
‘mysql’不是内部或外部命令,也不是可运行的程序或批处理文件。
解决:
- 配置坏境变量,指定mysql\bin目录
- 第次进入到mysql\bin目录,再运行mysql
如何链接服务器
服务器地址(可用IP域名):端口(3306) 用户名 密码
Mysql -h localhost -u UserName -p password
如: mysql -h localhost -u root -p
mysql -h localhost -u root -p 123456
mysql -hlocalhost -uroot -p123456
-h如果不写,则默认连localhost
如:mysql -u root -p
显示数据库 :show databases
information_schema 数据库的一些基本信息;mysql 关于用户的一些信息;performace_schema 性能优化的一些基本信息。
新建数据库:create database myDatabase chartset utf8;

选中某个数据库:use myDatabase
- 删除一个数据库:drop database test; mysql的数据库名字不能修改
- 显示表:show tables;
- 新建一个表:create table class (ID int,name varchar(20),age tinyint(M),area varchar(20));
- 删除一个表:drop database table1;
- 修改一个表的名字:rename table oldName to newName;
- 显示表的所有字段:desc tableName;
\c退出当前语句
解决字符集问题:默认建表一般用utf-8,而我们在windows下窗口是GBK的,因些需要声音字符集:set names gbk;
给表插入一条数据:如 insert into msg (id,title,content) values (1,'标题","内容“);
整型
- tinyint:默认是带符号位的(-128 到127);
- tinyint unsigned: 不带符号位(0到255);
- tinyint(M): 在0填充的时候才有意义, 只有在zerofill设置时才有意义,不影响数据泛微;
- tinyint zerofill:0填充,默认无符号;
- defalut:默认值;
- not null:不能为空;
如:alert table msg add ages tinyint(5) zerofill not null default 0;
creat table msg (id tinyint(4) zerofill not null default 0,title varchar(20),content varchar(20)) charset utf8;
浮点数
- float(M,D):M代到总位数,D 代表小数位;
- decimal(M,D):M代到总位数,D 代表小数位;decimal的精确度更高
如:float(4,2) 表示(99.99到 -99.99),float(4,2)unsigned 表示(0 到99.99);
字符型 char、vachar、text
- char(M):指定长M,
- varchar(M):是变长M,最长为M;速度上char更快些;
- text:文本类型,可以存比较大的文本段,搜索速度稍慢。text不用加时默认值,加了也没用。
日期时间类型
- year 年;(1901-2155年),如果输入2位,‘00-69’表示2000-2069,‘70-99’表示1970-1999
- data类型:日期类型1000-01-01 到9999-12-31
- time类型:典型格式 hh:mm:ss,日期类型范围:“-838:59:59”到“+838:59:59”
- datatime类型:yyyy-MM-DD hh:mm:ss,范围:1000-01-01 00:00:00到9999-12-31 23:59:59
- 时间戳:是1970-01-01:00:00:00到当前的秒数。一般存注册时间,商品发布时间等,羡慕不是用datetime存储,而是用时间戳。
注意:
在开发中,很少用日期时间类型来表示一个需要的精确到秒的列
原因:日期时间类型能精确到秒,而且 方便查看,但是不方便计算。用int存时间戳更方便计算
枚举类型enum(’男‘,’女‘);
id primary key auto_increment :主键、自动增长;
左链接
select * from tba left join tbb on tba.catId=tbb.catId;左链接以左边表为主表,当不能在tbb表里面匹配到相关信息时,显示NULL.
UNION
将两个表连接起来,要求连接的两个表列数一样,每列的类型一致。
select * from ta union select * from tb
视图
视图是表的查询结果,自然表的数据改变了,影响视图结果;
视图改变了,影响表,但是视图并不总是能增删改,只有当视图的数据与表的数据一一对应时才可以更改
注:插入视图时,视图必须包含表中没有默认值的列
- 创建:create algorithm= temptable view 视图名 as select 语句;
- 使用: select * from 视图名;
- 删除:drop view 视图名
视图的 algorithm=merge/temptable/undefined
- merge:当引用视图时,引用视图的语句与定义视图的语句合并。merge意味着视图只是一个规则,语句规则,当查询视图时,把查询视图的语句与创建时的语句where子句等合并,分析形成一条select语句。
- templtable:当引用视图时,根据视图的创建语句建立一个临时表
- undefined:未定义,自动、让系统帮你选。
字符集和校对集
某一个级别没有指定字符集则集成上一级的字符集。
- 服务器,我给你发送的数据是什么编码的:set character_set_client=gbk;
- 转换器,转换成什么编码:set character_set_connection=gbk;
- 查询的结果是用什么编码:set character_set_results=gbk;
注:如果以上3者都为字符集N,则可以简写为set names N
出现乱码的情况:client声明与事实不符,results与客户端字符集不符的时候
校对集 collation
create table tem(name varchar(10) ) charset utf8 collate utf8_bin; 指字符集的排序规则,一种字符集可以有一个或者多个排序规则。
注:声明的校对集必须是字符集合法的校对集
触发器
四要素:监视地点、监视事件、触发时间、触发事件。
创建:create trigger triggerName after|before insert|update|delete on 表名
for each row #行触发器,mysql里面是固定的
begin sql语句 end;
注: delimiter $ 将结束符由‘;’改成‘$’符,修改语句不用加结束符
删除: drop trigger triggerName;
查看: show triggers ;
- 对于insert而言,新增的行用 new来表示,行中每一列的值用new.列名来表示。
- 对于delete而言,删除的行用old来表示,行中的每一列的值用old.列名来表示。
- 对于update而言,修改的行,修改前的用old来表示,修改后的值用new来表示。
delimiter $ //更改结束符为$,不用加结束符
create trigger tg1 after insert on goods for each row
begin
update tb2 set num=num-1 where tb2.id=new.id;
end $
before例子:
create trigger tg2 befor insert on goods for each row
begin
if new.num >5 then
set new.much=5
end if ;
update g set num =num-new.muchh where id=new.gid;
end$
事务
事务指:一组操作,要么都成功执行,要么都不执行。
事物的ACID特性:
- 原子性(atomicity):原子意为最小的粒子,或者说不能再分的事物。数据库事务的不可再分的原则即为原子性;组成事务的所有查询必须:要么全部执行,要么全部取消(就像上面的银行例子)。
- 一致性(consistency):指数据的规则,在事务前/后应保持一致。
- 隔离性(Isolation):简单点说,某个事务的操作对其他事务不可见的。
- 持久性(Durability):当事务完成后,其影响应该保留下来,不能撤消。
存储引擎的种类和特点
显示所有的存储引擎:show engines;
指定存储引擎:create table tb (id int primary key auto_increment ) engine=innodb|myisam charset utf8;


支持事务案例的数据库引擎才有事务
开启事务:start transaction ; 注意:两个start transaction,前面的那个就隐式的提交了
sql语句......
commit提交、 rollback回滚 //当一个事务commit\rollback就结束 了

备份与恢复
增量备份、整体备份
系统自带的备份工具:mysqldump.exe,可以导出库也可以导出表
- 导出一个库下面的所有表:mysqldump -u 用户名 -p 密码 库名> 地址/备份的文件名称
- 备份多个库的方法:mysqldump -u 用户名 -p 密码 库名1 库名2 库名3 > 地址/备份的文件名称
如:mysqldump -uroot -p111111 mydatabase goods > D:\\goods.sql // 导出mydatabase数据库下的goods表,会在D盘下生成一个SQL文件
- 执行恢复:source D:\\mydatabase.sql;
- 对于表级的备份:use 库名 --------source 备份的文件地址
索引
- 好处:加快了查询速度;
- 坏处:降低了增、删、改的速度,增大了表的文件大小(索引文件甚至可能比数据文件还大)。
注意:大数据处理办法:先去掉索引,再导入,最后再统一加索引。
- 不能过度索引;
- 索引条件列(where 后面最频繁的条件比较适宜索引)
- 索引散列值,过于集中的值不要索引;如性别加索引,意义不大;
索引的类型:
- 普通索引(index):仅仅是加快查询速度;
- 主键索引(primary key):不能重复;主键必唯一,唯一索引不一定是主键,一张表只能有一个主键,可以有一个或多个唯一索引;
- 唯一索引(unique):行上的值不能重复;
- 全文索引(fulltext)
查看索引:
show index from 表名;
show index from 表名 \G //用另一种格式显示
建立索引:
alter table 表名 add index|unique|fulltext【索引名】(列名);
alter table 表名 add primary key (列名); //添加主键索引
删除索引:
alter table 表名 drop index 索引名;
alter table 表名 drop primary key; //删除主键
查询索引:
select * from member where match (pro) against ("china");
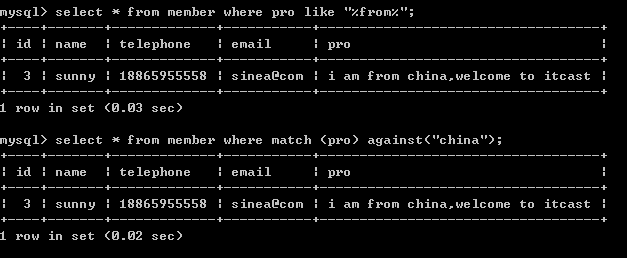
查询匹配度 select id,email, match (pro ) against ("china") from member;
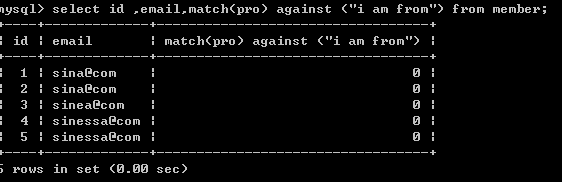
注:全文索引不针对非常频繁的词做索引,全文索引对中文意义不大
存储过程
概念类似于函数,就是把一段代码封装起来,在封装语句里面,可以用if/else,case,while等控制结构,可以进行sql编程。
- 查看:show procedure status 或 show procedure status \G;
- 删除:drop procedure 存储过程名字 ;
- 使用:call 存储过程名字;
delimiter $ create procedure p(n int) begin
declare i int;
declare s int;
set i=1;
set s=0;
while i<=n do
set s=s+i;
set i=i+i;
end while;
select s;
end$
call p(5)$ //调用


