图的深度优先搜索和广度优先搜索
一、图
在计算机科学中,一个图就是一些顶点的集合,这些顶点通过一系列边结对(连接)。顶点用圆圈表示,边就是这些圆圈之间的连线。顶点之间通过边连接。
基本概念
阶(Order):图G中点集V的大小称作图G的阶。
度(Degree):一个顶点的度是指与该顶点相关联的边的条数,顶点v的度记作d(v)。
入度(In-degree)和出度(Out-degree):对于有向图来说,一个顶点的度可细分为入度和出度。一个顶点的入度是指与其关联的各边之中,以其为终点的边数;出度则是相对的概念,指以该顶点为起点的边数。
子图(Sub-Graph):当图G'=(V',E')其中V‘包含于V,E’包含于E,则G'称作图G=(V,E)的子图。每个图都是本身的子图。
路径(Path):从u到v的一条路径是指一个序列v0,e1,v1,e2,v2,...ek,vk,其中ei的顶点为vi及vi - 1,k称作路径的长度。如果它的起止顶点相同,该路径是“闭”的,反之,则称为“开”的。一条路径称为一简单路径(simple path),如果路径中除起始与终止顶点可以重合外,所有顶点两两不等。
二元组的定义
图G是一个有序二元组(V,E),其中V称为顶集(Vertices Set),E称为边集(Edges set),E与V不相交。它们亦可写成V(G)和E(G)。
E的元素都是二元组,用(x,y)表示,其中x,y∈V。
三元组的定义
图G是指一个三元组(V,E,I),其中V称为顶集,E称为边集,E与V不相交;I称为关联函数,I将E中的每一个元素映射到(v,v)。
如果e被映射到(u,v),那么称边e连接顶点u,v,而u,v则称作e的端点,u,v此时关于e相邻。同时,若两条边i,j有一个公共顶点u,则称i,j关于u相邻。
图的存储-邻接矩阵

图的存储-邻接表
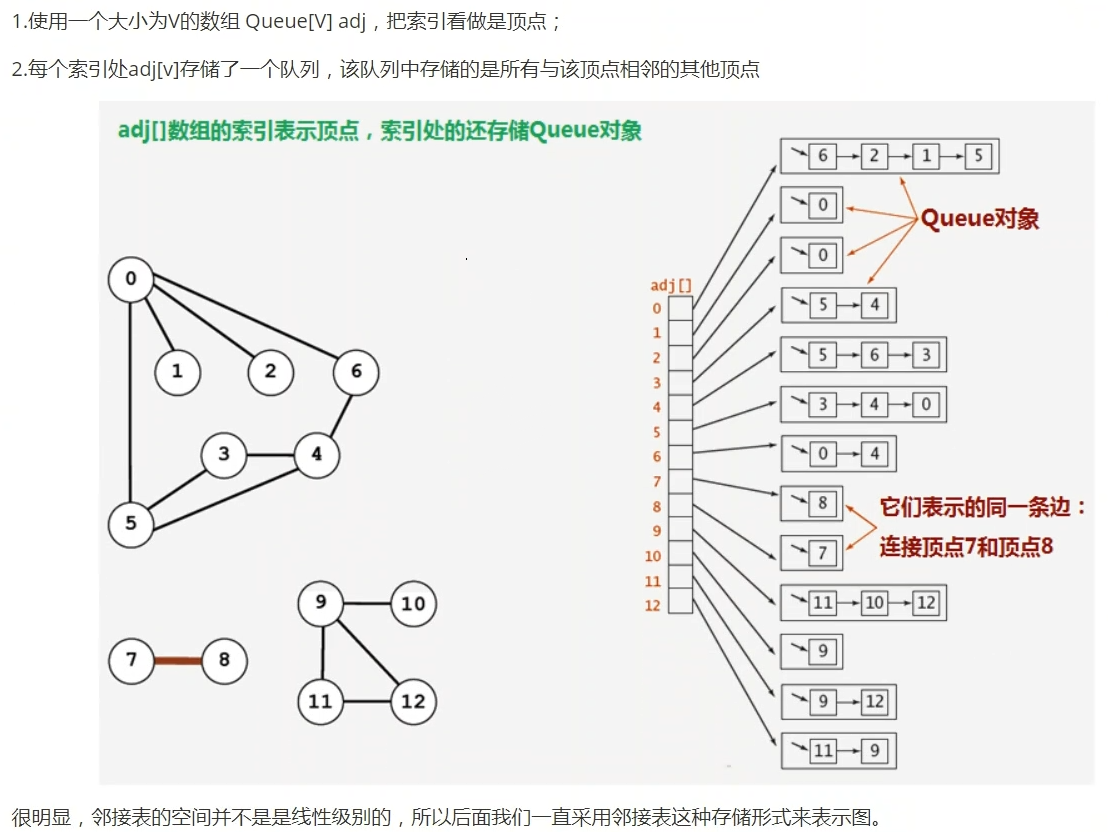
1 public class Graph { 2 //顶点数目 3 private int v; 4 //边的数目 5 private int e; 6 //邻接表 7 private Queue<Integer>[] adj; 8 public Graph(int v) { 9 //初始化定点数量 10 this.v = v; 11 //初始化边的数量 12 this.e = 0; 13 //初始化邻接表 14 this.adj = new Queue[v]; 15 for(int i = 0; i < adj.length; i++) { 16 adj[i] = new LinkedList<>(); 17 } 18 } 19 //获取定点数目 20 public int getV() { 21 return v; 22 } 23 //获取边数目 24 public int getE() { 25 return e; 26 } 27 //向图中添加一条边v-w 28 public void addEdge(int v, int w) { 29 //在无向图中,边是没有方向的,所以该边既可以说是v到w的边,也可以说是从w到v的边,因此,让v出现在w表中并让w出现在v表中 30 adj[v].offer(w); 31 adj[w].offer(v); 32 e++; 33 } 34 //获取和定点v相邻的所有定点 35 public Queue<Integer> adj(int v) { 36 return adj[v]; 37 } 38 }
二、图的深度优先搜索
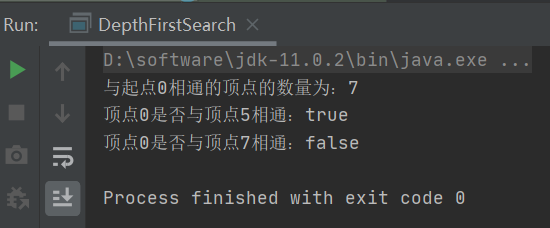
1 class DepthFirstSearch { 2 //索引代表顶点,表示当前顶点是否已经被搜索 3 private boolean[] marked; 4 //记录有多少个顶点和s顶点相通 5 private int count; 6 //构造深度优先搜索对象,使用深度优先搜索找出G图中s顶点的所有相通顶点 7 DepthFirstSearch(Graph graph, int s) { 8 //初始化mark数组 9 this.marked = new boolean[graph.getV()]; 10 //初始化定点s相通的顶点的数量 11 this.count = 0; 12 dfs(graph, s); 13 } 14 //使用深度优先搜索找出G图中v顶点的所有相通顶点 15 private void dfs(Graph graph, int v) { 16 //把v顶点标志为已搜索 17 marked[v] = true; 18 for(Integer w : graph.adj(v)) { 19 //判断当前顶点有没有被搜索,如果没有被搜索,则递归调用dfs方法进行深度搜索 20 if(!marked[w]) { 21 dfs(graph, w); 22 } 23 } 24 //相通顶点数+1 25 count++; 26 } 27 //判断w顶点是否与s顶点相通 28 public boolean marked(int w) { 29 return marked[w]; 30 } 31 //获取与顶点s相通的所有定点总数 32 public int count() { 33 return count; 34 } 35 //主类 36 public static void main(String args[]) { 37 //准备graph对象 38 Graph graph = new Graph(13); 39 graph.addEdge(0, 5); 40 graph.addEdge(0, 1); 41 graph.addEdge(0, 2); 42 graph.addEdge(0, 6); 43 graph.addEdge(5, 3); 44 graph.addEdge(5, 4); 45 graph.addEdge(3, 4); 46 graph.addEdge(4, 6); 47 graph.addEdge(7, 8); 48 graph.addEdge(9, 10); 49 graph.addEdge(9, 11); 50 graph.addEdge(9, 12); 51 graph.addEdge(11, 12); 52 //准备深度搜索对象 53 DepthFirstSearch depthFirstSearch = new DepthFirstSearch(graph, 0); 54 //测试与某个顶点相通顶点数量 55 System.out.println("与起点0相通的顶点的数量为:" + depthFirstSearch.count()); 56 //测试某个顶点与起点是否相同 57 System.out.println("顶点0是否与顶点5相通:" + depthFirstSearch.marked(5)); 58 System.out.println("顶点0是否与顶点7相通:" + depthFirstSearch.marked(7)); 59 } 60 }
三、图的广度优先搜索
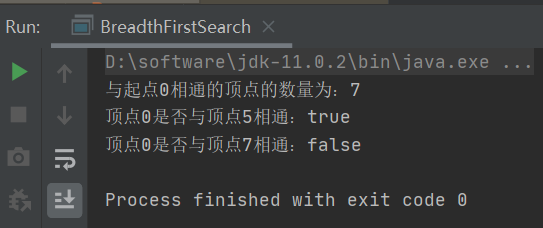
1 class BreadthFirstSearch { 2 //索引代表顶点,值表示当前顶点是否已经被搜索 3 private boolean[] marked; 4 //记录多少个顶点与s顶点相通 5 private int count; 6 //用来存储搜索邻接表的点 7 private Queue<Integer> waitSearch; 8 //构造广度优先搜索对象,使用广度优先搜索出G图中的s顶点的所有相邻顶点 9 BreadthFirstSearch(Graph graph, int s) { 10 this.marked = new boolean[graph.getV()]; 11 this.count = 0; 12 this.waitSearch = new LinkedList<>(); 13 bfs(graph, s); 14 } 15 //使用广度优先搜索出G图中v顶点的所有相邻顶点 16 private void bfs(Graph graph, int v) { 17 //把当前顶点v标志为已搜索 18 marked[v] = true; 19 //让顶点v进入队列,带搜索 20 waitSearch.offer(v); 21 //通过循环,如果队列不为空,则从队列中弹出一个带搜索的顶点进行搜索 22 while(!waitSearch.isEmpty()) { 23 //弹出一个待搜索顶点 24 Integer wait = waitSearch.poll(); 25 //遍历wait顶点的邻接表 26 for(Integer w : graph.adj(wait)) { 27 if(!marked[w]) { 28 bfs(graph, w); 29 } 30 } 31 } 32 //让相通的节点+1 33 count++; 34 } 35 //判断w顶点是否与s顶点相通 36 public boolean marked(int w) { 37 return marked[w]; 38 } 39 //获取与顶点s相通的所有顶点总数 40 public int count() { 41 return count; 42 } 43 //主类 44 public static void main(String args[]) { 45 //准备graph对象 46 Graph graph = new Graph(13); 47 graph.addEdge(0, 5); 48 graph.addEdge(0, 1); 49 graph.addEdge(0, 2); 50 graph.addEdge(0, 6); 51 graph.addEdge(5, 3); 52 graph.addEdge(5, 4); 53 graph.addEdge(3, 4); 54 graph.addEdge(4, 6); 55 graph.addEdge(7, 8); 56 graph.addEdge(9, 10); 57 graph.addEdge(9, 11); 58 graph.addEdge(9, 12); 59 graph.addEdge(11, 12); 60 //准备深度搜索对象 61 BreadthFirstSearch breadthFirstSearch = new BreadthFirstSearch(graph, 0); 62 //测试与某个顶点相通顶点数量 63 System.out.println("与起点0相通的顶点的数量为:" + breadthFirstSearch.count()); 64 //测试某个顶点与起点是否相同 65 System.out.println("顶点0是否与顶点5相通:" + breadthFirstSearch.marked(5)); 66 System.out.println("顶点0是否与顶点7相通:" + breadthFirstSearch.marked(7)); 67 } 68 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号