

数据库实践
今天我们来学习以下有关于数据提取以及数据库的一些知识,
我们知道其实数据库是一个非常神奇的存在,它是是按照 数据结构来组织、 存储和管理数据的仓库
我们可以使用它对数据进行储存和管理!
下面是有关于sqlite3的学习,SQLite3 可使用 sqlite3 模块与 Python 进行集成。
这是一个环境自带的函数库,所以在编写代码时直接import就行啦~
我们有一些可以学习的语句:
| 语句 | 内容 |
| sqlite3.connect(database [,timeout ,other optional arguments]) | 该 API 打开一个到 SQLite 数据库文件 database 的链接。timeout 参数表示连接等待锁定的持续时间,直到发生异常断开连接。timeout 参数默认是 5.0(5 秒)。如果给定的数据库名称 filename 不存在,则该调用将创建一个数据库。如果您不想在当前目录中创建数据库,那么您可以指定带有路径的文件名,这样您就能在任意地方创建数据库。 |
| connection.cursor([cursorClass]) | 该例程创建一个 cursor,将在 Python 数据库编程中用到。 |
| cursor.execute(sql [, optional parameters]) | 该例程执行一个 SQL 语句。该 SQL 语句可以被参数化(即使用占位符代替 SQL 文本)。sqlite3 模块支持两种类型的占位符:问号和命名占位符(命名样式)。 |
| connection.execute(sql [, optional parameters]) | 该例程是上面执行的由光标(cursor)对象提供的方法的快捷方式,它通过调用光标(cursor)方法创建了一个中间的光标对象,然后通过给定的参数调用光标的 execute 方法。 |
| cursor.executemany(sql, seq_of_parameters) | 该例程对 seq_of_parameters 中的所有参数或映射执行一个 SQL 命令。 |
| connection.executemany(sql[, parameters]) | 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executemany 方法。 |
| cursor.executescript(sql_script) | 该例程一旦接收到脚本,会执行多个 SQL 语句。它首先执行 COMMIT 语句,然后执行作为参数传入的 SQL 脚本。所有的 SQL 语句应该用分号(;)分隔。 |
| connection.executescript(sql_script) | 该例程是一个由调用光标(cursor)方法创建的中间的光标对象的快捷方式,然后通过给定的参数调用光标的 executescript 方法。 |
| connection.total_changes() | 该例程返回自数据库连接打开以来被修改、插入或删除的数据库 |
生成一个数据库:
import sqlite3 conn = sqlite3.connect('shujuku.db') print ("成功打开数据库")
运行结果为:

这时如果原本没有数据库就会创建一个:
先利用爬虫爬取中国大学的排名并保存为csv文件:
import requests from bs4 import BeautifulSoup import pandas # 1. 获取网页内容 def gettext(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = 'utf-8' return r.text except Exception as e: print("Error:", e) return "" # 2. 分析网页内容并提取有用数据 def getTabelList(soup): # 获取表格的数据 tabel_list = [] # 存储整个表格数据 Tr = soup.find_all('tr') for tr in Tr: Td = tr.find_all('td') if len(Td) == 0: continue tr_list = [] # 存储一行的数据 for td in Td: tr_list.append(td.string) tabel_list.append(tr_list) return tabel_list # 3. 可视化展示数据 def Print(tabel_list, num): # 输出前num行数据 print("{1:^2}{2:{0}^10}{3:{0}^5}{4:{0}^5}{5:{0}^8}".format(chr(12288), "排名", "学校名称", "省市", "总分", "生涯质量")) for i in range(num): text = tabel_list[i] print("{1:{0}^2}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288), *text)) # 4. 将数据存储为csv文件 def save(filename, tabel_list): FormData = pandas.DataFrame(tabel_list) FormData.columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"] FormData.to_csv(filename, encoding='utf_8_sig', index=False) if __name__ == "__main__": url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html = gettext(url) soup = BeautifulSoup(html, features="html.parser") data = getTabelList(soup) #print(data) Print(data, 5) # 输出前5行数据 save("paiming.csv", data)
结果为:
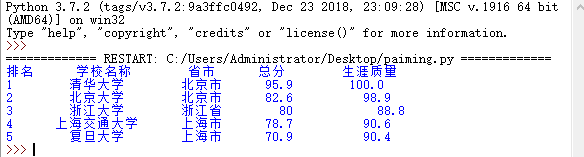
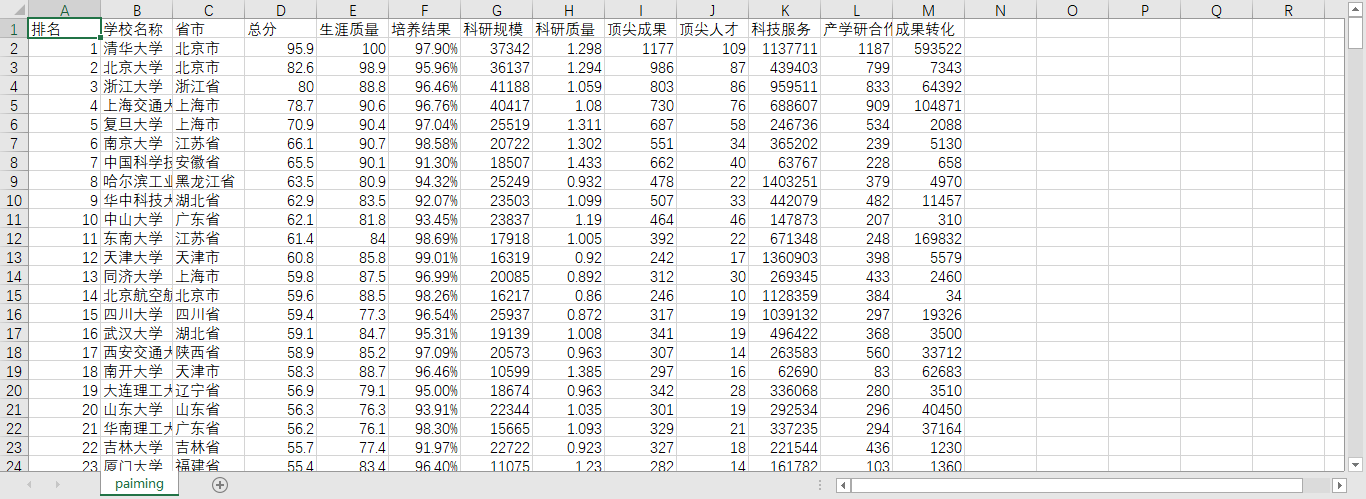
成功创建Connection对象以后,再创建一个Cursor对象,并且调用Cursor对象的execute()方法来执行SQL语句创建数据表以及查询、插入、修改或删除数据库中的数据:
c = conn.cursor() # 创建表, c.execute('''CREATE TABLE stocks (date text, trans text, symbol text, qty real, price real)''') # 插入一条记录 c.execute("INSERT INTO stocks VALUES ('2006-01-05','BUY', 'RHAT', 100, 35.14)") # 提交当前事务,保存数据 conn.commit() # 关闭数据库连接 conn.close()
如果需要查询表中内容,那么重新创建Connection对象和Cursor对象之后,可以使用下面的代码来查询。
for row in c.execute('SELECT * FROM stocks ORDER BY price'): print(row)
connect(database[, timeout, isolation_level, detect_types, factory]) :连接数据库文件,也可以连接":memory:"在内存中创建数据库。
sqlite3.Connection.execute():执行SQL语句
sqlite3.Connection.cursor():返回游标对象
sqlite3.Connection.commit():提交事务
sqlite3.Connection.rollback():回滚事务
sqlite3.Connection.close():关闭连接
将csv文件导入数据库:
import sqlite3 import openpyxl lists=sqlite3.connect('shujuku.db') c=lists.cursor() c.execute('''CREATE TABLE rankg("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化" )''') listinsheet=openpyxl.load_workbook(r'paiming.csv') datainlist=listinsheet.active #获取excel文件当前表格 data_truck=('''INSERT INTO rankg("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化") VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?)''') for row in datainlist.iter_rows(min_row=2,max_col=14,max_row=datainlist.max_row): #使excel各行数据成为迭代器 cargo=[cell.value for cell in row] c.execute(data_truck,cargo) for row in c.execute('SELECT * FROM rankg ORDER BY "序号"'): print(row) lists.commit() lists.close()
运行结果:
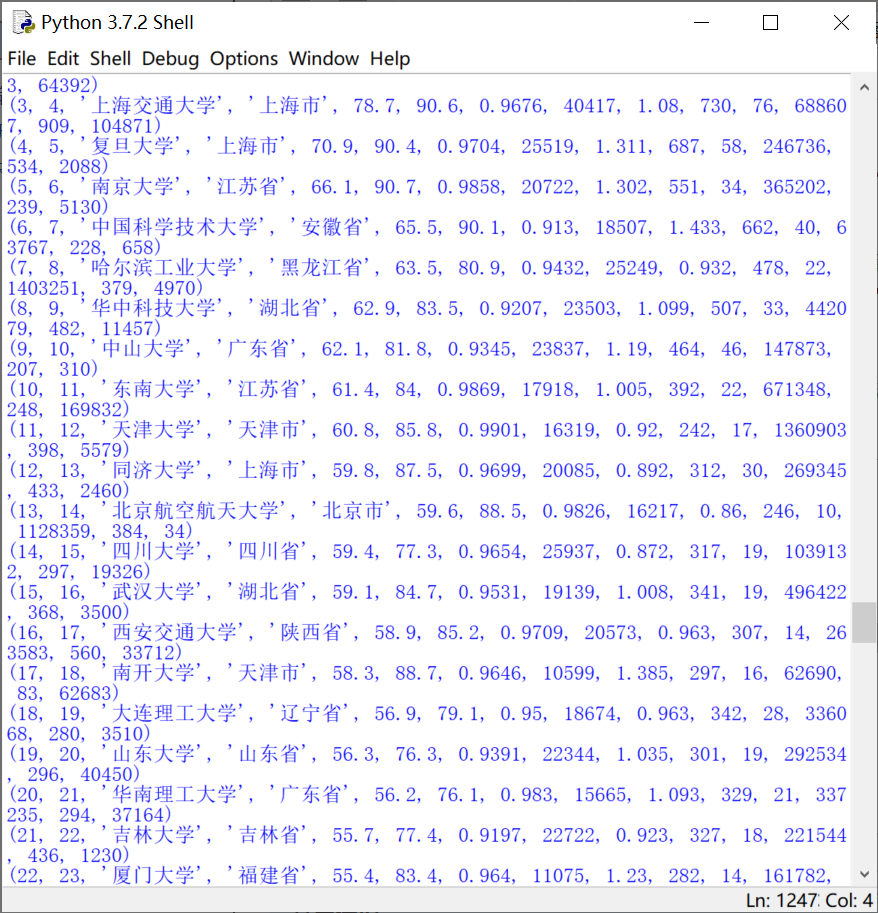
查询我们学校的排名:
import sqlite3 import openpyxl lists=sqlite3.connect('best college.db') c=lists.cursor() c.execute('''CREATE TABLE rankh("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化" )''') listinsheet=openpyxl.load_workbook(r'university.xlsx') datainlist=listinsheet.active #获取excel文件当前表格 data_truck=('''INSERT INTO rankh("序号","排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化") VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?)''') for row in datainlist.iter_rows(min_row=2,max_col=14,max_row=datainlist.max_row): #使excel各行数据成为迭代器 cargo=[cell.value for cell in row] #敲黑板!!使每行中单元格成为迭代器 c.execute(data_truck,cargo) #敲黑板!写入一行数据到数据库中表rankh c.execute('SELECT * FROM rankh WHERE "学校名称"="广州大学"')#由于我们学校没有上榜就查询了广州大学的排名 r = c.fetchall() print(r) lists.commit() lists.close()
结果为:

