堆排序
科班出身的程序员就应该研究些算法和数据结构类的东西,不然,有什么优势?
堆排序,结构是完全二叉树,选择排序的一种,其流程控制和冒泡排序类似,每次选出一个最大(或最小的元素)排出去,然后下一轮再选出一个最大(最小的),以此类推,直到剩下一个不能构成二叉树为止也排出去,排出来的就是有序的了。只不过每次选极值元素不是对所有元素都对比,而是心中模拟有一棵完全二叉树,每次选出最大顶(最小顶)。
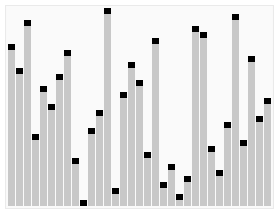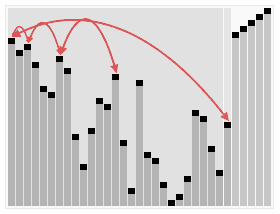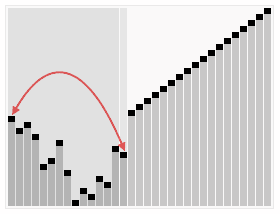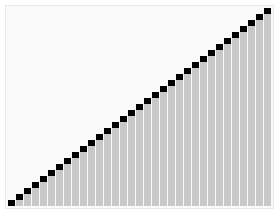
原理解析:
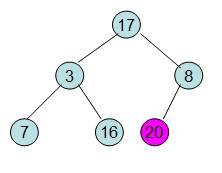
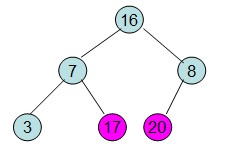
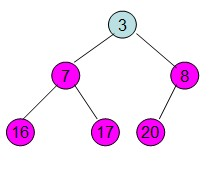
给定一个列表array=[16,7,3,20,17,8],对其进行堆排序。
首先根据该数组元素构建一个完全二叉树,得到
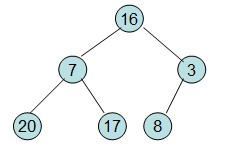
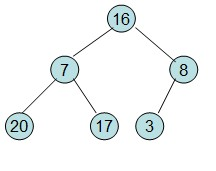

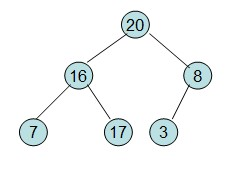
20和16交换后导致16不满足堆的性质,因此需重新调整

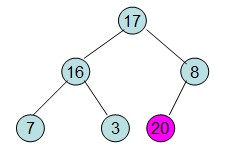
这样就得到了初始堆。
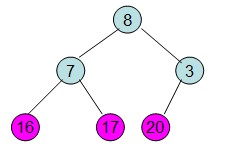
第二步: 堆顶元素R[1]与最后一个元素R[n]交换,交换后堆长度减一
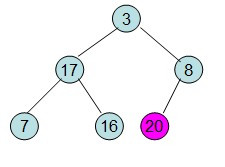
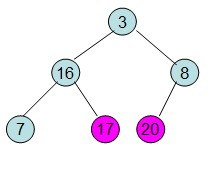
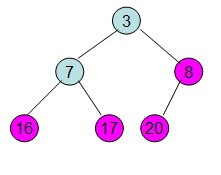
第三步: 重新调整堆。此时3位于堆顶不满堆的性质,则需调整继续调整(从顶点开始往下调整)
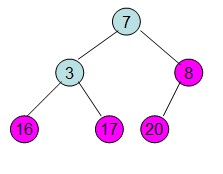
重复上面的步骤:
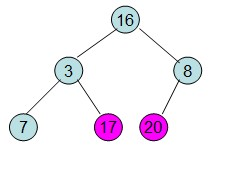

注意了,现在你应该了解堆排序的思想了,给你一串列表,你也能写出&说出堆排序的过程。
在写算法的过程中,刚开始我是很懵比。后来终于看懂了。请特别特别注意: 初始化大顶堆时 是从最后一个有子节点开始往上调整最大堆。而堆顶元素(最大数)与堆最后一个数交换后,需再次调整成大顶堆,此时是从上往下调整的。
不管是初始大顶堆的从下往上调整,还是堆顶堆尾元素交换,每次调整都是从父节点、左孩子节点、右孩子节点三者中选择最大者跟父节点进行交换,交换之后都可能造成被交换的孩子节点不满足堆的性质,因此每次交换之后要重新对被交换的孩子节点进行调整。我在算法中是用一个while循环来解决的
参考代码:
1 public class HeapSort {
2 public void HeapAdjust(int[] array, int parent, int length) {
3 int temp = array[parent]; // temp保存当前父节点
4 int child = 2 * parent + 1; // 先获得左孩子
5 while (child < length) {
6 // 如果有右孩子结点,并且右孩子结点的值大于左孩子结点,则选取右孩子结点
7 if (child + 1 < length && array[child] < array[child + 1]) {
8 child++;
9 }
10 // 如果父结点的值已经大于孩子结点的值,则直接结束
11 if (temp >= array[child])
12 break;
13 // 把孩子结点的值赋给父结点
14 array[parent] = array[child];
15 // 选取孩子结点的左孩子结点,继续向下筛选
16 parent = child;
17 child = 2 * child + 1;
18 }
19 array[parent] = temp;
20 }
21 public void heapSort(int[] list) {
22 // 循环建立初始堆
23 for (int i = list.length / 2; i >= 0; i--) {
24 HeapAdjust(list, i, list.length);
25 }
26 // 进行n-1次循环,完成排序
27 for (int i = list.length - 1; i > 0; i--) {
28 // 最后一个元素和第一元素进行交换
29 int temp = list[i];
30 list[i] = list[0];
31 list[0] = temp;
32 // 筛选 R[0] 结点,得到i-1个结点的堆
33 HeapAdjust(list, 0, i);
34 System.out.format("第 %d 趟: \t", list.length - i);
35 printPart(list, 0, list.length - 1);
36 }
37 }
38 // 打印序列
39 public void printPart(int[] list, int begin, int end) {
40 for (int i = 0; i < begin; i++) {
41 System.out.print("\t");
42 }
43 for (int i = begin; i <= end; i++) {
44 System.out.print(list[i] + "\t");
45 }
46 System.out.println();
47 }
48 public static void main(String[] args) {
49 // 初始化一个序列
50 int[] array = { 16, 7, 3, 20, 17, 8 };
51 // 调用堆排序方法
52 HeapSort heap = new HeapSort();
53 System.out.print("排序前:\t");
54 heap.printPart(array, 0, array.length - 1);
55 heap.heapSort(array);
56 System.out.print("排序后:\t");
57 heap.printPart(array, 0, array.length - 1);
58 }
59 }
时间复杂度:
堆的存储表示是顺序的。因为堆所对应的二叉树为完全二叉树,而完全二叉树通常采用顺序存储方式。
当想得到一个序列中第k个最小的元素之前的部分排序序列,最好采用堆排序。
因为堆排序的时间复杂度是O(n+klog2n),若k≤n/log2n,则可得到的时间复杂度为O(n)。
算法稳定性:
堆排序是一种不稳定的排序方法。
因为在堆的调整过程中,关键字进行比较和交换所走的是该结点到叶子结点的一条路径,
因此对于相同的关键字就可能出现排在后面的关键字被交换到前面来的情况。
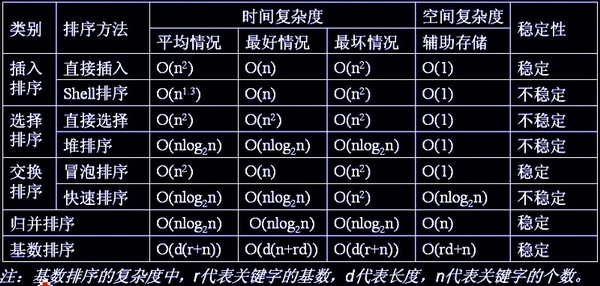
最后看一下排序家族

 浙公网安备 33010602011771号
浙公网安备 33010602011771号