
Sql Server 与Oracle 的分页
平时的项目开发中,分页存储过程是用的比较多的存储过程,SqlServer分页存储过程中经常要用到top,Oracle中则经常用到了RowNum.
现在,有一个UserInfo表,一个字段是UserId,另一个字段是UserName,其中是UserId是自动增长的,步长是1.表中共有30条数据,其中UserId的值不一定是连续的。现在要实现的目的是取其中的第11至第20条记录。先看SqlServer的几种做法:
第一种写法:
from UserInfo
where UserId in
(
select top 20 UserId
from UserInfo
)
order by UserId desc

第二种写法:
(select top 10 UserId from UserInfo )

第三种写法:
(select max(UserId) from
(select top10 UserId from UserInfo order by UserId) a)
第四种写法(只可在Sqlserver 2005中):
(Order by UserId) as RowId ,* from UserInfo) U
where U.RowId between 10 and 20

Sqlserver 中其实还有另外几种写法,不一一写出。四种方法中,后两种的写法要比前两种写法效率要高些,但第四种只能写在SqlServer 2005中。
在看Oracle中实现取其中的第11至第20条记录的做法之前,先看看一些人在使用RowNum遇到的莫名其妙的怪事。
表同样是UserInfo,30条数据
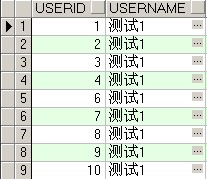
查询结果:
理论上应该是有20条数据才对啊,问题出现在哪呢?
因为ROWNUM是对结果集加的一个伪列,即先查到结果集之后再加上去的一个列 (这里要强调的一点是:先要有结果集)。简单的说 rownum 是对符合条件结果的序列号。所以对于rownum>10没有数据是否可以这样理解:
ROWNUM 是一个序列,是oracle数据库从数据文件或缓冲区中读取数据的顺序。它取得第一条记录则rownum值为1,第二条为2,依次类推。如果你用>,>=,=,between...and这些条件,因为从缓冲区或数据文件中得到的第一条记录的rownum为1,则被删除,接着取下条,可是它的rownum还是1,又被删除,依次类推,最后的查询结果为空。
再看下面一条sql语句:
查询结果:
查出的来结果不是21条,而是9条。可以这样理解:rownum 为9后的记录的 rownum为10,因条件为 !=10,所以去掉,其后记录补上,rownum又是10,也去掉,一直这样下去,最后的结果只有9条了。
如果把后面的条件改为 where rownum>1 时,会发现查不到一条数据,如果是where rownum>0 或是where rownum>=1时则可以查询到所有的数据。原因很简单:因为 rownum 是在查询到的结果集后加上去的,它总是从1开始。
between 1 and 20 或者 between 0 and 20 能查到结果,而用 between 2 and 20 却得不到结果,原因同上一样,因为 rownum 总是从 1 开始。
所以要实现取UserInfo表其中的第11至第20条记录,可以这样写:
(select rownum as rn,t.* from userinfo t where rownum >0)
where rn between 10 and 20
查询结果:
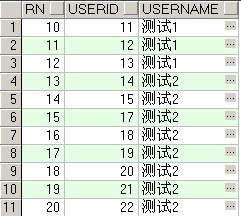
当然也可以这样写:
minus
select * from UserInfo where rownum<10
这种写法没有前面那种效率高。
但不能这样写:
select t.* from UserInfo t where rownum > 10 and rownum <=20
上面两种写法都取不到数据的。
对于Sqlserver 和Oracle 实现取表其中的第11至第20条记录如果有更好的写法,可以贴出来学习下。

