Mysql底层索引技术
数据库的三大范式
1.范式:所有字段值都是不可分解的原子值---满足第一范式不一定满足第二范式
2.范式:也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。---满足第二范式不一定满足第三范式
3.范式:每一列数据都和主键直接相关,而不能间接相关。---所以第一范式,第二范式,第三范式都是有区别的。 如果想要不满足第二范式,应该是需要满足
一条sql语句的执行顺序
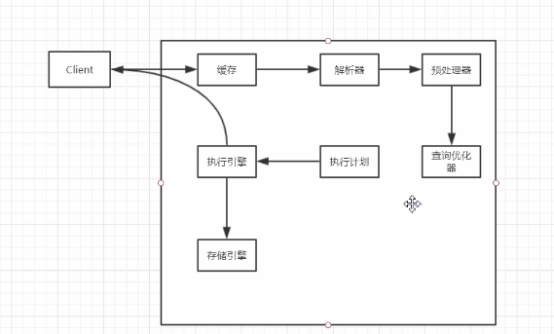
连接层:管理连接,权限认证
语法解析,语法分析
执行计划生成,索引选择
执行引擎 返回结果
存储数据,提供读写接口
一条修改语句要实现XA双提交,redo log bin log 日志。两个日志保证数据库数据的一致性。在服务器重启后,通过bin log日志进行数据恢复。
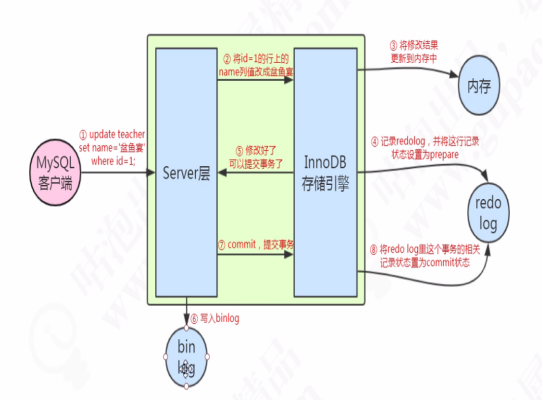
每张表都可使用不同的存储引擎
inndDB 以主键为索引来组织数据的存储,主键索引是聚集索引。
当没定义主键,先查找第一个没有NULL值唯一索引------聚集索引
自动生成一个ROWID 递增
InnoDB--辅助索引
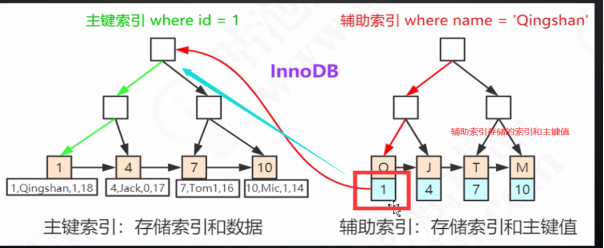
主键索引:存储索引和数据
辅助索引:存储的是索引和主键值,当查找到对应的索引和主键值后,再通过主键索引去查询对应的数据
数据库中的索引查找底层
中心思想:减少与磁盘的IO交互,读取速度要快。
二叉树网址
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
二叉查找数
左子树节点<父节点
右子数节点>父节点
平衡二叉树:左右子树深度差绝对值不能超过1,高瘦 ,与磁盘交互次数过多
多路平衡二叉树:B树 矮胖。 通过分裂和合并。比平衡二叉树中一个磁盘块中存储的比平衡二叉树多1 ,N个节点,度N+1.
B+Tree 加强版多路平衡查找树 ,节点上不会存储数据,在最终叶子结点才存储数据。叶子结点是一个有序的链式存储,左闭右开
此结构,高度为2能存储
一个page = 16 K 每一条记录为1K
一个叶子节点可以存放16条这样的记录
Int bigint 8 bytes 6 bytes = 14 bytes。
根节点和叶子结点,存放键值+指针
16384/14=1170个单元
高度2,1170个叶子节点
1170*16 = 18720
高度3 18720*1170 = 2000W 高度为3就能实现千万级数据存储,此时也仅需要与磁盘交互3次,减少。当进行区间查询时,底层叶子结点也是可以通过指针,当查23-36的时候,我们从根节点找到叶子结点23之后,不会在返回根节点重新查询,会通过指针去找下个数据
AVL树(平衡二叉树)
AVL在符合二叉查找数的条件下,还满足人和节点的两个字数的高度最大差为1.,避免极端情况下索引存储变成了一个线性链表结构。
B树(多路平衡查找树树)
一个节点上存储多个节点,减少树的深度,与磁盘的IO交互次数。
B+Tree的优势
B Tree 能解决的问题,B+Tree都能解决问题,只在叶子节点存储数据,根节点,只用来存储更多的节点和指针。
扫库、扫表能力更强
磁盘读写能力更强,与磁盘IO交互少
排序能力更强,区间查询
效率更加稳定,度多少,就与磁盘交互多少次。只从叶子节点获取值
离散度 count(distinct(字段)) :count(*) : 一个字段去重之后的总数。
离散度很低的字段上没必要创建索引,当我们重复添加一个重复的值 到B+树中,在搜索时,由于索引相同的很多,innoDB很可能会放弃索引,进行全表扫描
联合索引最左匹配:
当添加一个复合索引,比如alert table1 add index index_name (name,phone) ,
相当于创建了 index(name); index(name,phone);这两个索引,
创建之后,我们在查询数据后,当查询name and phone 的条件判断后,会使用该索引。
当位置调换后,phone and name后,也是能够使用此索引的,是因为Mysql内部优化器帮我们转成创建索引的顺序
单个的判断条件只能name能够使用 此索引,phone不能够使用
覆盖索引
回表:辅助索引查询出来索引和主键值,再去回表到主键索引去查询
覆盖索引:当select 数据列 包含在索引里面,索引覆盖了我想要查询的列。
