【推荐系统】Learning to Rank(还在编辑)
Learning to Rank
在一些推荐场景中,不仅要考虑预估问题,还要考虑排序问题。比如在Query场景中,使得期望用户选中的item在排序结果中更靠前。比如我用百度搜索一个东西,我能在第一页就能找到我想要的结果,那么在这种情况就会远远好过我还要再翻一页才能找到我想要的结果。
Ranking模型:
基于重要性的Ranking,仅根据网页之间的图结构来判断文档的重要程度,比如PageRank、TrustRank等。
基于相关度的Ranking,由于传统的PageRank考虑的因素比较少,一般只考虑内容与文档的相关性、逆文档频率、文档长度等几个因子,但是实际排序过程中需要考虑更多的特征,比如网页的pageRank值、查询和文档匹配的单词个数、网页URL链接地址长度等都对网页排名产生影响。搜索引擎又能提供机器学习需要的大量数据,因此将Ranking转换成一种有监督的机器学习。
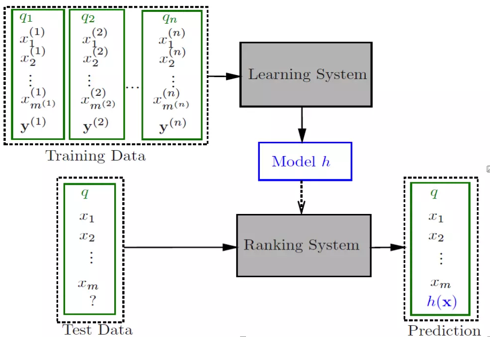
LTR的三种策略:
Pointwise
一种思想是将query与doc之间的相关程度作为标签,比如标签有三档,问题就变为多类分类问题,模型有McRank,svm,最大熵等。另一种思想是将query与doc之间的相关程度作为分数利用回归模型拟合,经典回归模型有线性回归,dnn,mart等。
Pairwise
Pairwise的方法是将文档组成文档对,不单考虑单个文档,而是考虑文档组对是否合理,比如对于query 1返回的三个文档 doc1,doc2,doc3, 有三种组对方式,<doc1,doc2>,<doc2,doc3>,<doc1,doc3>。当三个文档原来的label为3,4,2时,这样组对之后的三个例子就有了新的分数(表达这种顺序是否合理),可以利用这种数据进行分类学习,模型如SVM Rank, 还有RankNet(C. Burges, et al. ICML 2005), FRank(M.Tsai, T.Liu, et al. SIGIR 2007),RankBoost(Y. Freund, et al. JMLR 2003)。
Pairwise的一个问题是其对不同分数的doc区分度是一样的,然而在信息系统里面用户更倾向于点击最前面的结果,所以应该着重将相关性最高的排在前面。并且在现有的各类模型中并非以排序性能作为最终目标,将会导致最终排序效果并不理想。
Listwise
Pointwise将训练集里每一个文档当做一个训练实例,pairwise方法将同一个査询的搜索结果里任意两个文档对作为一个训练实例,Listwise方法是将每一个查询对应的所有搜索结果列表整体作为一个训练实例,
常见的模型比如ListNet使用正确排序与预测排序的排列概率分布之间的KL距离(交叉熵)作为损失函数,LambdaMART的框架其实就是MART,主要的创新在于中间计算的梯度使用的是Lambda,将类似于NDCG这种无法求导的IR评价指标转换成可以求导的函数,并且富有了梯度的实际物理意义。
策略说明:
Pointwise:
该方法优点是简单,不足在于没有考虑样本之间的位置信息(doc之间的相对顺序)
处理对象是一篇文档,将文档转换为特征向量后,机器学习系统用从文档中学习到的分类或回归函数对文档进行打分,打分排序结果就是搜索结果。下图是人工标注的训练集合:

其中,Label是相关性,feature是査询与文档的Cosme相似性分值、査询词的Proximity值及页面的PageRank数值。
对于机器学习系统来说,根据训练数据,需要如下的线性打分函数: Score(Q, D) = a * CS + b * PM + c * PR + d
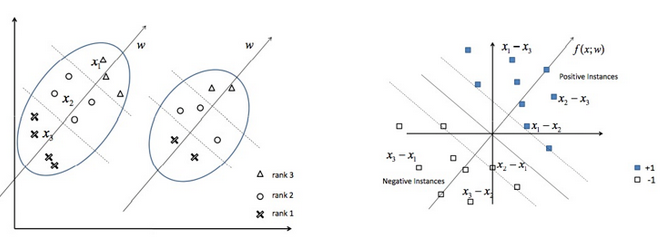
Listwise将排序问题转换为二分类问题。
如图,对于查询Q1,进行人工标注之后,Doc2=5的分数最高,其次是Doc3为4分,最差的是Doc1为3分,将此转为相对关系之后有:Doc2>Doc1、Doc2>Doc3、Doc3>Doc1,所以排序问题可以很自然的转为任意两个文档关系的判断,而任意两个文档顺序的判断就称为了一个很熟悉的分类问题。

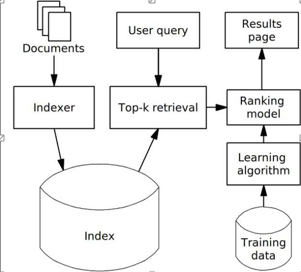
Listwise
文档列方法根据K个训练实例训练得到最优的评分函数F,对于一个新的查询,函数F对每一个文档进行打分,之后按照得分顺序高低排序,就是对应的搜索结果。
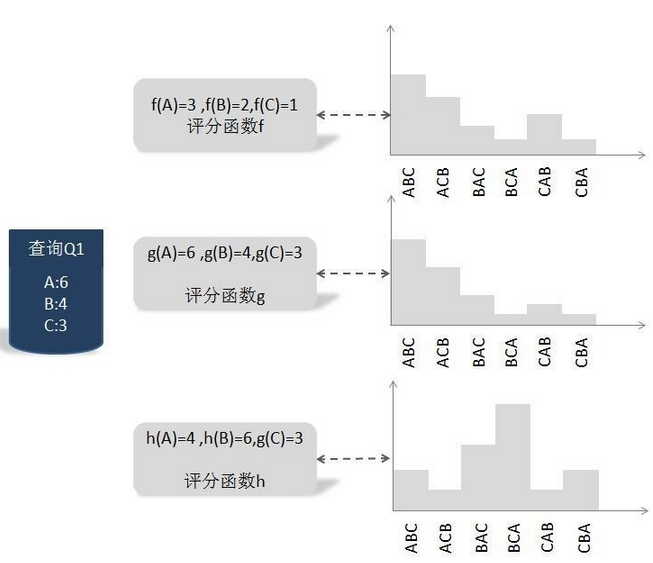
所以关键问题是:拿到训练数据,如何才能训练得到最优的打分函数?我们知道,对于搜索引擎来说,用户输入査询Q, 搜索引擎返回搜索结果,我们假设搜索结果集合包含A. B 和C 3个文档,搜索引擎要对搜索结果排序,而这3个文档的顺序共有6种排列组合方式:ABC, ACB, BAG, BCA, CAB和CBA而每种排列组合都是一种可能的搜索结果排序方法。对于某个评分函数F来说,对3个搜索结果文档的相关性打分,得到3个不同的相关度得分F(A)、 F(B)和F(C), 根据这3个得分就可以计算6种排列组合情况各自的概率值。 不同的评分函数,其6种搜索结果排列组合的概率分布是不一样的。这里介绍一种训练方法,它是基于搜索结果排列组合的概率分布情况来训练的,下图是这种方式训练过程的图解示意。
上图展示了一个具体的训练实例,即査询Q1及其对应的3个文档的得分情况,这个得分是由人工打上去的,所以可以看做是标准答案。可以设想存在一个最优的评分函数g,对查询Q1来说,其打分结果是:A文档得6分,B文档得4分,C文档得3分。
我们的任务就是找到一 个函数,使得函数对Q1的搜索结果打分顺序和人工打分顺序尽可能相同。
参考文章:
https://www.jianshu.com/p/ff9853a4892e
https://www.cnblogs.com/Lee-yl/p/11200535.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号