
深入理解浏览器的缓存机制
一、前言
缓存可以说是性能优化中简单高效的一种优化方式了。一个优秀的缓存策略可以缩短网页请求资源的距离,减少延迟,并且由于缓存文件可以重复利用,还可以减少带宽,降低网络负荷。
对于一个数据请求来说,可以分为发起网络请求、后端处理、浏览器响应三个步骤。浏览器缓存可以帮助我们在第一和第三步骤中优化性能。比如说直接使用缓存而不发起请求,或者发起了请求但后端存储的数据和前端一致,那么就没有必要再将数据回传回来,这样就减少了响应数据。
接下来的内容中我们将通过缓存位置、缓存策略以及实际场景应用缓存策略来探讨浏览器缓存机制。
如需获取思维导图或想阅读更多优质文章请猛戳GitHub博客
二、缓存位置
从缓存位置上来说分为四种,并且各自有优先级,当依次查找缓存且都没有命中的时候,才会去请求网络。
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
1.Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能。使用 Service Worker的话,传输协议必须为 HTTPS。因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全。Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的。
Service Worker 实现缓存功能一般分为三个步骤:首先需要先注册 Service Worker,然后监听到 install 事件以后就可以缓存需要的文件,那么在下次用户访问的时候就可以通过拦截请求的方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据。
当 Service Worker 没有命中缓存的时候,我们需要去调用 fetch 函数获取数据。也就是说,如果我们没有在 Service Worker 命中缓存的话,会根据缓存查找优先级去查找数据。但是不管我们是从 Memory Cache 中还是从网络请求中获取的数据,浏览器都会显示我们是从 Service Worker 中获取的内容。
2.Memory Cache
Memory Cache 也就是内存中的缓存,主要包含的是当前中页面中已经抓取到的资源,例如页面上已经下载的样式、脚本、图片等。读取内存中的数据肯定比磁盘快,内存缓存虽然读取高效,可是缓存持续性很短,会随着进程的释放而释放。 一旦我们关闭 Tab 页面,内存中的缓存也就被释放了。
那么既然内存缓存这么高效,我们是不是能让数据都存放在内存中呢?
这是不可能的。计算机中的内存一定比硬盘容量小得多,操作系统需要精打细算内存的使用,所以能让我们使用的内存必然不多。
当我们访问过页面以后,再次刷新页面,可以发现很多数据都来自于内存缓存
内存缓存中有一块重要的缓存资源是preloader相关指令(例如<link rel="prefetch">)下载的资源。总所周知preloader的相关指令已经是页面优化的常见手段之一,它可以一边解析js/css文件,一边网络请求下一个资源。
需要注意的事情是,内存缓存在缓存资源时并不关心返回资源的HTTP缓存头Cache-Control是什么值,同时资源的匹配也并非仅仅是对URL做匹配,还可能会对Content-Type,CORS等其他特征做校验。
3.Disk Cache
Disk Cache 也就是存储在硬盘中的缓存,读取速度慢点,但是什么都能存储到磁盘中,比之 Memory Cache 胜在容量和存储时效性上。
在所有浏览器缓存中,Disk Cache 覆盖面基本是最大的。它会根据 HTTP Herder 中的字段判断哪些资源需要缓存,哪些资源可以不请求直接使用,哪些资源已经过期需要重新请求。并且即使在跨站点的情况下,相同地址的资源一旦被硬盘缓存下来,就不会再次去请求数据。绝大部分的缓存都来自 Disk Cache,关于 HTTP 的协议头中的缓存字段,我们会在下文进行详细介绍。
浏览器会把哪些文件丢进内存中?哪些丢进硬盘中?
关于这点,网上说法不一,不过以下观点比较靠得住:
- 对于大文件来说,大概率是不存储在内存中的,反之优先
- 当前系统内存使用率高的话,文件优先存储进硬盘
4.Push Cache
Push Cache(推送缓存)是 HTTP/2 中的内容,当以上三种缓存都没有命中时,它才会被使用。它只在会话(Session)中存在,一旦会话结束就被释放,并且缓存时间也很短暂,在Chrome浏览器中只有5分钟左右,同时它也并非严格执行HTTP头中的缓存指令。
Push Cache 在国内能够查到的资料很少,也是因为 HTTP/2 在国内不够普及。这里推荐阅读Jake Archibald的 HTTP/2 push is tougher than I thought 这篇文章,文章中的几个结论:
- 所有的资源都能被推送,并且能够被缓存,但是 Edge 和 Safari 浏览器支持相对比较差
- 可以推送 no-cache 和 no-store 的资源
- 一旦连接被关闭,Push Cache 就被释放
- 多个页面可以使用同一个HTTP/2的连接,也就可以使用同一个Push Cache。这主要还是依赖浏览器的实现而定,出于对性能的考虑,有的浏览器会对相同域名但不同的tab标签使用同一个HTTP连接。
- Push Cache 中的缓存只能被使用一次
- 浏览器可以拒绝接受已经存在的资源推送
- 你可以给其他域名推送资源
如果以上四种缓存都没有命中的话,那么只能发起请求来获取资源了。
那么为了性能上的考虑,大部分的接口都应该选择好缓存策略,通常浏览器缓存策略分为两种:强缓存和协商缓存,并且缓存策略都是通过设置 HTTP Header 来实现的。
三、缓存过程分析
浏览器与服务器通信的方式为应答模式,即是:浏览器发起HTTP请求 – 服务器响应该请求,那么浏览器怎么确定一个资源该不该缓存,如何去缓存呢?浏览器第一次向服务器发起该请求后拿到请求结果后,将请求结果和缓存标识存入浏览器缓存,浏览器对于缓存的处理是根据第一次请求资源时返回的响应头来确定的。具体过程如下图:
由上图我们可以知道:
-
浏览器每次发起请求,都会先在浏览器缓存中查找该请求的结果以及缓存标识
-
浏览器每次拿到返回的请求结果都会将该结果和缓存标识存入浏览器缓存中
以上两点结论就是浏览器缓存机制的关键,它确保了每个请求的缓存存入与读取,只要我们再理解浏览器缓存的使用规则,那么所有的问题就迎刃而解了,本文也将围绕着这点进行详细分析。为了方便大家理解,这里我们根据是否需要向服务器重新发起HTTP请求将缓存过程分为两个部分,分别是强缓存和协商缓存。
四、强缓存
强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的Network选项中可以看到该请求返回200的状态码,并且Size显示from disk cache或from memory cache。强缓存可以通过设置两种 HTTP Header 实现:Expires 和 Cache-Control。
1.Expires
缓存过期时间,用来指定资源到期的时间,是服务器端的具体的时间点。也就是说,Expires=max-age + 请求时间,需要和Last-modified结合使用。Expires是Web服务器响应消息头字段,在响应http请求时告诉浏览器在过期时间前浏览器可以直接从浏览器缓存取数据,而无需再次请求。
Expires 是 HTTP/1 的产物,受限于本地时间,如果修改了本地时间,可能会造成缓存失效。Expires: Wed, 22 Oct 2018 08:41:00 GMT表示资源会在 Wed, 22 Oct 2018 08:41:00 GMT 后过期,需要再次请求。
2.Cache-Control
在HTTP/1.1中,Cache-Control是最重要的规则,主要用于控制网页缓存。比如当Cache-Control:max-age=300时,则代表在这个请求正确返回时间(浏览器也会记录下来)的5分钟内再次加载资源,就会命中强缓存。
Cache-Control 可以在请求头或者响应头中设置,并且可以组合使用多种指令:
public:所有内容都将被缓存(客户端和代理服务器都可缓存)。具体来说响应可被任何中间节点缓存,如 Browser <-- proxy1 <-- proxy2 <-- Server,中间的proxy可以缓存资源,比如下次再请求同一资源proxy1直接把自己缓存的东西给 Browser 而不再向proxy2要。
private:所有内容只有客户端可以缓存,Cache-Control的默认取值。具体来说,表示中间节点不允许缓存,对于Browser <-- proxy1 <-- proxy2 <-- Server,proxy 会老老实实把Server 返回的数据发送给proxy1,自己不缓存任何数据。当下次Browser再次请求时proxy会做好请求转发而不是自作主张给自己缓存的数据。
no-cache:客户端缓存内容,是否使用缓存则需要经过协商缓存来验证决定。表示不使用 Cache-Control的缓存控制方式做前置验证,而是使用 Etag 或者Last-Modified字段来控制缓存。需要注意的是,no-cache这个名字有一点误导。设置了no-cache之后,并不是说浏览器就不再缓存数据,只是浏览器在使用缓存数据时,需要先确认一下数据是否还跟服务器保持一致。
no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存
max-age:max-age=xxx (xxx is numeric)表示缓存内容将在xxx秒后失效
s-maxage(单位为s):同max-age作用一样,只在代理服务器中生效(比如CDN缓存)。比如当s-maxage=60时,在这60秒中,即使更新了CDN的内容,浏览器也不会进行请求。max-age用于普通缓存,而s-maxage用于代理缓存。s-maxage的优先级高于max-age。如果存在s-maxage,则会覆盖掉max-age和Expires header。
max-stale:能容忍的最大过期时间。max-stale指令标示了客户端愿意接收一个已经过期了的响应。如果指定了max-stale的值,则最大容忍时间为对应的秒数。如果没有指定,那么说明浏览器愿意接收任何age的响应(age表示响应由源站生成或确认的时间与当前时间的差值)。
min-fresh:能够容忍的最小新鲜度。min-fresh标示了客户端不愿意接受新鲜度不多于当前的age加上min-fresh设定的时间之和的响应。
从图中我们可以看到,我们可以将多个指令配合起来一起使用,达到多个目的。比如说我们希望资源能被缓存下来,并且是客户端和代理服务器都能缓存,还能设置缓存失效时间等等。
3.Expires和Cache-Control两者对比
其实这两者差别不大,区别就在于 Expires 是http1.0的产物,Cache-Control是http1.1的产物,两者同时存在的话,Cache-Control优先级高于Expires;在某些不支持HTTP1.1的环境下,Expires就会发挥用处。所以Expires其实是过时的产物,现阶段它的存在只是一种兼容性的写法。
强缓存判断是否缓存的依据来自于是否超出某个时间或者某个时间段,而不关心服务器端文件是否已经更新,这可能会导致加载文件不是服务器端最新的内容,那我们如何获知服务器端内容是否已经发生了更新呢?此时我们需要用到协商缓存策略。
五、协商缓存
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程,主要有以下两种情况:
-
协商缓存生效,返回304和Not Modified
-
协商缓存失效,返回200和请求结果
协商缓存可以通过设置两种 HTTP Header 实现:Last-Modified 和 ETag 。
1.Last-Modified和If-Modified-Since
浏览器在第一次访问资源时,服务器返回资源的同时,在response header中添加 Last-Modified的header,值是这个资源在服务器上的最后修改时间,浏览器接收后缓存文件和header;
Last-Modified: Fri, 22 Jul 2016 01:47:00 GMT
浏览器下一次请求这个资源,浏览器检测到有 Last-Modified这个header,于是添加If-Modified-Since这个header,值就是Last-Modified中的值;服务器再次收到这个资源请求,会根据 If-Modified-Since 中的值与服务器中这个资源的最后修改时间对比,如果没有变化,返回304和空的响应体,直接从缓存读取,如果If-Modified-Since的时间小于服务器中这个资源的最后修改时间,说明文件有更新,于是返回新的资源文件和200
但是 Last-Modified 存在一些弊端:
- 如果本地打开缓存文件,即使没有对文件进行修改,但还是会造成 Last-Modified 被修改,服务端不能命中缓存导致发送相同的资源
- 因为 Last-Modified 只能以秒计时,如果在不可感知的时间内修改完成文件,那么服务端会认为资源还是命中了,不会返回正确的资源
既然根据文件修改时间来决定是否缓存尚有不足,能否可以直接根据文件内容是否修改来决定缓存策略?所以在 HTTP / 1.1 出现了 ETag 和If-None-Match
2.ETag和If-None-Match
Etag是服务器响应请求时,返回当前资源文件的一个唯一标识(由服务器生成),只要资源有变化,Etag就会重新生成。浏览器在下一次加载资源向服务器发送请求时,会将上一次返回的Etag值放到request header里的If-None-Match里,服务器只需要比较客户端传来的If-None-Match跟自己服务器上该资源的ETag是否一致,就能很好地判断资源相对客户端而言是否被修改过了。如果服务器发现ETag匹配不上,那么直接以常规GET 200回包形式将新的资源(当然也包括了新的ETag)发给客户端;如果ETag是一致的,则直接返回304知会客户端直接使用本地缓存即可。
3.两者之间对比:
- 首先在精确度上,Etag要优于Last-Modified。
Last-Modified的时间单位是秒,如果某个文件在1秒内改变了多次,那么他们的Last-Modified其实并没有体现出来修改,但是Etag每次都会改变确保了精度;如果是负载均衡的服务器,各个服务器生成的Last-Modified也有可能不一致。
- 第二在性能上,Etag要逊于Last-Modified,毕竟Last-Modified只需要记录时间,而Etag需要服务器通过算法来计算出一个hash值。
- 第三在优先级上,服务器校验优先考虑Etag
六、缓存机制
强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,返回200,重新返回资源和缓存标识,再存入浏览器缓存中;生效则返回304,继续使用缓存。具体流程图如下:
看到这里,不知道你是否存在这样一个疑问:如果什么缓存策略都没设置,那么浏览器会怎么处理?
对于这种情况,浏览器会采用一个启发式的算法,通常会取响应头中的 Date 减去 Last-Modified 值的 10% 作为缓存时间。
七、实际场景应用缓存策略
1.频繁变动的资源
Cache-Control: no-cache
对于频繁变动的资源,首先需要使用Cache-Control: no-cache 使浏览器每次都请求服务器,然后配合 ETag 或者 Last-Modified 来验证资源是否有效。这样的做法虽然不能节省请求数量,但是能显著减少响应数据大小。
2.不常变化的资源
Cache-Control: max-age=31536000
通常在处理这类资源时,给它们的 Cache-Control 配置一个很大的 max-age=31536000 (一年),这样浏览器之后请求相同的 URL 会命中强制缓存。而为了解决更新的问题,就需要在文件名(或者路径)中添加 hash, 版本号等动态字符,之后更改动态字符,从而达到更改引用 URL 的目的,让之前的强制缓存失效 (其实并未立即失效,只是不再使用了而已)。
在线提供的类库 (如 jquery-3.3.1.min.js, lodash.min.js 等) 均采用这个模式。
八、用户行为对浏览器缓存的影响
所谓用户行为对浏览器缓存的影响,指的就是用户在浏览器如何操作时,会触发怎样的缓存策略。主要有 3 种:
- 打开网页,地址栏输入地址: 查找 disk cache 中是否有匹配。如有则使用;如没有则发送网络请求。
- 普通刷新 (F5):因为 TAB 并没有关闭,因此 memory cache 是可用的,会被优先使用(如果匹配的话)。其次才是 disk cache。
- 强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有
Cache-control: no-cache(为了兼容,还带了Pragma: no-cache),服务器直接返回 200 和最新内容。
参考文章
- 浅谈web缓存
- web缓存机制
- 彻底理解浏览器的缓存机制
- 前端面试之道
- 一文读懂前端缓存
- A Tale of Four Caches
- HTTP/2 push is tougher than I thought
- 设计一个无懈可击的浏览器缓存方案:关于思路,细节,ServiceWorker,以及HTTP/2
<div id="article_content" class="article_content clearfix">
<div class="article-copyright">
<span class="creativecommons">
<a rel="license" href="http://creativecommons.org/licenses/by-sa/4.0/">
</a>
<span>
版权声明:本文为博主原创文章,遵循<a href="http://creativecommons.org/licenses/by-sa/4.0/" target="_blank" rel="noopener"> CC 4.0 BY-SA </a>版权协议,转载请附上原文出处链接和本声明。 </span>
<div class="article-source-link2222">
本文链接:<a href="https://blog.csdn.net/LANNY8588/article/details/85054338">https://blog.csdn.net/LANNY8588/article/details/85054338</a>
</div>
</span>
</div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-d284373521.css">
<div id="content_views" class="markdown_views prism-atom-one-dark">
<!-- flowchart 箭头图标 勿删 -->
<svg xmlns="http://www.w3.org/2000/svg" style="display: none;">
<path stroke-linecap="round" d="M5,0 0,2.5 5,5z" id="raphael-marker-block" style="-webkit-tap-highlight-color: rgba(0, 0, 0, 0);"></path>
</svg>
<h3><a id="_0"></a>缓存系统之浏览器缓存</h3>
缓存的分类:
客户端:
浏览器缓存,目的就是加速各种静态资源的访问。对于静态资源来说,浏览器不会缓存html页面的,所以你每次改完html的页面的时候,html都是改完立即生效的,不存在什么有缓存导致页面不对的问题。浏览器缓存的东西有图片,css和js。这些资源将在缓存失效前调用的时候调用浏览器的缓存内容
服务端:
又分为 代理服务器缓存 和 反向代理服务器缓存(也叫网关缓存,比如 Nginx反向代理、Squid等),其实广泛使用的 CDN 也是一种服务 端缓存,目的都是让用户的请求走”捷径“,并且都是缓存图片、文件等静态资源
浏览器缓存:
测试知道了解后有什么好处:前端展示不是最新的页面,可以自己分析判断,而不需要每次傻傻的去清理缓存。
浏览器缓存的目的:
第一:避免了频繁请求,节省带宽流量。
第二:加快了用户访问网页的速度。
第三:减小了服务端的压力。
浏览器缓存流程:
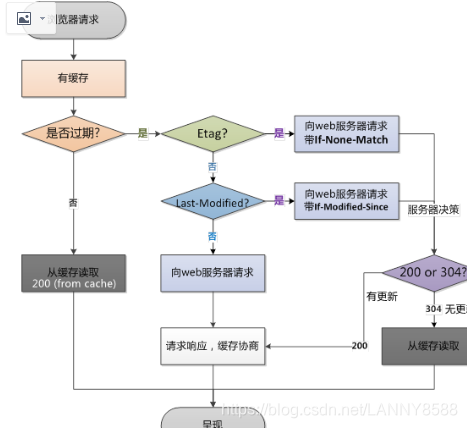
1.查看缓存
判断是否有缓存:
首先先要理解怎么存放存放在哪里:
chrome的浏览器(旧版):
chrome://chrome-urls/ 谷歌浏览器输入,点击cache链接就可
火狐浏览器 about:cache?storage=disk
本地chrome的浏览器缓存存放地方一般实在这里:
C:\Users\用户名\AppData\Local\Google\Chrome\User Data\Default\Cache
如下图:
这样的话不容易看懂,安装下专业的工具Chrome cache View工具:

2.缓存判断
根据上面的流程图看,首先是判断这个缓存是否过期,那怎么去判断
一般情况下,浏览器发出的所有 HTTP 请求会首先被路由到浏览器的缓存。
A.缓存未过期,直接读取数据
以百度的为例:
打开百度,筛选bd_logo,如下图,第一次请求的时候是大部分是200返回码,因为是没有缓存

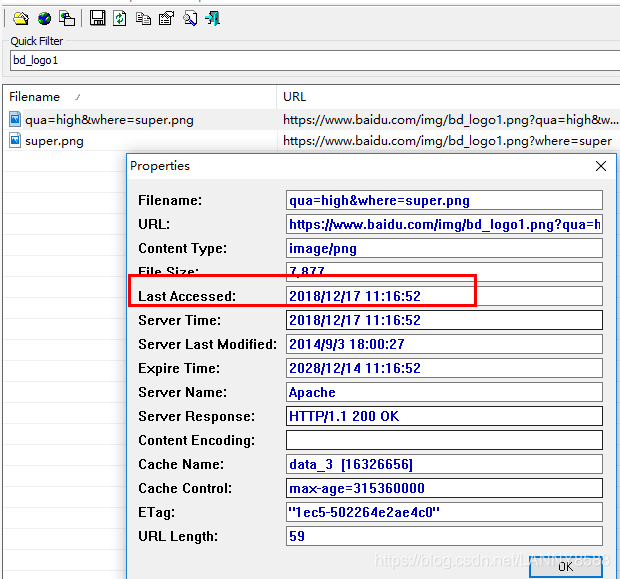
再次刷新,返回200,显示读取的是缓存:

问题:为什么是200。
浏览器中判断是否过期一般由expires以及cache-control字段来判断,如果两者同时存在,则是cache-control max-age覆盖expire。
从以上可以看出,max-age=315360000,cache-control的时间为十年,所以,如果有缓存,这条信息会一直从缓存中读取。
B缓存过期:
打开新浪网为例,
输入goldenstock.js
可以看出有效期是2分钟,前两分钟都是返回200
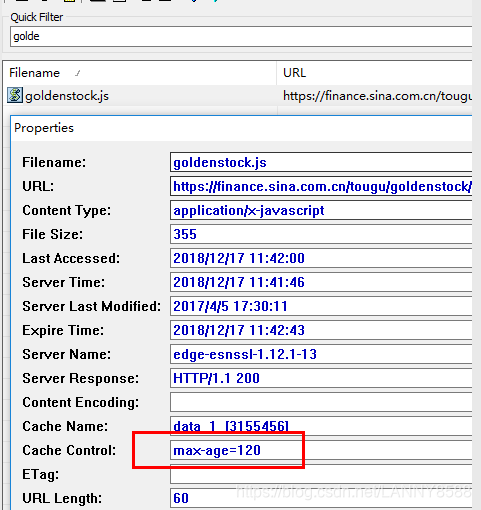

超过两分钟后,重新刷新,如下图,304了。

问题:为什么是304.
根据上面的流程,
先看缓存是否过期,缓存数据是存两分钟,两分钟过后,缓存失效,查看eatg标记,没有的话,找last-modify(表明请求的资源上次的修改时间),请求的时候加上if-modif-since(客户端保留的资源上次的修改时间) .通过对比时间,如果是一致的话,就返回304,读取本地缓存,如果不一致,返回200,重新读取
last-modify:

if-modif-since
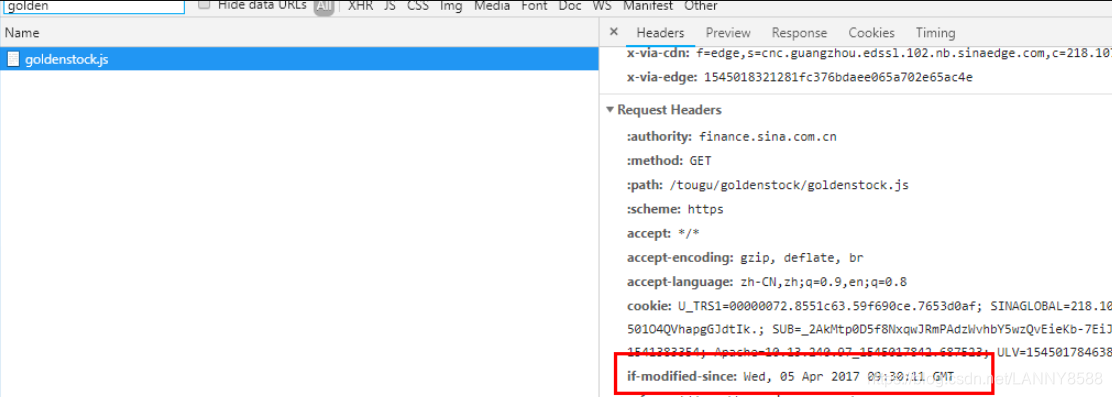
2.1.
打开新浪网为例,
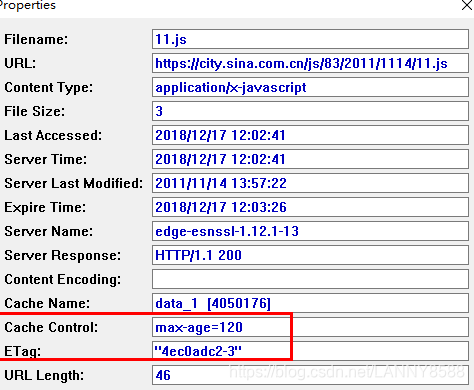
输入11.js。
同理以上,结合流程,含有etag资源的内容标识。(不唯一,通常为文件的md5或者一段hash值,只要保证写入和验证时的方法一致即可),可以看出有效期是2分钟,前两分钟都是返回200

etag:

If-None-Match: 客户端保留的资源内容标识
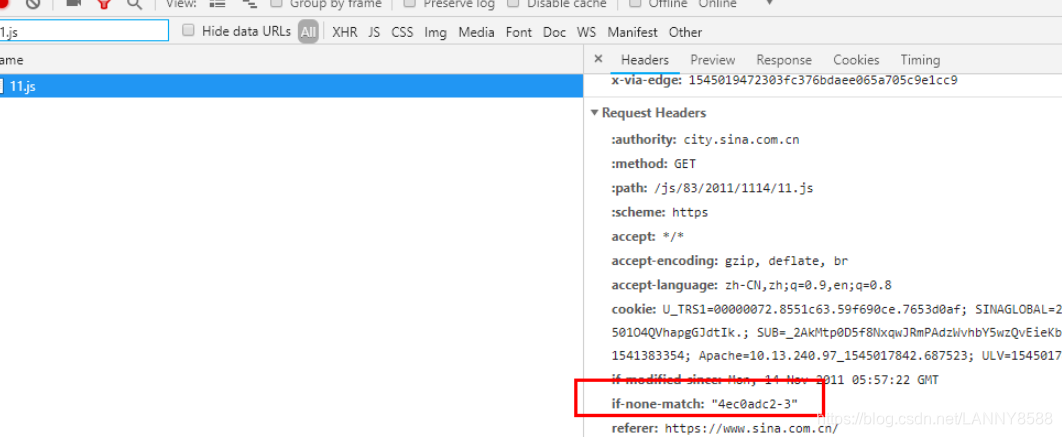
再次请求的时候,通过比对两者的区别,如果没有区别则返回304,有则返回200.
通常情况下,如果同时发送 If-None-Match 、If-Modified-Since字段,服务器只要比较etag 的内容即可,当然具体处理方式,看服务器的约定规则。
拓展:
Cache-Control
Http1.1 中的标准,可以看成是 expires 的补充。使用的是相对时间的概念。
简单介绍下Cache-Control的属性设置。
1)max-age: 设置缓存的最大的有效时间,单位为秒(s)。max-age会覆盖掉Expires
2) s-maxage: 只用于共享缓存,比如CDN缓存(s -> share)。与max-age 的区别是:max-age用于普通缓存,
而s-maxage用于代理缓存。如果存在s-maxage,则会覆盖max-age 和 Expires.
3) public:响应会被缓存,并且在多用户间共享。默认是public。
4) private: 响应只作为私有的缓存,不能在用户间共享。如果要求HTTP认证,响应会自动设置为private。
5)no-cache: 指定不缓存响应,表明资源不进行缓存。但是设置了no-cache之后并不代表浏览器不缓存,而是在缓存前要向服务器确认资源是否被更改。因此有的时候只设置no-cache防止缓存还是不够保险,还可以加上private指令,将过期时间设为过去的时间。
6)no-store: 绝对禁止缓存。
7)must-revalidate: 如果页面过期,则去服务器进行获取。
以上注意的就是nocache与nostore的区别
根据以上结论,浏览器缓存还可分为强缓存跟协商缓存:
强缓存就是时间期的判断,不过期就是强制缓存
协商缓存就是if-modified-since/last-modified 和 if-none-match/etag 之类的请求判断。
用户不同行为的操作方式会有不同的效果:
1.地址栏访问/新打开窗口/前进后退/,正常的浏览器缓存机制;
2.F5刷新,浏览器会设置max-age=0,跳过强缓存判断,进行协商缓存判断;
3.ctrl+F5刷新,跳过强缓存和协商缓存,直接从服务器拉取资源。
一般大型公司怎么解决强缓存问题呢:
URL中增加数字版本号,如下图,每一次变更一下,当这个参数变化的时候,强缓存都会失效并重新加载。

</div>
<link href="https://csdnimg.cn/release/phoenix/mdeditor/markdown_views-e9f16cbbc2.css" rel="stylesheet">
</div>

