字符串专题-后缀自动机
什么是自动机(useless)?
对于自动机/状态图不理解感觉也问题不大,直接把SAM理解成一个有向无环图就行了。
常见的状态机的定义:
自动机 = 状态集合(state)+状态转移(trans)+初始状态(没有入度的点)+一些终止状态(没有入度的点)+输入字符集(输入信号)
(1)确定性有限状态自动机(DFA),对于每一个输入,都有一个确定的状态与之对应。
(2)非确定性有限状态自动机(NFA),对于每一个输入,可能不止一个状态与之对应。
(3)DFA和NFA之间的转换(编译原理会学)
(4)SAM其实就是一个能识别所有S的子串的DFA。
什么是后缀自动机?
其实质就是DFA+识别所有S的子串的功能。
一、naive做法:
把S的n个后缀插入Trie里面即可(这样就能识别所有的子串,同时是一个DFA)。
二、最简状态后缀自动机
naive做法复杂度大,是因为每一个状态点只能表示一个子串。而SAM设计的状态可以包含更多的串,所以减少了状态数。
不知道为啥叫做最简状态SAM,难道是因为状态数是可以证明是最少的吗?(但是不是还有C-SAM,压缩版SAM的状态数更少吗)
最简状态后缀自动机的状态数是的, 状态转移数的。
后面就是重点内容:
(1)开局一些定义:
① S(w)表示子串w对应的后缀自动机上的状态。**重点
② 转移函数:trans(s,char)表示当前状态是s,接受char之后的状态(一条转移边),当trans为null时,表明没有这个转移
③ 扩展转移函数(为了方便证明一些定理而引入):Trans(s,str)表示当前状态是s,接受字符串str之后的状态。
④ Suf[i]、Suf[i:n]从i开始的后缀
(2)做出一些简单的分析:
1. 假设某个子串 t 属于某个状态s,又设t在str中出现的位置集合为:{},那么这个状态s必然能接受整个后缀:{}。即Trans(s,Suf[rm+1])不为Null。
2. 同时,如果另一个子串 t' 所在的状态是 s', 也只能接受:{},即s'和s的状态转移函数完全一致。从最简化DFA的角度来看,s'和s应该是同一个状态点(即t和t'末尾出现的位置集合{}相同,长度 不同,此时t'是t的后缀,或者t是t'的后缀)。
小总结:事实上,SAM使用的状态确实是如此定义的。(即SAM上的一个状态点,表示的是:末尾出现位置集合相同的,但是长度不同的一系列串)论文里定义为:end_pos集合,又或者是Right集合。
(3)新定义:Right(s)
Right(s)={},表示s状态代表的子串的出现位置的右端点集合。
所以根据定义:一个状态点的Right集合大小 = 这个状态点的字符串的出现次数。
(4)根据3定义的Right可以得到的推论:(Right集合就是end_pos集合)
(1)在最简状态后缀自动机中,所有节点的Right集合互不相同
(2)每个节点代表的串之间形成了后缀关系,比如:{a,ba,bba},短串是长串的后缀。
(3)每个节点代表的长度是一个连续的区间:
(4)考虑同在Right(s)位置,且长度为 MinL(s)-1 的串 t',设它所在的状态为 s',那么必然有Right(s)∈Right(s'), 即Right(s)是Right(s')的真子集
(5)Right集合的一些性质:
也就只有一个性质:不同状态点的Right集合要么相离,要么包含。
1. 相离是一定存在的,比如字符串ab中的{a},{b}明显属于不同的状态点,同时他们的Right集合完全相离。
2. 思考为什么只有真包含,没有相交的可能?
设r∈Right(s)∩Right(s'), 其中某个位置在两个集合中出现。
** 但是不同的状态在出现位置的长度区间一定是相离的(否则相交部分不知道该属于状态s,还是属于状态s')
根据这个推论,短字符串的Right集合 真包含 长字符串的Right集合。即不可能相交。
所以相离+包含关系,明显形成了一个树形结构。
根据这个性质,可以看出SAM的状态数为:O(2n),叶子数为n,总节点数等于2n-1(要加入n-1个连接点,把n个点连起来)。
(6)新新定义:SC树/Parent树/Link树 - 反正就是后缀链接树(suffix-chain-tree)
根据5中分析的来的性质,可以看出Right集合形成了一棵树,又叫后缀链接树。
定义:fa(s)表示状态s对应的Right集合在SC树上的父节点。root的父节点为空。
根据fa(s)形成了一条链,称为后缀链接 - suffix-chain,往上走,祖先是儿子的后缀。
这个图的每个节点代表这个节点的Right集合

(7)后缀链接树的性质:
(1)每个前缀所在状态两两不同。
(2)SC树一共有|S|个叶子节点,每个分别对应前缀S[1:i]所在的状态,即每个叶子对应一个前缀,且仅仅对应一个前缀(同时也不包含其它子串)。
(3)任意串w的后缀全部位于S(w)的后缀链接上。
(4)若某个状态s拥有char的转移边,那么它的祖先节点也一定拥有char的转移边
(5)每个状态s的Right(s)集合等于s的子树中叶子节点的集合(由图可知)
(6)对于任意状态节点s,MaxL(fa[s])+1==MinL(s)。所以在代码中,只需要记录fa[s]和MaxL[s]即可。
(7)所有终止状态(后面复习得时候发现忘了这个终止状态指什么)都能代表至少一个后缀(虽然SAM只有一个终止状态)
(8)Right集合等价于子树的概念,因此不需要单独维护。
(8)状态转移(简单证明边数是:的)
咕咕咕
如何构建后缀自动机(在线增量构造法)?
构建后缀自动机的关键,实际就是在维护 ①fa数组、②trans转移函数、③len数组(maxL(s)数组)、④sz[x]代表每个节点代表的子串们出现了次数【q节点分裂出nq的时候,sz[x]要赋值为0的,因为nq不代表一个RightPos,他只是一个合并了两个Right集合的分裂点】。
简洁思路如下:
(1)第一步,初始化:initSAM
空串的SAM是一个只有1号节点的SAM,同时它的所有转移边都是null。
定义last为SAM[1:i-1]中str[1:i-1]前缀所在的节点,这在下一次构造的时候需要用到,初始时last=root或者last=1。
(2)第二步,根据str[1:i-1]得到的SAM,加入字符str[i],构造得到str[1:i]对应的SAM
难点在于构造fa数组和trans转移函数,思考S[1:i]和S[1:i-1]两个SAM的区别:
- 首先,S[1:i]比S[1:i-1]多了i个后缀,也就是说我们要把这i个后缀插入到SAM里面去(确保这i个后缀能够表示出来,即fa、tran数组都是正确的)。
- 其次,我们从长到短依次考虑这i个后缀,我们发现,子串S[1:i]是一定不在SAM[1:i-1]里面的串,所以我们至少新增一个状态np来表示S[1:i]字符串【这个新状态的trans暂时为空,且赋值len[np]=i】。接下来需要判断fa[np]是什么,同时如何填补其它节点的trans函数
(先从寻找fa[np]的角度来思考)
我们考虑np节点,显然Right(i)是等于{i}的,因为S[1:i]只在i处结尾。那么我们找fa[np],根据后缀链接树上fa的定义,其实就是找一个最大的x,使得str[i-x,i]在str[1:i-1]中出现过。
所以str[i-x:i-1]在str[1:i-1]中同样出现过,我们从last节点往上跳,找到第一个的节点,这个就是我们要找的,同时我们设。
① 最简单的清形:如果我们找不到有这么一个节点存在trans(p, str[i])转移边,说明str[i]这个字符根本没出现过,我们直接令fa[np]=1即可。
② 否则,我们找到了一个节点,它存在转移边。
为什么我们执着于找这个x呢?因为str[x+1,i]是最长的,不仅在i处出现,而且在str[1:i-1]内部出现过的串。从fa的角度来看,其实也就是后缀链接树的角度来看,我们有len[fa[np]]=x+1。【因为len数组其实是maxlen,一个状态点np代表的串长范围是:[len[fa[np]]+1, len[np]]】 这也就是我们找x的重要原因:为了确定父节点的len大小。
但是这个时候,len[p']=x,len[q]=? 我们是否应该直接把fa[np]设置为q?显然是不行的。因为len[q]存在两种可能,len[q]=x+1或者len[q]>x+1。根据len[fa[np]]=x+1,第一种情况可以直接设置fa[np]=q,第二种情况需要进一步分析。
(再从填补trans的角度来思考)
由于所有新串都是str[1:i]的一个后缀,即:str[j:i]=str[j:i-1]+str[i],我们需要保证str[1:i-1]的所有后缀所在的节点s,都存在str[i]的转移边。同样是从last节点向上跑fa链【因为str[1:i-1]的后缀的状态就在last到root的链上,这个是根据后缀链接树性质得来的】。
① 最简单的情况:一直赋值trans(p, str[i])=np,直到1号节点。此时str[i]字符在str[1:i-1]中没有出现过,填补完毕。
② 否则,我们同样找到一个点,存在。已经存在转移边的节点应该怎么处理呢?处理方法同样跟据len[q]=x+1、len[q]>x+1两种情况进行讨论。
理解:其实fa的分析是从后缀链接树的角度进行分析的,trans函数是纯纯从字符串的DAG的角度进行分析的。
情况1:
根据上面的分析,len[q]=len[p']+1=x+1时,因为满足后缀链接树的性质,我们可以直接赋值fa[np]=q。- 即只以i结尾的字符串在np状态点表示,长度小于等于x+1的那些后缀,状态点归其它节点管(可能是np后缀链上的某个祖先)。
但是p'的trans函数应该怎么办呢? 答案是不需要变动。因为str[1:i-1]代表的SAM结构没有改变,trans函数不需要改变【这里其实和fa没什么关系,只和点是否分裂有关,比如说下一种情况有节点分裂,trans函数就需要变动了】
情况2:
节点分裂,为了满足len[fa[np]]=x+1的这么一个条件,我们把q节点分裂成q、nq两个节点。假设原来len[q]=y>x+1。其中nq代表了:[?, x+1]长度的这么一个区间,q代表了[x+2, y]长度的这么一个区间。
① 考虑fa数组怎么变化:
- 因为nq实际上是代表了原来q节点的比较短的那些字符串,所以分裂出来之后,仍然有:fa[nq]=fa[q]。
- nq符合了len[fa[np]]=x+1的条件,直接设置fa[np]=nq。
- 又因为nq代表的区间更加小,q代表了原来q节点比较长的字符串,同时Right(nq)包含Right(q)。从后缀连接树的角度来看(Right集合要么包含、要么相离),所以只能是fa[q]=nq了。
② 考虑trans数组怎么变化:
问题1:trans(nq)应该是什么?
- 因为nq是从原本q节点分裂出来的,转移的边应该是不变的,直接trans(nq)=trans(q)
问题2:在p'后缀链接上面的节点的trans函数是否会发生变化?
- 我们应该把那些trans(s, str[i])=q的节点改成trans(s, str[i])=nq。
- 原因:trans函数应该同时满足len数组的限制!因为len[p']=x,他不可能指向len[q]=y的这么一个节点,而且q节点表示的长度范围是:[x+2,y],至少要加两个字符才能达到,所以这条转移边不对。同理,在p'的后缀链接上,fa[p']、fa[fa[p']]等节点,它们的len比len[p']还要小,所以如果它们指向q节点,那么同样需要改成nq节点。
问题3:还有节点的trans函数是指向q节点的吗?
当然有,那些不在p'后缀链接上的节点,如果原来指向q,之后仍然可以指向q。假设这些节点为r,他们表示的长度范围是:[x+1,y-1]。如果不是很理解,建议画一下:aaabbba这个字符串的SAM,其中str[3]所在的节点一直指向str[4]的节点,这个就是属于r。
③ 考虑len[nq]等于什么:
明显等于x+1啊,就是len[p']+1啊。这个是分裂点的一个依据!
常见应用模板
(1)SAM模板 -(数组记得开两倍空间)
题意:求len*cnt的最大值,cnt为子串的出现数量,len为子串长度。
1. 如果对空间有要求,同时还要排好序,使用list版本(当且仅当字符集比较小、数据比较随机的时候有优势):至少在模板题上面,list版本比map、set版本都要快许多。
查看代码
struct SAM { // root = 1
int samcnt, fa[maxn], len[maxn], last;
int Psz[maxn], id[maxn], mxSuf[maxn];
list<PII> nxt[maxn]; // char, next
inline int newNode() {
++samcnt, fa[samcnt] = 0, nxt[samcnt].clear();
return samcnt; // 记得return
}
inline void initSAM() { samcnt = 0, last = newNode(), len[1] = 0; }
inline pair<list<PII>::iterator, bool> getNxt(int x, int c) {
if (!x) return make_pair(nxt[x].end(), true); // 特判 0
list<PII>::iterator it = nxt[x].begin();
for (; it != nxt[x].end() && it->first < c;) ++it;
return make_pair(it, (it != nxt[x].end() && it->first == c));
}
inline void addNxt(int x, list<PII>::iterator& it, int c, int nx) {
nxt[x].insert(it, make_pair(c, nx));
}
inline void add(int c) {
int np = newNode(), p = last;
last = np; // 重新赋值
Psz[np] = 1, len[np] = len[p] + 1;
auto pr = getNxt(p, c); // 获取p的转移iterator
for (; p && !pr.second; pr = getNxt(p = fa[p], c))
addNxt(p, pr.first, c, np);
if (!p) fa[np] = 1; // 直接连边
else {
int q = pr.first->second; // 获取c边的节点
if (len[q] == len[p] + 1) {
fa[np] = q;
} else {
int nq = newNode(); // q的分裂点nq
Psz[nq] = 0, len[nq] = len[p] + 1; // 长度是 p 的长度+1
fa[nq] = fa[q], nxt[nq] = nxt[q]; // 复制 q 转移函数以及父节点
for (; p && pr.first->second == q; pr = getNxt(p = fa[p], c))
pr.first->second = nq;
fa[q] = fa[np] = nq; // 最后记得重置 fa
}
}
}
void PreSort(int mxLen) { // 按len从小到大预处理拓扑序可以避免dfs
static int buc[maxn];
fill(buc, buc + mxLen, false);
for (int i = 1; i <= samcnt; i++) ++buc[len[i]];
for (int i = 1; i <= mxLen; i++) buc[i] += buc[i - 1];
for (int i = samcnt; i; i--) id[buc[len[i]]--] = i;
}
void calcMxSuf(char* str, int n) {
int x = 1, curlen = 0;
for (int i = 1; i <= n; i++) {
int c = str[i] - 'a';
auto it = getNxt(x, c);
while (x != 1 && !it.se) curlen = len[x = fa[x]], it = getNxt(x, c);
if (it.se) curlen++, x = it.fi->se;
mxSuf[i] = curlen;
}
}
void calcPosSz() {
for (int i = samcnt; i > 1; i--) // 记得使用id数组
Psz[fa[id[i]]] += Psz[id[i]];
}
} sam;2. 这里还有一个数组版本,对速度有要求(找最小出边的时候可以暴力找,反正比list快)的可以使用这个版本,,但是空间略大。如果要使用map就直接替换就行了(不建议使用set,因为速度和map基本一致,而且map和set的空间消耗还是很大的,不如直接list)。
对了,如果是数组写法,应该写成 nxt[maxn][26], 这样对缓存更友好(RMQ才是小维在前,这里根据局部性小维应该放在后面)。
查看代码
struct SAM { // root = 1
int samcnt, fa[maxn], len[maxn], last;
int nxt[maxn][26], Psz[maxn];
int lcs[maxn], mxSuf[maxn], id[maxn];
inline int newNode() {
++samcnt, fa[samcnt] = 0, me(nxt[samcnt], 0);
return samcnt; // 记得 return
}
inline void initSAM() { samcnt = 0, last = newNode(), Psz[1] = len[1] = 0; }
inline void add(int c) {
int np = newNode(), p = last;
last = np; // 重新赋值
Psz[np] = 1, lcs[np] = len[np] = len[p] + 1;
while (p && !nxt[p][c]) nxt[p][c] = np, p = fa[p];
if (!p) {
fa[np] = 1; // 直接连边
} else {
int q = nxt[p][c];
if (len[q] == len[p] + 1) {
fa[np] = q;
} else {
int nq = newNode(); // q的分裂点nq
Psz[nq] = 0, lcs[nq] = len[nq] = len[p] + 1; // 长度是 p 的长度+1
fa[nq] = fa[q]; // 复制 q 转移函数以及父节点
memcpy(nxt[nq], nxt[q], sizeof(nxt[q]));
for (; p && nxt[p][c] == q; p = fa[p]) nxt[p][c] = nq;
fa[q] = fa[np] = nq; // 最后记得重置 fa
}
}
}
void PreSort(int mxLen) { // 按len从小到大预处理拓扑序可以避免dfs
static int buc[maxn];
fill(buc, buc + mxLen, false);
for (int i = 1; i <= samcnt; i++) ++buc[len[i]];
for (int i = 1; i <= mxLen; i++) buc[i] += buc[i - 1];
for (int i = samcnt; i; i--) id[buc[len[i]]--] = i;
}
void calcMxSuf(char* str, int n) { // 计算str的每个前缀的最长匹配后缀
int x = 1, curlen = 0;
for (int i = 1; i <= n; i++) {
int c = str[i] - 'a';
while (x != 1 && !nxt[x][c]) curlen = len[x = fa[x]];;
if (nxt[x][c]) curlen++, x = nxt[x][c];
mxSuf[i] = curlen;
}
}
void calcPosSz() { // 计算Right集合大小
for (int i = samcnt; i > 1; i--) // 记得使用id数组
Psz[fa[id[i]]] += Psz[id[i]];
}
void Run(char* str, int n) { // 多串匹配 LCS
static int tmpmx[maxn];
int x = 1, curlen = 0;
for (int i = 1; i <= n; i++) {
int c = str[i] - 'a';
while (x != 1 && !nxt[x][c]) curlen = len[x = fa[x]];
if (nxt[x][c]) curlen++, x = nxt[x][c];
tmpmx[x] = max(tmpmx[x], curlen);
}
for (int i = samcnt; i > 1; i--) {
int x = id[i]; // 别忘了使用拓扑序
tmpmx[fa[x]] = max(tmpmx[x], tmpmx[fa[x]]);
lcs[x] = min(lcs[x], tmpmx[x]), tmpmx[x] = 0;
}
}
} sam;
// 使用细节:
// (1)每次使用之前必须initSAM
// (2)插入字符 sam.add(str[i] - 'a'); 记得SIGMA的范围。debug的代码:
查看代码
int vis[maxn];
void debug() { fill(vis, vis + samcnt, 0), print(); }
void print(int x = 1) {
if (vis[x]) return ;
vis[x] = 1;
const int SIGMA = 3;
cout << "Node x = " << x << " fa = " << fa[x] << " trans : ";
for (int i = 0; i < SIGMA; i++) cout << nxt[x][i] << " ";
cout << endl;
for (int i = 0; i < SIGMA; i++)
if (nxt[x][i]) print(nxt[x][i]);
}
(2)判断S是不是T的一个子串 / 求S的最长前缀在T中出现
这个问题可以 ①把S拼在T前面跑KMP; ②对S串建AC自动机,然后让T去跑(本质也是KMP); ③后缀数组
或者对T建SAM,然后让S去跑。如果跑到一个点之后没出边,说明S不在T中出现,这个时候求出了S的最长前缀。反之,S是T的子串。
(3)寻找(长度*出现次数)最大的子串 - 洛谷模板题 - 求出现次数(Right集合大小)
大体来说,跑一下后缀链接树,计算一下每个状态的Right数组大小就行了。
计算Right集合可以:①存下边集,直接dfs; ②记下du数组,跑拓扑排序;③根据len数组跑基数排序,得到的顺序和拓扑排序一致。
后面两种常数比较小,如果需要把后缀链接树建出来,也是可以使用第一种方法的(dfs的时候顺便求个和)。
(4)快速定位str[l,r]所在状态 - 葫芦授课
题意:多组询问,找出str[l,r]在str中出现了多少次。
先找到str[1,r]所在状态,这个可以提前用数组记录下来。然后在后缀链接上倍增就行了。
小总结:这也说明了,二元组(状态点,长度)对应了str的一个子串,两者是一一映射的。
(5)区间询问版 快速定位str[l,r]所在状态 - 葫芦授课
题意:给出一个字符串S,n=2e5,有2e5次查询,每次查询子串str[l,r]在子串str[L,R]中出现了多少次。
分析:就是求S(str[l,r])的Right集合里,有多少个数在区间[L+r-l,R]中。
做法①:SC树dfs序上建可持久化权值线段树。 - 大常数nlogn
做法②:离线树上权值线段树合并。 - 小常数nlogn
(6)本质不同子串数量 - 在线 生成魔咒
题意:每次添加一个字符,求操作之后本质不同子串数量。
本质不同子串数量 = 。
因为SAM的构建是在线的,而且只和新加入的节点的fa有关。所以直接累加就行。每次询问输出subNum即可。
查看代码
struct SAM { // root = 1
int samcnt, fa[maxn], len[maxn], last;
int mxSuf[maxn];
ll subNum;
list<PII> nxt[maxn]; // char, next
inline int newNode() {
++samcnt, fa[samcnt] = 0, nxt[samcnt].clear();
return samcnt; // 记得return
}
inline void initSAM() { subNum = samcnt = 0, last = newNode(), len[1] = 0; }
inline pair<list<PII>::iterator, bool> getNxt(int x, int c) {
if (!x) return make_pair(nxt[x].end(), true); // 特判 0
list<PII>::iterator it = nxt[x].begin();
for (; it != nxt[x].end() && it->first < c;) ++it;
return make_pair(it, (it != nxt[x].end() && it->first == c));
}
inline void addNxt(int x, list<PII>::iterator& it, int c, int nx) {
nxt[x].insert(it, make_pair(c, nx));
}
inline void add(int c) {
int np = newNode(), p = last;
last = np; // 重新赋值
len[np] = len[p] + 1;
auto pr = getNxt(p, c); // 获取p的转移iterator
for (; p && !pr.second; pr = getNxt(p = fa[p], c))
addNxt(p, pr.first, c, np);
if (!p)
fa[np] = 1, subNum += len[np]; // 直接连边
else {
int q = pr.first->second; // 获取c边的节点
if (len[q] == len[p] + 1) {
fa[np] = q, subNum += len[np] - len[q];
} else {
int nq = newNode(); // q的分裂点nq
len[nq] = len[p] + 1; // 长度是 p 的长度+1
fa[nq] = fa[q], nxt[nq] = nxt[q]; // 复制 q 转移函数以及父节点
for (; p && pr.first->second == q; pr = getNxt(p = fa[p], c))
pr.first->second = nq;
subNum += len[np] - len[nq];
fa[q] = fa[np] = nq; // 最后记得重置 fa
}
}
}
} sam;
// 每插入一个字符更新计算本质不同子串数量
(7)本质不同子串长度之和 - 在线
题意:每次在末尾添加一个字符,求操作之后,本质不同的子串的长度之和。
长度之和 =
这一题和上一题一样,因为是构建是在线的,所以也可以在线累加。
(8)字符串S在字符串T中第一次出现的位置 - 在线
题意:有两种操作,①在字符串T后面添加一个字符; ②查询S在T中第一次出现的位置。
分析:如果不是在线,那么可以跑一遍后缀链接树,得到每个节点的Right集合的最小值。
做法:每次插入一个字符串,会新添加一个节点np,设置mnRight[np]=i。按照这么来看,每个新添加的节点都会被设置mnRight。同时后续的位置肯定不如前面的优,所以直接赋值完之后不需要再取min。但是还有一类节点:clone节点,他们是复制q节点来的,设置mnRight[clone]=min(mnRight[q], mnRight[np]),但是发现mnRight[q]一定小于mnRight[np],所以直接赋值mnRight[clone]=mnRight[q]。每次插入一个字符之后,得到的SAM都是正确的,所以可以在线回复询问。
扩展:如果题目要求输出所有的出现位置,那么就只能遍历子树了(这玩意需要存在edge数组里)。复杂度是:,因为叶子数量是ans,整棵子树的大小为2*ans-1吧大概。
(9)最短没有出现过的子串【SAM上DP】
这玩意跟后缀链接树基本没什么联系了,就是纯纯在DAG上DP就行了,然后如果需要输出方案,那么记录一下转移边就行了。
令dp[i]为节点i走到不能再走的最短路径,那么转移就是 dp[x] = 1 + min(dp[v]), 最后答案就是dp[root]/dp[1]
(10)求多个字符串的LCS
问题1:只有两个串S、T的情形
这个问题转化为:对T的每个前缀T[1:i]求出最长的后缀T[j:i],使得T[j:i]是S的一个子串,然后再取一遍max。 - 这种做法是最简单的。
问题2:具有多个串S[i]的情形 - LINK、洛谷LINK
先对S[1]建SAM,然后每一个串在SAM上跑出每个节点的最大匹配长度,再用这个长度去和lcs数组取min。 - 80ms代码 LINK
(11)求多个字符串本质不同子串的交集、并集
① 求两个串S、T,求它们公共本质不同子串的交集:先对S建SAM,然后T在SAM上面跑,对于每个sam的节点,算出该节点的最长长度mxlen[x](经典Run函数)。最后答案就是:。
② 求两个串S、T,求它们本质不同子串的并集:并集,所以求出每个串的本质不同子串,减去上一问答案,容斥一下就行了。
习题
(1)Hacker【牛客多校签到题: SAM求匹配每个前缀的最长匹配后缀 + 单调队列优化DP】 - 中等
题意:给定n、m、k,和一个长度为n的数组a,给定模板串S。一共有k次询问,每次询问一个字符串T,输出: 其中满足T[l,r]是S的一个子串。
- 那么我们就这么做:首先先预处理出连续的极大的区间[l,r],这个可以用sam来做,即对于T的每个位置i,求出T[1:i]在S中出现的最长后缀。(注意,这个是SAM的经典操作),记这个最长距离为len[i]。然后我们记录pre[i]=i-len[i],显然这个pre[i]是单调不减的。这样我们就保证[pre[i], i]这个区间在S中出现
- 然后我们对a求一遍前缀和,对于每个位置i,求出[pre[i],i-1]中的最小值a[j],那么这个区间的答案就是a[i]-a[j]。 - 这个可以用单调队列求区间最小值做到。
查看代码
struct SAM { // root = 1
int samcnt, fa[maxn], sz[maxn], len[maxn], last;
int mxSuf[maxn];
list<PII> nxt[maxn]; // char, next
inline int newNode() {
++samcnt, fa[samcnt] = 0, nxt[samcnt].clear();
return samcnt; // 记得return
}
inline void initSAM() { samcnt = 0, last = newNode(), sz[1] = len[1] = 0; }
inline pair<list<PII>::iterator, bool> getNxt(int x, int c) {
if (!x) return make_pair(nxt[x].end(), true); // 特判 0
list<PII>::iterator it = nxt[x].begin();
for (; it != nxt[x].end() && it->first < c;) ++it;
return make_pair(it, (it != nxt[x].end() && it->first == c));
}
inline void addNxt(int x, list<PII>::iterator& it, int c, int nx) {
nxt[x].insert(it, make_pair(c, nx));
}
inline void add(int c) {
int np = newNode(), p = last;
last = np; // 重新赋值
sz[np] = 1, len[np] = len[p] + 1;
auto pr = getNxt(p, c); // 获取p的转移iterator
for (; p && !pr.second; pr = getNxt(p = fa[p], c))
addNxt(p, pr.first, c, np);
if (!p)
fa[np] = 1; // 直接连边
else {
int q = pr.first->second; // 获取c边的节点
if (len[q] == len[p] + 1) {
fa[np] = q;
} else {
int nq = newNode(); // q的分裂点nq
sz[nq] = 0, len[nq] = len[p] + 1; // 长度是 p 的长度+1
fa[nq] = fa[q], nxt[nq] = nxt[q]; // 复制 q 转移函数以及父节点
for (; p && pr.first->second == q; pr = getNxt(p = fa[p], c))
pr.first->second = nq;
fa[q] = fa[np] = nq; // 最后记得重置 fa
}
}
}
void calcMxSuf(char* str, int n) { // 对str每个前缀计算最长匹配后缀
int x = 1, curlen = 0;
for (int i = 1; i <= n; i++) {
int c = str[i] - 'a';
auto it = getNxt(x, c);
if (it.se) {
curlen++;
x = it.fi->se;
} else {
while (x != 1 && !it.se) x = fa[x], it = getNxt(x, c);
if (it.se) curlen = len[x] + 1, x = it.fi->se; // 跳next
else curlen = 0; // 上面必须在跳next之前计算len
}
mxSuf[i] = curlen;
}
}
} sam;
int n, m, k, q[maxn], ql, qr;
ll a[maxn];
char str[maxn];
void solve() {
cin >> n >> m >> k >> str + 1;
for (int i = 1; i <= m; i++) cin >> a[i], a[i] += a[i - 1];
sam.initSAM();
for (int i = 1; i <= n; i++) sam.add(str[i] - 'a');
while (k--) {
cin >> str + 1;
sam.calcMxSuf(str, m);
q[ql = qr = 1] = 0;
ll ans = 0;
for (int i = 1; i <= m; i++) {
while (ql <= qr && i - sam.mxSuf[i] > q[ql]) ql++;
if (ql <= qr) ans = max(ans, a[i] - a[q[ql]]);
while (ql <= qr && a[i] < a[q[qr]]) qr--;
q[++qr] = i;
}
cout << ans << "\n";
}
}
(2)NSUBSTR【单调性后缀缀值 - 求长度为x的子串出现的最多次数】 - 简单
题意:给一个250000长的str,定义cnt(substr)为substr在str中出现次数,G[x]为。求:G[1:n]。
思路:求出str的后缀链接树,对于每个节点,用|Right(x)|去更新的最值。但是无脑线段树会TLE。又发现如果i<j,一定有G[i]>=G[J],即满足单调性,所以直接用|Right(x)|更新L[x]这一个位置,然后再取一遍后缀最值就行了(葫芦说可以理解为向左推懒标记)。
用SA来做:跑出ht数组,然后用并查集连接,从大到小枚举长度x,G[x]就是最大并查集的大小。
(3)#1465 : 后缀自动机五·重复旋律8 CF235C Cyclical Quest - 洛谷【直接在SAM上面跑】 - 中等 - 无法提交?
题意:给一个长为100000的字符串S,有q次询问,每次询问一个T,求出S有多少个子串和T是循环等价的。【S的子串以位置l、r进行区分】
思路:做完这道题,对SAM的一些套路又多了理解。
主要结论:把一个串T直接在S的SAM上面跑,那么可以求出T的每个前缀能在S中匹配的最长后缀长度。
根据这个东西呢,我们直接把每个T复制一遍变成TT,然后计算TT每个前缀的最长后缀。那么这个串的答案就是
麻了,这题竟然还有一个大坑!!!!!!因为只需要匹配完之后长度大于等于n,所以不仅仅是在转移的时候跳后缀链!如果当前节点的curlen>=n,同时len[fa[x]]>=n-1,那么向上跳,可以使得Right集合更加大,从而求出真正的答案。 我吐了,真是老六啊。【使用vis数组标记ID来防止重复计数就不多说了吧】
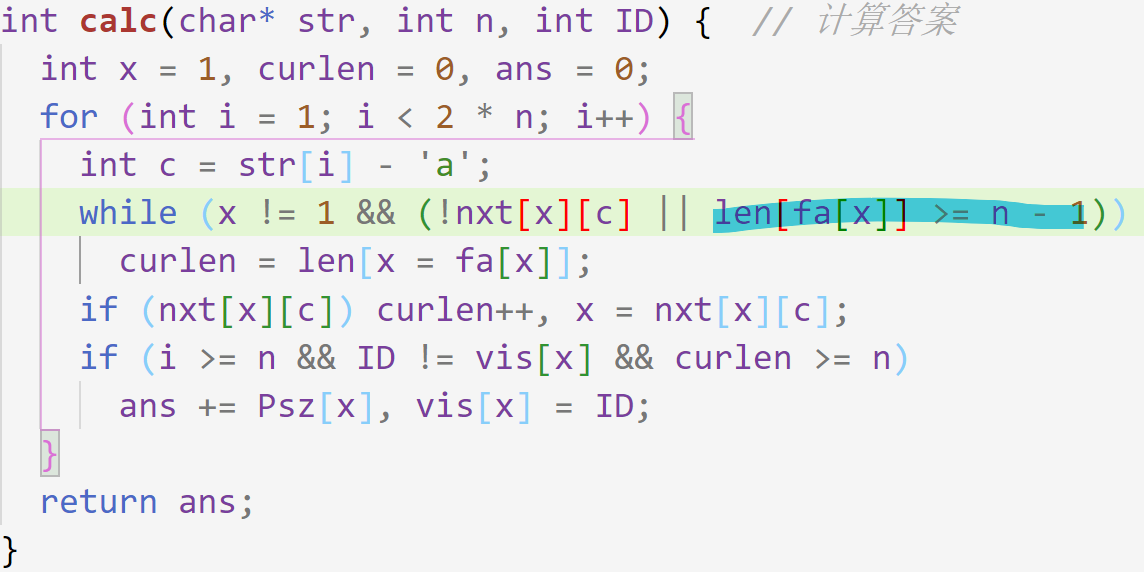
(4)#1466 : 后缀自动机六·重复旋律9【字典序第k小的子串 + 博弈 + DAG上求SG函数】 - 中等
题意:大师从A串里选一个子串S,再从B串中选一个子串T,Alice和Bob轮流往S或者T后面添加一个字符,需要保证S、T仍然是A、B的子串。不能操作者失败。求二元组(S,T)第K小的字符串对。
思路:
- 先对A、B建SAM,然后求出B中有多少个子串是SG=1,多少个SG=0的,记为cnt0、cnt1。
- 然后我们从小到大遍历A的SAM,如果遍历到A中的一个SG=1的点,那么B中应该选择一个SG=0的点,如果K仍然大于cnt0,则令K-=cnt0;如果A中遍历到一个SG=0的店,B中应该选择一个SG=1的点,如果K大于cnt1,直接令K-=cnt1,然后继续在A上面跑。
- 如果K<=cnt0或者K<=cnt1(upd:没理解错得话,应该只有K<=cnt1吧),说明此时遍历到的A的子串就是答案,然后B中字典序第K小的SG=0或者SG=1的节点就是答案。
- 如果跑完没有找到答案,那么输出NO。
启发: 如何遍历SAM、如何对SAM的DAG做DP。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具