
pytest系列——pytest_collection_modifyitems钩子函数修复参数化使用ids当测试用例描述有中文时控制台及报告中用例标题输出为Unicode编码问题
当我们对测试用例进行参数化时,使用@pytest.mark.parametrize的ids参数自定义测试用例的标题,当标题中有中文时,控制台和测试报告中会出现Unicode编码问题,这看起来特别像乱码,我们想让中文正常展示出来,需要用到pytest框架的钩子函数pytest_collection_modifyitems。
先看问题:
# file_name: test_parametrize.py
import pytest
def return_user():
return [('lwjnicole', '12345'), ('nicole', '123111')]
class Test_D:
@pytest.mark.parametrize("username,password",
return_user(),
ids=[
"输入正确的用户名、密码,登录成功",
"输入错误的用户名、密码,登录失败"
])
def test_login(self, username, password):
print("username = {}, password = {}".format(username, password))
assert username == "lwjnicole"
if __name__ == '__main__':
pytest.main(['-s', 'test_parametrize.py'])
编辑器中运行上面代码的结果:
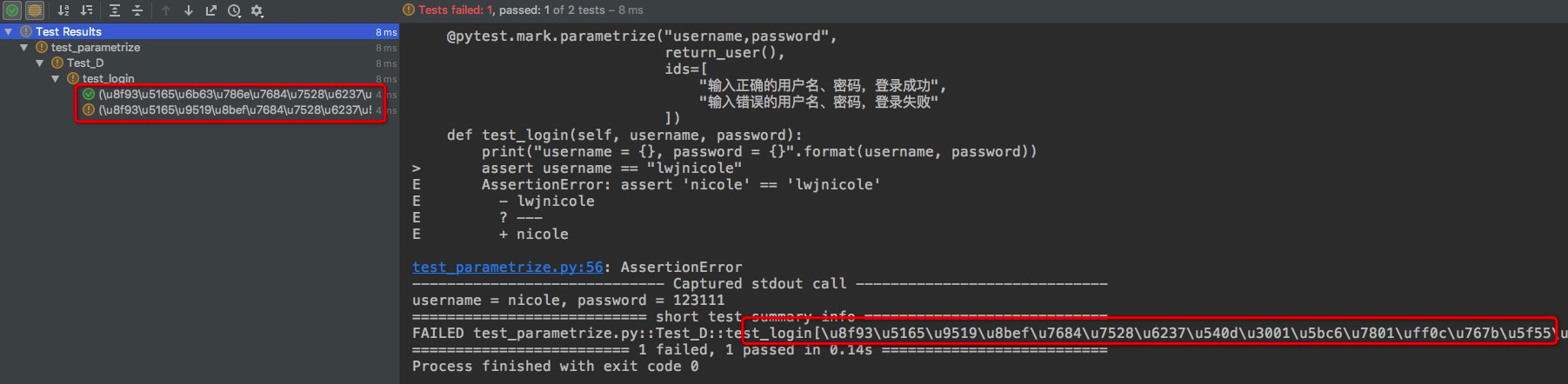
从上面的结果中可以看到用例的标题中文展示为Unicode编码。
使用钩子函数pytest_collection_modifyitems解决:
items 是一个存储 item 对象的列表, item 对象中有两个属性:一个是测试用例的路径 nodeid ,另一个是测试用例的用例名 name
在项目的根目录下,新建 conftest.py 文件,然后添加如下代码:
# file_name: conftest.py
def pytest_collection_modifyitems(items):
"""
测试用例收集完成时,将收集到的item的name和nodeid的中文显示在控制台上
:return:
"""
for item in items:
item.name = item.name.encode("utf-8").decode("unicode_escape")
item._nodeid = item.nodeid.encode("utf-8").decode("unicode_escape")
然后再次执行下测试用例,运行结果:
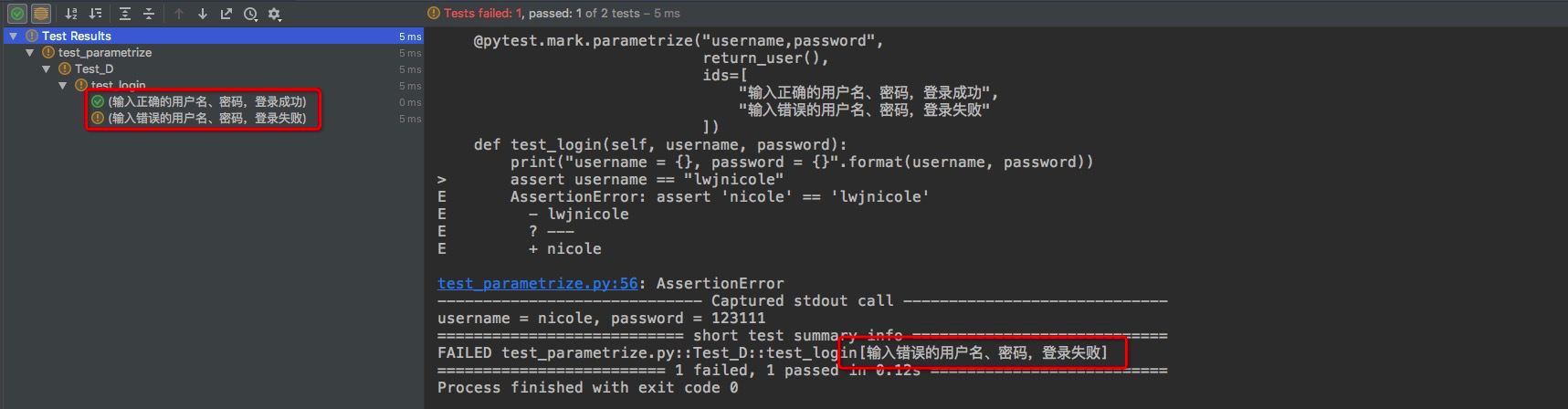
从上面的结果中可以看到用例的标题以中文正常展示了,问题得到解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号