

数据采集第三次作业
作业1:
指定一个网站,爬取这个网站中的所有的所有图片,例如:中国气象网(http://www.weather.com.cn)。使用scrapy框架分别实现单线程和多线程的方式爬取。–务必控制总页数(学号尾数2位)、总下载的图片数量(尾数后3位)等限制爬取的措施。输出信息: 将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
代码与运行结果:
spider代码:
import scrapy
from urllib.parse import urljoin
from scrapy import Item, Field
class WeatherItem(Item):
image_urls = Field()
class Myspider31Spider(scrapy.Spider):
name = "myspider31"
allowed_domains = ["weather.com.cn"]
start_urls = ["https://weather.com.cn"]
def parse(self, response):
full_image_urls = []
image_urls = response.css('img::attr(src)').getall()
full_image_urls = [urljoin(response.url, img_url) for img_url in image_urls]
item = WeatherItem()
item['image_urls'] = full_image_urls
yield item
setting代码:
ITEM_PIPELINES = {
# "project31.pipelines.Project31Pipeline": 300,
'scrapy.pipelines.images.ImagesPipeline': 300
}
IMAGES_STORE='D:\数据集\数据采集实践3-1'
pipelines代码:
from itemadapter import ItemAdapter
class Project31Pipeline:
def process_item(self, item, spider):
return item
运行结果
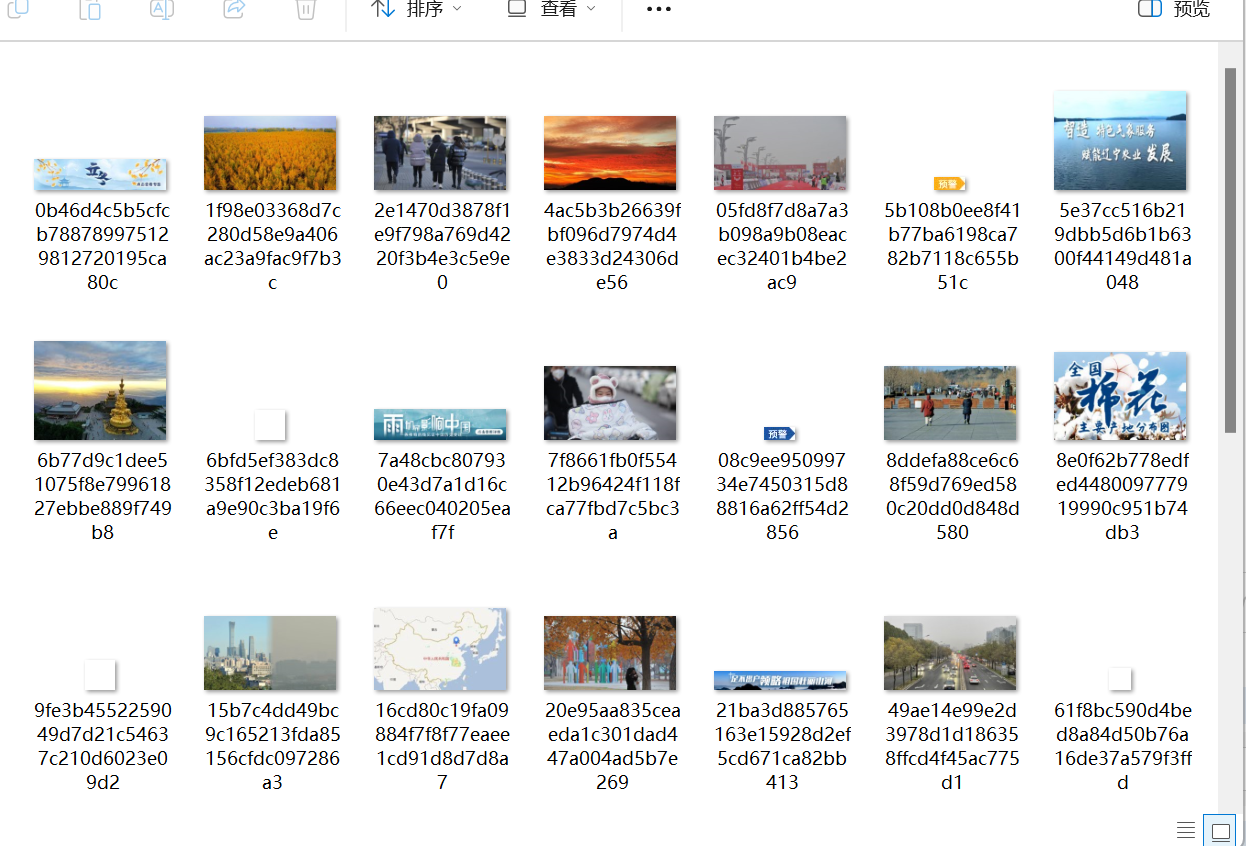
作业二
要求: 熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取股票相关信息。候选网站:东方财富网
代码与运行结果:
import scrapy
from demo2.items import StockItem
class StockSpider(scrapy.Spider):
name = "stock"
allowed_domains = ["www.eastmoney.com"]
start_urls = ["https://quote.eastmoney.com/center/gridlist.html#hs_a_board"]
def parse(self, response):
stocks = response.xpath("//tbody//tr")
for stock in stocks:
item = StockItem()
item['id'] = stock.xpath('.//td[position() = 1]//text()').extract_first()
item['code'] = stock.xpath('.//td[position() = 2]//text()').extract_first()
item['name'] = stock.xpath('.//td[position() = 3]//text()').extract_first()
item['newPrice'] = stock.xpath('.//td[position() = 5]//text()').extract_first()
item['price_change_amplitude'] = stock.xpath('.//td[position() = 6]//text()').extract_first()
item['price_change_Lines'] = stock.xpath('.//td[position() = 7]//text()').extract_first()
item['volume'] = stock.xpath('.//td[position() = 8]//text()').extract_first()
item['turnover'] = stock.xpath('.//td[position() = 9]//text()').extract_first()
item['amplitude'] = stock.xpath('.//td[position() = 10]//text()').extract_first()
item['highest'] = stock.xpath('.//td[position() = 11]//text()').extract_first()
item['lowest'] = stock.xpath('.//td[position() = 12]//text()').extract_first()
item['today'] = stock.xpath('.//td[position() = 13]//text()').extract_first()
item['yesterday'] = stock.xpath('.//td[position() = 14]//text()').extract_first()
yield item
import pymysql
host = '127.0.0.1'
port = 3306
user = 'root'
password = 'yabdylm'
database = 'pycharm'
class Demo2Pipeline:
def __init__(self):
self.con = pymysql.connect(host=host, port=port, user=user, password=password, database=database, charset='utf8mb4')
self.cursor = self.con.cursor()
self.cursor.execute(
"CREATE TABLE IF NOT EXISTS stockData (id Integer,code VARCHAR(255),name VARCHAR(255),newPrice VARCHAR(255),price_change_amplitude VARCHAR(255),price_change_Lines VARCHAR(255), volume VARCHAR(255),turnover VARCHAR(255),amplitude VARCHAR(255),highest VARCHAR(255),lowest VARCHAR(255),today VARCHAR(255),yesterday VARCHAR(255));")
def process_item(self, item, spider):
try:
id = item['id']
code = item['code']
name = item['name']
newPrice = item['newPrice']
price_change_amplitude = item['price_change_amplitude']
price_change_Lines = item['price_change_Lines']
volume = item['volume']
turnover = item['turnover']
amplitude = item['amplitude']
highest = item['highest']
lowest = item['lowest']
today = item['today']
yesterday = item['yesterday']
# 插入数据
self.cursor.execute("""
INSERT INTO stockData VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
""", (id, code, name, newPrice, price_change_amplitude, price_change_Lines, volume, turnover, amplitude,
highest, lowest, today, yesterday))
self.con.commit() # 提交事务
except Exception as e:
print(f"An error occurred: {e}")
return item
def __del__(self):
self.con.close()
运行结果:

作业三
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。候选网站:中国银行网:https://www.boc.cn/sourcedb/whpj/
代码与运行结果:
代码:
import scrapy
from demo3.items import BankItem
class BankSpider(scrapy.Spider):
name = "bank"
allowed_domains = ["www.boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
banks = response.xpath('//tbody[position() = 1]/tr')
for i in range(2,len(banks) - 2):
bank = banks[i]
item = BankItem()
item['Currency'] = bank.xpath(".//td[position() = 1]//text()").extract_first()
item['TBP'] = bank.xpath(".//td[position() = 2]//text()").extract_first()
item['CBP'] = bank.xpath(".//td[position() = 3]//text()").extract_first()
item['TSP'] = bank.xpath(".//td[position() = 4]//text()").extract_first()
item['CSP'] = bank.xpath(".//td[position() = 5]//text()").extract_first()
item['Time'] = bank.xpath(".//td[position() = 8]//text()").extract_first()
yield item
myDb.closeDB()
import pymysql
from scrapy.exceptions import DropItem
class BankPipeline:
def __init__(self):
# 这里填写您的数据库配置信息
self.host = 'localhost'
self.database = 'pycharm'
self.user = 'root'
self.password = 'yabdylm'
# 建立数据库连接
self.con = pymysql.connect(
host=self.host,
user=self.user,
password=self.password,
database=self.database,
charset='utf8mb4' # 使用 utf8mb4 字符集以支持全字符集
)
self.cursor = self.con.cursor()
def process_item(self, item, spider):
# SQL 插入语句
insert_sql = """
INSERT INTO bankData (Currency, TBP, CBP, TSP, CSP, Time)
VALUES (%s, %s, %s, %s, %s, %s)
"""
try:
# 执行 SQL 插入语句
self.cursor.execute(
insert_sql,
(
item['Currency'],
item['TBP'],
item['CBP'],
item['TSP'],
item['CSP'],
item['Time']
)
)
# 提交事务
self.con.commit()
except pymysql.Error as e:
# 如果发生错误,回滚事务
self.con.rollback()
raise DropItem(f"Error inserting row {item!r} into database: {e}")
return item
def close_spider(self, spider):
# 关闭数据库连接
self.cursor.close()
self.con.close()
运行结果:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步