者(Provider)启动时,会向注册中心写入自己的元数据信息(调用方式)。
- 消费者(Consumer)启动时,也会在注册中心写入自己的元数据信息,并且订阅服务提供者,路由和配置元数据的信息。
- 服务治理中心(duubo-admin)启动时,会同时订阅所有消费者,提供者,路由和配置元数据的信息。
- 当提供者离开或者新提供者加入时,注册中心发现变化会通知消费者和服务治理中心。
注册中心工作原理
Dubbo 有四种注册中心的实现,分别是 ZooKeeper,Redis,Simple 和 Multicast。
这里着重介绍一下 ZooKeeper 的实现。ZooKeeper 是负责协调服务式应用的。
它通过树形文件存储的 ZNode 在 /dubbo/Service 目录下面建立了四个目录,分别是:
- Providers 目录下面,存放服务提供者 URL 和元数据。
- Consumers 目录下面,存放消费者的 URL 和元数据。
- Routers 目录下面,存放消费者的路由策略。
- Configurators 目录下面,存放多个用于服务提供者动态配置 URL 元数据信息。
客户端第一次连接注册中心的时候,会获取全量的服务元数据,包括服务提供者和服务消费者以及路由和配置的信息。
根据 ZooKeeper 客户端的特性,会在对应 ZNode 的目录上注册一个 Watcher,同时让客户端和注册中心保持 TCP 长连接。
如果服务的元数据信息发生变化,客户端会接受到变更通知,然后去注册中心更新元数据信息。变更时根据 ZNode 节点中版本变化进行。
Dubbo 集群容错
Cluster,Directory,Router,LoadBalance 核心接口
分布式服务多以集群形式出现,Dubbo 也不例外。在消费服务发起调用的时候,会涉及到 Cluster,Directory,Router,LoadBalance 几个核心组件。
Cluster,Directory,Router,LoadBalance 调用流程
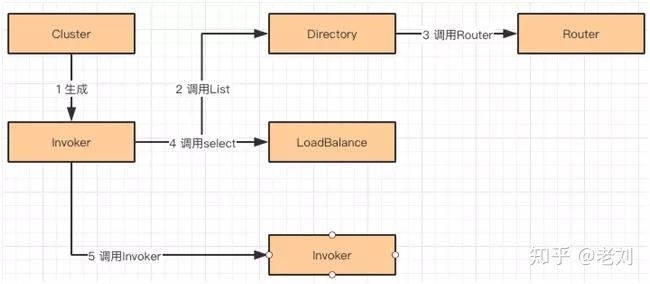
先看看他们是如何工作的:
①生成 Invoker 对象。根据 Cluster 实现的不同,生成不同类型的 ClusterInvoker 对象。通过 ClusertInvoker 中的 Invoker 方法启动调用流程。
②获取可调用的服务列表,可以通过 Directory 的 List 方法获取。这里有两类服务列表的获取方式。
分别是 RegistryDirectory 和 StaticDirectory:
- RegistryDirectory:属于动态 Directory 实现,会自动从注册中心更新 Invoker 列表,配置信息,路由列表。
- StaticDirectory:它是 Directory 的静态列表实现,将传入的 Invoker 列表封装成静态的 Directory 对象。
在 Directory 获取所有 Invoker 列表之后,会调用路由接口(Router)。其会根据用户配置的不同策略对 Invoker 列表进行过滤,只返回符合规则的 Invoker。
假设用户配置接口 A 的调用,都使用了 IP 为 192.168.1.1 的节点,则 Router 会自动过滤掉其他的 Invoker,只返回 192.168.1.1 的 Invoker。
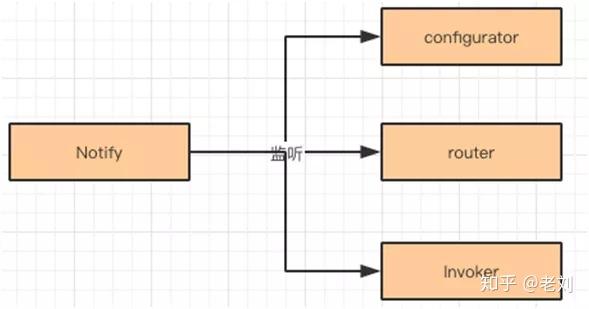
这里介绍一下 RegistryDirectory 的实现,它通过 Subscribe 和 Notify 方法,订阅和监听注册中心的元数据。
Subscribe,订阅某个 URL 的更新信息。Notify,根据订阅的信息进行监听。包括三类信息,配置 Configurators,路由 Router,以及 Invoker 列表。
管理员会通过 dubbo-admin 修改 Configurators 的内容,Notify 监听到该信息,就更新本地服务的 Configurators 信息。
同理,路由信息更新了,也会更新服务本地路由信息。如果 Invoker 的调用信息变更了(服务提供者调用信息),会根据具体情况更新本地的 Invoker 信息。
Notify 监听三类信息
通过前面三步生成的 Invoker 需要调用最终的服务,但是服务有可能分布在不同的节点上面。所以,需要经过 LoadBalance。
Dubbo 的负载均衡策略有四种:
- Random LoadBalance,随机,按照权重设置随机概率做负载均衡。
- RoundRobinLoadBalance,轮询,按照公约后的权重设置轮询比例。
- LeastActiveLoadBalance,按照活跃数调用,活跃度差的被调用的次数多。活跃度相同的 Invoker 进行随机调用。
- ConsistentHashLoadBalance,一致性 Hash,相同参数的请求总是发到同一个提供者。
最后进行 RPC 调用。如果调用出现异常,针对不同的异常提供不同的容错策略。Cluster 接口定义了 9 种容错策略,这些策略对用户是完全透明的。
用户可以在,,, 标签上通过 Cluster 属性设置:
- Failover,出现失败,立即重试其他服务器。可以设置重试次数。
- Failfast,请求失败以后,返回异常结果,不进行重试。
- Failsafe,出现异常,直接忽略。
- Failback,请求失败后,将失败记录放到失败队列中,通过定时线程扫描该队列,并定时重试。
- Forking,尝试调用多个相同的服务,其中任意一个服务返回,就立即返回结果。
- Broadcast,广播调用所有可以连接的服务,任意一个服务返回错误,就任务调用失败。
- Mock,响应失败时返回伪造的响应结果。
- Available,通过遍历的方式查找所有服务列表,找到第一个可以返回结果的节点,并且返回结果。
- Mergable,将多个节点请求合并进行返回。
Dubbo 远程调用
服务消费者经过容错,Invoker 列表,路由和负载均衡以后,会对 Invoker 进行过滤,之后通过 Client 编码,序列化发给服务提供者。
过滤,发送请求,编码,序列化发送给服务提供者
从上图可以看出在服务消费者调用服务提供者的前后,都会调用 Filter(过滤器)。
可以针对消费者和提供者配置对应的过滤器,由于过滤器在 RPC 执行过程中都会被调用,所以为了提高性能需要根据具体情况配置。
Dubbo 系统有自带的系统过滤器,服务提供者有 11 个,服务消费者有 5 个。过滤器的使用可以通过 @Activate 的注释,或者配置文件实现。
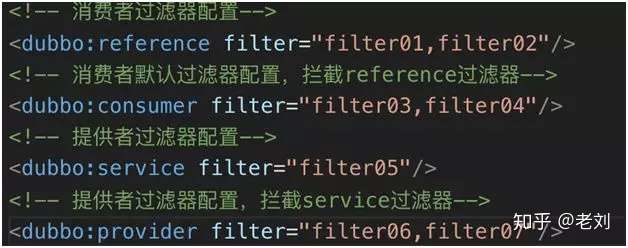 配置文件实现过滤器
配置文件实现过滤器
过滤器的使用遵循以下几个规则:
- 过滤器顺序,过滤器执行是有顺序的。例如,用户定义的过滤器的过滤顺序默认会在系统过滤器之后。
又例如,上图中 filter=“filter01, filter02”,filter01 过滤器执行就在 filter02 之前。 - 过滤器失效,如果针对某些服务或者方法不希望使用某些过滤器,可以通过“-”(减号)的方式使该过滤器失效。例如,filter=“-filter01”。
- 过滤器叠加,如果服务提供者和服务消费者都配置了过滤器,那么两个过滤器会被叠加生效。
由于,每个服务都支持多个过滤器,而且过滤器之间有先后顺序。因此在设计上 Dubbo 采用了装饰器模式,将 Invoker 进行层层包装,每包装一层就加入一层过滤条件。在执行过滤器的时候就好像拆开一个一个包装一样。
调用请求经过过滤以后,会以 Invoker 的形式对 Client 进行调用。Client 会交由底层 I/O 线程池处理,其包括处理消息读写,序列化,反序列化等逻辑。
同时会对 Dubbo 协议进行编码和解码操作。Dubbo 协议基于 TCP/IP 协议,包括协议头和协议体。
协议体包含了传输的主要内容,其意义不言而喻,它是由 16 字节长的报文组成,每个字节包括 8 个二进制位。
内容如下:
- 0-7 位,“魔法数”高位。
- 8-15 位,“魔法数”低位。前面两个字节的“魔法数”,是用来区别两个不同请求。好像编程中使用的“;”“/”之类的符号将两条记录分开。PS:魔法数用固定的“0xdabb”表示,
- 16 位,数据包的类型,因为 RPC 调用是双向的,0 表示 Response,1 表示 Request。
- 17 位,调用方式,0 表示单项,1 表示双向。
- 18 位,时间标识,0 表示请求/响应,1 表示心跳包。
- 19-23 位,序列化器编号,就是告诉协议用什么样的方式进行序列化。例如:Hessian2Serialization 等等。
- 24-31 位,状态位。20 表示 OK,30 表示 CLIENT_TIMEOUT 客户端超时,31 表示 SERVER_TIMEOUT 服务端超时,40 表示 BAD_REQUEST 错误的请求,50 表示 BAD_RESPONSE 错误的响应。
- 32-95 位,请求的唯一编号,也就是 RPC 的唯一 ID。
- 96-127,消息体包括 Dubbo 版本号,服务接口名,服务接口版本,方法名,参数类型,方法名,参数类型,方法参数值和请求额外参数。
服务消费者在调用之前会将上述服务消息体,根据 Dubbo 协议打包好。框架内部会调用 DefaultFuture 对象的 get 方法进行等待。
在准备发送请求的时候,才创建 Request 对象,这个对象会保存在一个静态的 HashMap 中,当服务提供者处理完 Request 之后,将返回的 Response 放回到 Futures 的 HashMap 中。
在 HashMap 中会找到对应的 Request 对象,并且返回给服务消费者。
服务消费者请求和响应图

协议打包好以后就需要给协议编码和序列化。这里需要用到 Dubbo 的编码器,其过程是将信息传化成字节流。
Dubbo 协议编码请求对象分为使用 ExchangeCodec 中的两个方法,encodeRequest 负责编码协议头和 encodeRequestData 编码协议体。
同样通过 encodeResponse 编码协议头,encodeResponseData 编码协议体。
服务消费者和提供者都通过 decode 和 decodeBody 两个方法进行解码,不同的是解码有可能在 IO 线程或者 Dubbo 线程池中完成。
虽然,编码和解码的细节在这里不做展开,但是以下几点需要注意:
- 构造 16 字节的协议头,特别是需要创建前面两个字节的魔法数,也就是“0xdabb”,它是用来分割两个不同请求的。
- 生成唯一的请求/响应 ID,并且根据这个 ID 识别请求和响应协议包。
- 通过协议头中的 19-23 位的描述,进行序列化/反序列化操作。
- 为了提高处理效率,每个协议都会放到 Buffer 中处理。
当服务提供者收到请求协议包以后,先将其放到 ThreadPool 中,然后依次处理。
由于服务提供者在注册中心是通过 Exporter 的方式暴露服务的,服务消费者也是通过 Exporter 作为接口进行调用的。
Exporter 是将 Invoker 进行了包装,将拆开的 Invoker 进行 Filter 过滤链条进行过滤以后,再去调用服务实体。最后,将信息返回给服务消费者。
总结
我们首先了解 Dubbo 的分层和几个核心模块,分别介绍他们的职责。然后通过一个简单的例子,服务消费者调用服务提供者,用 Dubbo 的工作流程将各个模块串起来。
在这 22 步的流程中,以服务提供者和服务消费者的初始化为起点,用到了 Config 和 Proxy 以及 Protocol,Invoker。
注册中心作为两者的连接桥梁,起到了服务发现和注册的作用,并且着重讲了如何通过 ZooKeeper 实现注册中心的原理。
在服务消费者调用提供者之前,需要通过 Cluster 容错机制,Directory 获取 Invoker 列表,Router 找到路由信息,再使用 LoadBalance 知道具体服务。
在调用服务提供者之间还不忘通过 Filter 进行过滤,通过装饰者模式实现的 Filter 可以形成过滤链条,依次对条件进行过滤。
对于远程调用,需要调用打包协议,针对 Dubbo 协议进行了描述,并且针对该协议进行了编码/解码和序列化/反序列化的操作。
服务提供者收到请求以后,会将请求放到 ThreadPool 中逐一处理。通过 Exporter,Invoker,Filter 的逐级转换,最后响应请求。
由于篇幅有限很多功能例如 SPI,Merger 等没有介绍到,有时间再和大家细聊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号