pandas模块的数据操作
数据操作
数据操作最重要的一步也是第一步就是收集数据,而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问,第二种就是需要到网站的API处获取数据或者网页上爬取数据,还有一种可能就是你的公司里面有自己的数据库,直接访问数据库里面的数据进行分析。需要注意的是我们不仅需要将数据收集起来还要将不同格式的数据进行整理,最后再做相应的操作。
1、数据导入、存储
访问数据是数据分析的所必须的第一步,只有访问到数据才可以对数据进行分析。
1.1、文本格式
常用pandas解析函数:
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。以下
| 函数 | 描述 |
|---|---|
| read_csv | 从文件、url或者文件型对象读取分割好的数据,逗号是默认分隔符 |
| read_table | 从文件、url或者文件型对象读取分割好的数据,制表符('\t')是默认分隔符 |
| read_fwf | 读取定宽格式数据(无分隔符) |
| read_clipboard | 读取剪贴板中的数据,可以看做read_table的剪贴板。再将网页转换为表格 |
| read_excel | 从Excel的XLS或者XLSX文件中读取表格数据 |
| read_hdf | 读取pandas写的HDF5文件 |
| read_html | 从HTML文件中读取所有表格数据 |
| read_json | 从json字符串中读取数据 |
| read_pickle | 从Python pickle格式中存储的任意对象 |
| read_msgpack | 二进制格式编码的pandas数据 |
| read_sas | 读取存储于sas系统自定义存储格式的SAS数据集 |
| read_stata | 读取Stata文件格式的数据集 |
| read_feather | 读取Feather二进制文件格式 |
| read_sql | 将SQL查询的结果(SQLAlchemy)读取为pandas的DataFrame |
我们可以通过上表对这些解析函数有一个简单了解,其中read_csv和read_table是以后用得最多的两个方法,接下来我们主要就这两个方法测试。
1.1.1、read_csv
csv文件就是一个以逗号分隔字段的纯文本文件,用于测试的文件是本身是一个Excel文件,需要修改一下扩展名,但是简单的修改后缀名不行,还需要将字符编码改变为utf-8,因为默认的是ASCII,否则是会报错的。然后就可以通过read_csv将它读入到一个DataFrame:
import pandas as pd
df = pd.read_csv("E:/Test/test3.csv")
df
name age sex
0 佩奇 18 女
1 乔治 19 男
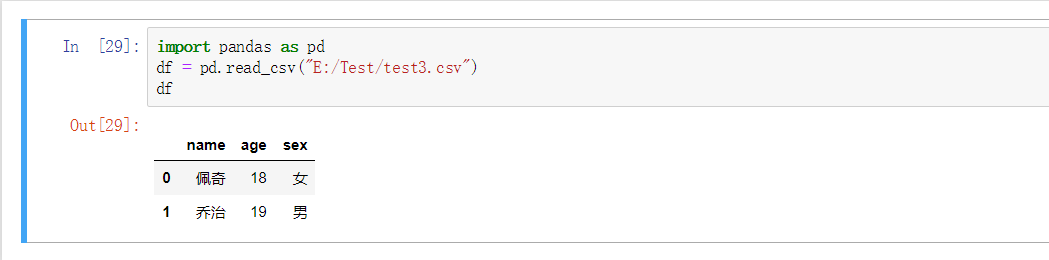
注意:
到这里可能就会有些人有疑问了,为什么我的文件路径不对啊,那是因为在我们这个方法当中的路径当它往左斜的时候需要用双斜杠,否则就要使用右斜杠
1.1.2、read_table
还可以使用read_table,并且指定分隔符
import pandas as pd
df = pd.read_csv("E:/Test/test3.csv")
df
name age sex
0 佩奇 18 女
1 乔治 19 男
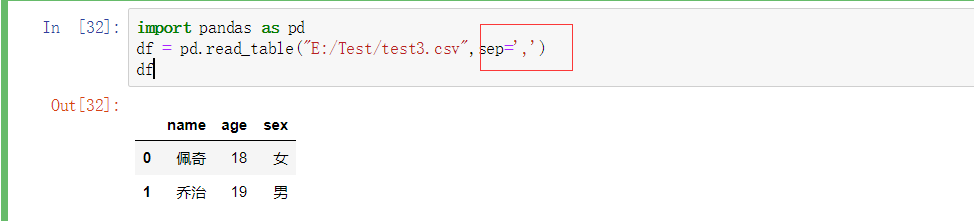
如果不指定分隔符,它的数据之间会有逗号。
以上只是简单的读取操作,
1.1.3、指定列名
pandas可以帮助我们自动分配列名,也可以自己指定列名
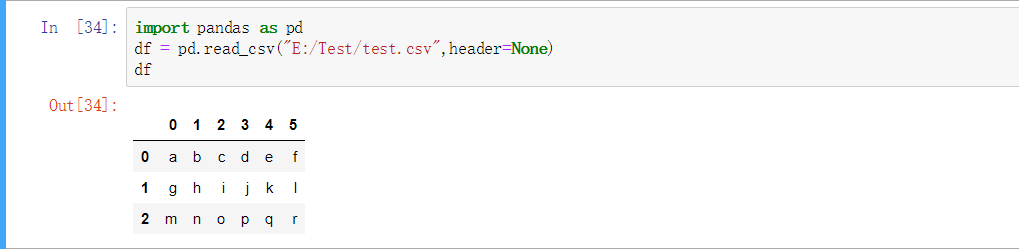
默认列名
import pandas as pd
df = pd.read_csv("E:/Test/test.csv",header=None)
df
0 1 2 3 4 5
0 a b c d e f
1 g h i j k l
2 m n o p q r
指定列名
import pandas as pd
df = pd.read_csv("E:/Test/test.csv",names=['数','据','分','析','真','好','玩'])
df
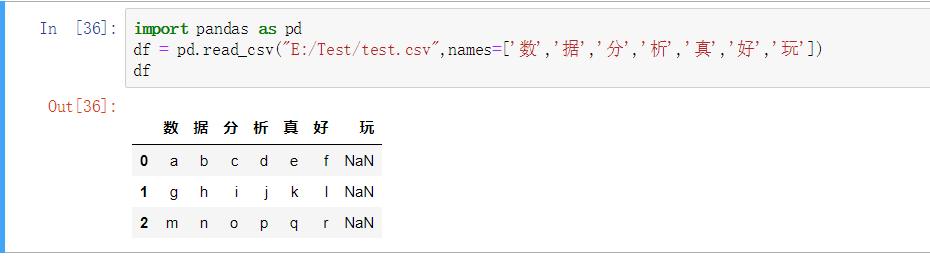
具体还有那些参数,通过表格展示一下,这些参数是read_csv和read_table共有的
| 参数 | 描述 |
|---|---|
| path | 表明文件系统位置的字符串、URL或者文件型对象 |
| sep或delimiter | 用于分隔每行字段的字符序列或正则表达式 |
| header | 用作列名的行号,默认是0(第一行),如果没有为None |
| names | 结果的列名列表,和header=None一起用 |
| skiprows | 从文件开头起,需要跳过的行数或者行号列表 |
| na_values | 用NA替换的值序列(可以用来处理缺失值) |
| data_parser | 用于解析日期的函数 |
| nrows | 从文件开头处读取的行数 |
| chunksize | 用于设置迭代的块大小 |
| encoding | 设置文本编码 |
1.1.4、分块读取文件
刚才我们读取文件是把整个文件都读取出来了,那接下来我们就尝试分块读取文本文件,因为不是所有的文件内容都只有这么少,我们在实际运用当中会需要读取文件的一个小片段。
读取大文件的时候可以添加一个参数使得显示的内容更加紧凑
import pandas as pd
pd.options.display.max_rows = 3
df = pd.read_csv("E:/Test/test.csv")
df
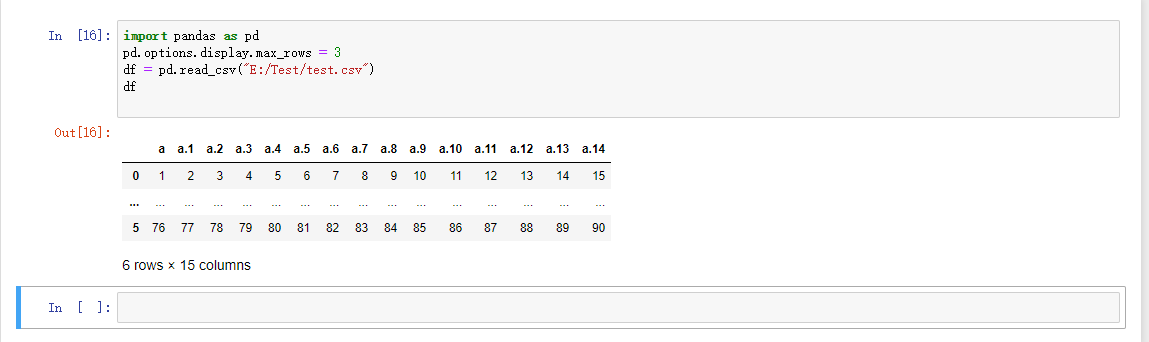
还可以通过上面表格中提到的 nrows 参数选择只读取其中的几行
1.2、二进制
1.2.1、pickle
在Python中有一个自带的序列化模块pickle,它是进行二进制格式操作存储数据最高效、最方便的方式之一。在pandas中有一个to_pickle方法可以将数据以pickle格式写入硬盘
import pandas as pd
df = pd.read_csv("E:/Test/test_j.csv")
df.to_pickle("E:/Test/df_pickle")
运行完之后会发现没反应,但是可以打开你存储的文件夹会发现这个pickle文件已经存到里面了。
虽然说这种方式非常方便,但是却很难保证格式的长期有效性。一个今天被pickle化的对象可能明天会因为库的新版本而无法反序列化.在pandas当中还支持其他的二进制格式。接着往下看
1.2.2、HDF5
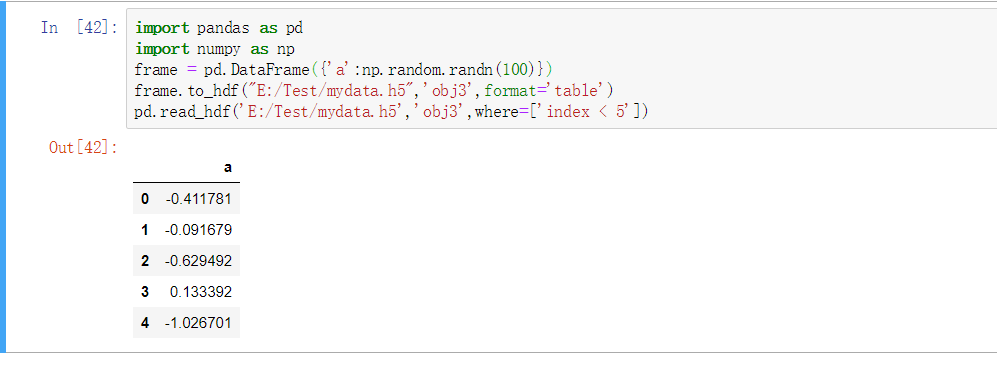
HDF5主要用于存储大量的科学数组数据。以C库的形式提供,并且有许多其他语言的接口,例如:JAVA、Julia,当然还有我们的Python。HDF5中的HDF代表分层数据格式,每个HDF5文件可以存储多个数据集并且支持元数据
pandas.read_hdf函数是使用HDF5格式的一个快捷方法
import pandas as pd
import numpy as np
frame = pd.DataFrame({'a':np.random.randn(100)})
frame.to_hdf("E:/Test/mydata.h5",'obj3',format='table')
pd.read_hdf('E:/Test/mydata.h5','obj3',where=['index < 5'])
1.3、Web API
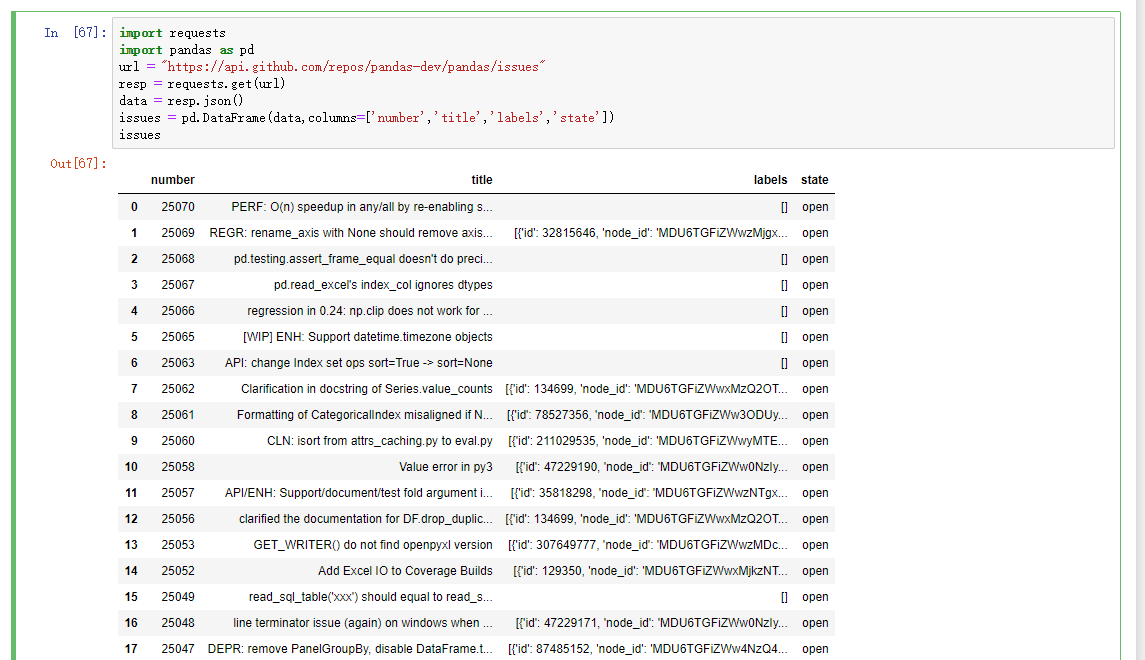
现在很多网站都有公开的API,通过JSON或者其他什么格式提供数据服务。那接下来,我们就通过Python的requests模块访问Web API。
import requests
import pandas as pd
url = "https://api.github.com/repos/pandas-dev/pandas/issues"
resp = requests.get(url)
data = resp.json()
# 因为data中的每个元素都是一个字典,可以直接将data传给DataFrame,并且将其中自己喜欢的字段展示出来
issues = pd.DataFrame(data,columns=['number','title','labels','state'])
issues
1.4、操作数据库
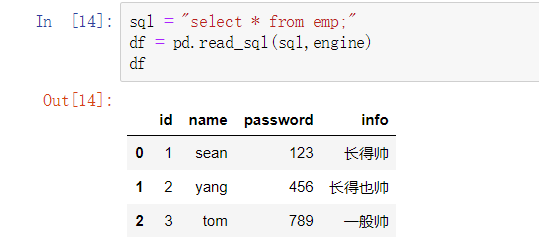
在数据分析的操作当中,读写数据库主要还是由pandas来进行操作。在工作环境最为常用的就是mysql数据库,所以就以操作mysql作为示例:
从数据库导出数据:
import pandas as pd
from sqlalchemy import create_engine
import pymysql
# 创建数据库连接
conn = create_engine("mysql+pymysql://root:123@localhost:3306/pd_test")
sql = "select * from emp;"
# 通过sql语句以及连接查询数据库,最终返回的结果是一个DataFrame数组
df = pd.read_sql(sql,engine)
df
运行结果:
将数据导入数据库:
在pandas当中存在一个to_sql函数,可以将数据写入数据库,它支持两类mysql引擎,一个是sqlalchemy,另一个是sqlliet3,但是由于sqlliet3寒就没有更新,所以建议使用sqlalchemy。
# key为列,键为值
data = pd.DataFrame({'id':[1,2,3],
'name':['贾玲','沈腾','马丽'],
'password':['123','456','789']})
# 第一个参数:新建的表名;第二个:数据库连接
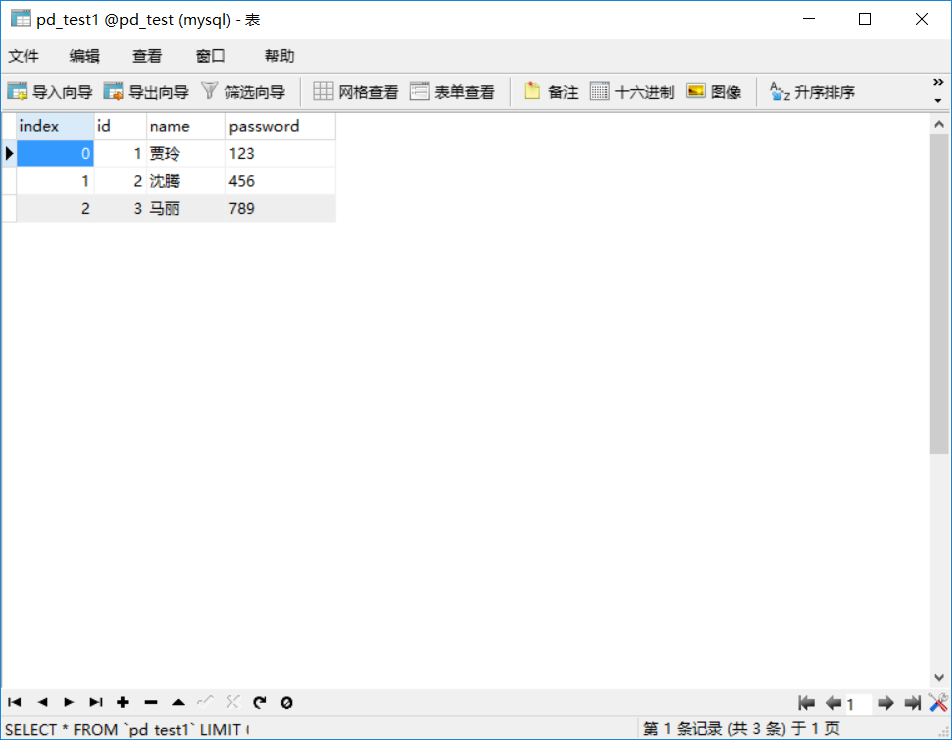
data.to_sql('pd_test1',conn,index = True)
通过可视化工具打开数据库可以看见,一个DataFrame数组就直接存到数据库里面了
2、数据处理
经过前面的了解,对于数据的导入以及存储已经有了一个简单的了解,但是在实际的工作情况当中,拿到的数据不可能都是预想的格式,所以说,就需要通过一些文本处理工具将这种特殊数据从一种形式转换为另一种可以接受的形式,正好在Python的pandas库当中就为我们提供了一个高级、灵活和快速的工具集,将数据转换成想要的格式。
一个没有处理的数据集就和一个没有化妆的女网红一样,所以我们要一步一步给你的数据化上妆,让它们看起来更加漂亮!!!
2.1、处理缺失值
缺失数据在数据分析的应用当中是很常见的,pandas的目标之一就是尽可能的无影响的处理缺失值。在pandas当中使用浮点值NaN(Not a Number来表是缺失值)。处理缺失值的最常见的两种的方法:第一个就是直接将那个值丢弃,第二种方式就是补全缺失值。
| 属性 | 描述 |
|---|---|
| dropna | 根据各标签的值中是否存在缺失数据对轴标签进行过滤。 |
| fillna | 用指定值或插值方法(如ffill或bfill)填充缺失数据 |
| isnull | 返回一个含有布尔值的对象,这些布尔值表示哪些值是缺失值/NA |
| notnull | isnull的否定式 |
2.1.1、过滤缺失值
data = pd.Series(['pandas','numpy',np.nan,'matplotlib'])
-------------------------------------------
data.isnull()
运行结果:
0 False
1 False
2 True
3 False
dtype: bool # 返回一个布尔值数组
-------------------------------------------
data[0] = None # python中内置的None值在对象数组种也可以作为NA
data.notnull()
运行结果:
0 False
1 True
2 False
3 True
dtype: bool
-------------------------------------------
data_1 = pd.Series([1,np.nan,3,np.nan,5.5,9])
data_1.dropna() # 丢弃任何含有缺失值的行
运行结果:
0 1.0
2 3.0
4 5.5
5 9.0
dtype: float64
# data_1[data_1.notnull()]等价于data_1.dropna()
以上都是对Series这种一维数组的缺失值处理,如果对于DataFrame这种二维数组的处理就会出现一些问题。
df = pd.DataFrame([[1,3,5,7,9],[2,4,6,np.nan],[1.5,5.,6.3,np.nan],[4.,2.3,np.nan,8,9.],[np.nan,np.nan,np.nan,np.nan,np.nan]])
df
运行结果:
0 1 2 3 4
0 1.0 3.0 5.0 7.0 9.0
1 2.0 4.0 6.0 NaN NaN
2 1.5 5.0 6.3 NaN NaN
3 4.0 2.3 NaN 8.0 9.0
4 NaN NaN NaN NaN NaN
-------------------------------------------
cleaned = df.dropna()
cleaned
运行结果:
0 1 2 3 4
0 1.0 3.0 5.0 7.0 9.0
# 所有带有缺失值的行全被丢弃了
对于这种情况可以通过传递参数来解决:
df.dropna(how="all") # 丢弃全为缺失值的行
运行结果:
0 1 2 3 4
0 1.0 3.0 5.0 7.0 9.0
1 2.0 4.0 6.0 NaN NaN
2 1.5 5.0 6.3 NaN NaN
3 4.0 2.3 NaN 8.0 9.0
-------------------------------------------
df[4] = np.nan
df.dropna(axis=1,how="all") # 丢弃全为缺失值的列
运行结果:
0 1 2 3
0 1.0 3.0 5.0 7.0
1 2.0 4.0 6.0 NaN
2 1.5 5.0 6.3 NaN
3 4.0 2.3 NaN 8.0
4 NaN NaN NaN NaN
-------------------------------------------
2.1.2、补全缺失值
有时候在操作数据的时候可能不想过滤掉缺失数据,因为有可能会丢弃和他有关的其他数据,而是希望通过一些其他方式来填补那些缺失的地方。fillna方法是处理这些问题最主要的方法。
df.fillna(0) # 替换缺失值为0
运行结果:
0 1 2 3 4
0 1.0 3.0 5.0 7.0 0.0
1 2.0 4.0 6.0 0.0 0.0
2 1.5 5.0 6.3 0.0 0.0
3 4.0 2.3 0.0 8.0 0.0
4 0.0 0.0 0.0 0.0 0.0
-------------------------------------------
df.fillna({1:0.5,2:0}) # 对不同的列填充不同的值
0 1 2 3 4
0 1.0 3.0 5.0 7.0 NaN
1 2.0 4.0 6.0 NaN NaN
2 1.5 5.0 6.3 NaN NaN
3 4.0 2.3 0.0 8.0 NaN
4 NaN 0.5 0.0 NaN NaN
-------------------------------------------
df.fillna(0,inplace=True)
df
运行结果:
0 1 2 3 4
0 1.0 3.0 5.0 7.0 0.0
1 2.0 4.0 6.0 0.0 0.0
2 1.5 5.0 6.3 0.0 0.0
3 4.0 2.3 0.0 8.0 0.0
4 0.0 0.0 0.0 0.0 0.0
使用fillna还可以进行插值
df1 = pd.DataFrame(np.random.randn(6,3))
df1
运行结果:
0 1 2
0 0.475304 -1.274166 1.467016
1 -0.113910 0.935197 -1.008954
2 0.218006 0.209405 0.224217
3 1.878587 0.492774 -1.391237
4 -0.702284 0.863064 0.939069
5 -1.450531 0.994467 0.265843
# 一组数据数
-------------------------------------------
df1.iloc[2:,1] = np.nan # 将第二列第三行以后的数据都转换为缺失值
df1.iloc[4:,2] = np.nan # 将第三列第五行以后的数据都转换为缺失值
运行结果:
0 1 2
0 1.073202 0.644249 -0.089127
1 -0.028500 0.479373 -0.271212
2 1.575710 NaN -0.119795
3 -0.202480 NaN 0.385250
4 -1.090317 NaN NaN
5 0.985767 NaN NaN
-------------------------------------------
df1.fillna(method='ffill')
运行结果:
0 1 2
0 1.073202 0.644249 -0.089127
1 -0.028500 0.479373 -0.271212
2 1.575710 0.479373 -0.119795
3 -0.202480 0.479373 0.385250
4 -1.090317 0.479373 0.385250
5 0.985767 0.479373 0.385250
# 参数limit还可以设置替换的行
| 参数 | 说明 | |
|---|---|---|
| value | 用于填充缺失值的标量值或字典对象 | |
| method | 插值方式。如果函数调用时未指定其他参数的话,默认为"ffill" | |
| axis | 待填充的轴,默认axis=0 | |
| inplace | 修改调用者对象而不产生副本 | |
| limit | 可以连续填充的最大数量 |
2.2、数据转换
2.2.1、删除重复值
data = pd.DataFrame({"k1":['one','two'] * 3 + ['two'],
"k2":[1,1,2,3,3,4,4]})
data
运行结果:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
-----------------------------------------------
data.duplicated() # 返回一个布尔型Series,表示各行是否是重复行
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
-----------------------------------------------
data.drop_duplicates() # 返回一个DataFrame,重复的数组会标为False
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
# 重复的行被删除了
-----------------------------------------------
以上方法是针对全部列,还可以通过传入参数对部分指定列进行重复项判断。
data['v1'] = range(7) # 添加一个v1列
data.drop_duplicates(['k1','k2']) # 可以传入一个列表,指定列,默认保留第一个出现的值组合
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
5 two 4 5
-----------------------------------------------
data.drop_duplicates(['k1','k2'],keep='last') # 保留最后一个出现的值组合
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
2.2.2、使用函数或映射进行数据转换
data = pd.DataFrame({"goods":['Iphone','HUAWEI','SAMSUNG','MI','OPPO'], "price":[6000,4000,5000,3000,3000]})
data
运行结果:
goods price
0 Iphone 6000
1 HUAWEI 4000
2 SAMSUNG 5000
3 MI 3000
4 OPPO 3000
现在有这样一组数据,假设现在需要加上一列数据。将每样商品的出产国家加上
# 先定义一个不同商品到产地的映射
produce_nation = {
"iphone":'America',
"huawei":'China',
"samsung":'Korea',
"mi":'China',
"oppo":'China'
}
# 因为定义的商品全是大写,需要全部转换为小写
lower_cased = data['goods'].str.lower()
# 通过map映射添加一列出产国家数据
data['nation'] = lower_cased.map(produce_nation)
运行结果:
goods price nation
0 Iphone 6000 America
1 HUAWEI 4000 China
2 SAMSUNG 5000 Korea
3 MI 3000 China
4 OPPO 3000 China
也可以通过一个函数完成这些工作:
data['goods'].map(lambda x:produce_nation[x.lower()])
运行结果:
0 America
1 China
2 Korea
3 China
4 China
Name: goods, dtype: object
2.2.3、替换值
利用fillna()方法填充缺失数据是值替换的一种特殊情况。接下来可以使用replace方法进行替换值操作。
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data # 生成一个Series数组
运行结果:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64
----------------------------------------------
# 其中-999可能是缺失值的某一标识,需要使用NA替代这些值
1、
data.replace(-999, np.nan) # 通过replace产生一个新的Series,除非传入inplace=True
运行结果:
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
2、
data.replace([-999, -1000], np.nan) # 一次性替换多个值
3、
data.replace([-999, -1000], [np.nan, 0]) # 替换不同的值,通过列表
4、
data.replace({-999: np.nan, -1000: 0}) # 替换不同的值,通过字典
2.2.4、重命名轴索引
data = pd.DataFrame(np.arange(12).reshape((3,4)),index=['a','b','c'],columns=['one','two','three','four'])
data
| one | two | three | four | |
|---|---|---|---|---|
| a | 0 | 1 | 2 | 3 |
| b | 4 | 5 | 6 | 7 |
| c | 8 | 9 | 10 | 11 |
想要给数据集重新转换数据集的名称,但是还不修改原有数据集,就可以使用一个非常nb的方法rename
data.rename(index=str.title,columns=str.upper)
| ONE | TWO | THREE | FOUR | |
|---|---|---|---|---|
| A | 0 | 1 | 2 | 3 |
| B | 4 | 5 | 6 | 7 |
| C | 8 | 9 | 10 | 11 |
以上只是对轴索引的名称进行整列或是整行修改,有时候我们需要替换索引中的部分值,这就可以结合字典型对象来使用
data.rename(index={'a':"sean"},
columns={'two':"tank"})
| one | tank | three | four | |
|---|---|---|---|---|
| sean | 0 | 1 | 2 | 3 |
| b | 4 | 5 | 6 | 7 |
| c | 8 | 9 | 10 | 11 |
补充:还有一个参数inplace=True,可以修改原有的数据集
2.2.5、离散化和分箱
我们在进行数据分析的时候,一些连续的数值经常需要进行离散化,或者需要分离成一个个"小块"可以说"箱子"来进行分析。目前假设我们有某项研究的一组人员的数据,现在需要将他们进行分组,放入离散的年龄框当中
ages = [19,35,22,20,27,22,30,23,26,31,39,29,66,34,55,45,41,32,25]
现在需要将这些年龄分为:18-25,26-35,36-60以及61及以上的若干数组。
bins = [18,25,35,60,100]
cats = pd.cut(ages,bins)
cats
[(18, 25], (25, 35], (18, 25], (18, 25], (25, 35], ..., (35, 60], (35, 60], (35, 60], (25, 35], (18, 25]]
Length: 19
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
以上是将ages列表中不同的数据,分别放入不同的箱子当中。pandas返回的对象也和我们平时所见的不太一样,是一个特殊的Categorical对象。
cats.codes # 指明了ages中标签对应的数据所在的`箱子`
array([0, 1, 0, 0, 1, 0, 1, 0, 1, 1, 2, 1, 3, 1, 2, 2, 2, 1, 0],
dtype=int8)
cats.categories # 返回所有的箱子
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]]
closed='right',
dtype='interval[int64]')
pd.value_counts(cats) # 对不同箱子中的数据进行计数
(25, 35] 8
(18, 25] 6
(35, 60] 4
(60, 100] 1
dtype: int64
表示箱子的符号与区间的数学符号是一致的,小括号表明是开放的,中括号表明他是封闭的,也就是顾头不顾尾。可以自己改变参数right=False来改变哪一边封闭
pd.cut(ages,[18,26,36,61,100],right=False)
[[18, 26), [26, 36), [18, 26), [18, 26), [26, 36), ..., [36, 61), [36, 61), [36, 61), [26, 36), [18, 26)]
Length: 19
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
通过labels参数传递一个列表或者数组来传入自定义的箱名
group_names = ['first',"second",'third','fourth']
pd.cut(ages,bins,labels=group_names)
[first, second, first, first, second, ..., third, third, third, second, first]
Length: 19
Categories (4, object): [first < second < third < fourth]
如果我们传给cut一个整数个的箱子代替显示的箱边,pandas会自动根据数据当中的最大值和最小值计算出等长的箱子。
data = np.random.rand(20)
pd.cut(data,4,precision=2) # precision 精确度,用于控制数位
[(0.75, 0.99], (0.27, 0.51], (0.75, 0.99], (0.75, 0.99], (0.27, 0.51], ..., (0.75, 0.99], (0.034, 0.27], (0.034, 0.27], (0.51, 0.75], (0.034, 0.27]]
Length: 20
Categories (4, interval[float64]): [(0.034, 0.27] < (0.27, 0.51] < (0.51, 0.75] < (0.75, 0.99]]
使用cut方法通常不会使我们每个箱子具有相同数据量的数值,但是qcut,它是基于样本分为数进行分箱的,可以通过qcut得到等长的箱子。
data = np.random.randn(1000) # 生产正态分布的数组
cats = pd.qcut(data,4) # 切成四份
pd.value_counts(cats)
(0.714, 3.153] 250
(0.0908, 0.714] 250
(-0.592, 0.0908] 250
(-3.242, -0.592] 250
dtype: int64
2.2.6、检测和过滤异常值
data = pd.DataFrame(np.random.randn(1000,4))
data.describe()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | 0.051415 | 0.025348 | -0.022929 | -0.022217 |
| std | 0.974445 | 1.001188 | 0.988803 | 0.970864 |
| min | -2.954484 | -3.145678 | -2.807353 | -3.001159 |
| 25% | -0.601312 | -0.606223 | -0.684640 | -0.666618 |
| 50% | 0.053944 | 0.025130 | -0.000365 | -0.032060 |
| 75% | 0.693812 | 0.688407 | 0.658130 | 0.626298 |
| max | 2.861130 | 3.532333 | 3.326404 | 3.127593 |
现在需要找到一列数据中绝对值大于三的值
col = data[2]
col[np.abs(col) > 3]
164 3.027784
831 3.326404
Name: 2, dtype: float64
要找出所有值中大于3或者小于-3的行,可以对布尔值DataFrame使用any方法
data[(np.abs(data) > 3).any(1)]
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 164 | -1.156633 | -1.104849 | 3.027784 | -0.174189 |
| 624 | 0.054955 | -3.145678 | -0.778852 | -2.280175 |
| 664 | 0.031400 | 0.274078 | -0.924499 | -3.001159 |
| 692 | 1.397606 | 3.532333 | 0.127610 | 0.816575 |
| 725 | -1.336891 | 0.206885 | 0.677548 | 3.127593 |
| 831 | -0.406038 | 0.283722 | 3.326404 | -0.907127 |
限制值在-3到3之间
data[np.abs(data) > 3] = np.sign(data) * 3
data.describe()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| count | 1000.000000 | 1000.000000 | 1000.000000 | 1000.000000 |
| mean | 0.051415 | 0.024962 | -0.023283 | -0.022344 |
| std | 0.974445 | 0.999009 | 0.987664 | 0.970454 |
| min | -2.954484 | -3.000000 | -2.807353 | -3.000000 |
| 25% | -0.601312 | -0.606223 | -0.684640 | -0.666618 |
| 50% | 0.053944 | 0.025130 | -0.000365 | -0.032060 |
| 75% | 0.693812 | 0.688407 | 0.658130 | 0.626298 |
| max | 2.861130 | 3.000000 | 3.000000 | 3.000000 |
np.sign(data)根据数据中的值的正负分别生成1和-1
np.sign(data).head()
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 1.0 | -1.0 | 1.0 | 1.0 |
| 1 | -1.0 | 1.0 | 1.0 | 1.0 |
| 2 | 1.0 | -1.0 | -1.0 | 1.0 |
| 3 | 1.0 | 1.0 | 1.0 | -1.0 |
| 4 | 1.0 | 1.0 | -1.0 | -1.0 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号