python操作MongoDB的库--MongoEngine
MongoEngine是一个ODM(Object-Document Mapper)库,底层使用Pymongo。
https://github.com/MongoEngine/mongoengine
要求:Pymongo 3.4+
安装
pip install mongoengine
连接
https://mongoengine-odm.readthedocs.io/guide/connecting.html#guide-connecting
两种方式
连接字符串
from mongoengine import connect
conn_str = "mongodb://root:111111@10.0.0.12:27017"
connect(db = "test1", host = conn_str)
选项
from mongoengine import connect
conf = {
"db" : "test1",
"host" : "10.0.0.12",
"port" : 27017,
"username": "root",
"password": "111111"
}
connect(**conf)
模型
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
name = StringField(min_length = 2, max_length = 10, required = True, unique = True, )
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
集合名称
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users" # 指定该模型对应的集合的实际名称
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True, )
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
# 重写打印方法方便查看
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)a
如果类名是 BlogUser ,默认名称为 blog_user ,可以手动指定。
meta = {'collection':'users'} 手动指定使用的集合。
模型的字段
https://mongoengine-odm.readthedocs.io/guide/defining-documents.html#fields
| 字段 | 说明 |
|---|---|
| BaseField | MongoDB文档中字段的基本类。该类的实例可以添加到Document的子类中,以定义文档的模式。 |
| StringField | 字符串字段 |
| URLField | 一个将输入验证为URL的字段。 |
| EmailField | 一个用于验证输入是否为电子邮件地址的字段。 |
| EnumField | 枚举字段。 值按照其原样存储,因此它只适用于可被 bson 编码的简单类型(如 str、int 等)。 |
| IntField | 32位整数字段。 |
| LongField | 64位整数字段。(自从Python2的支持被放弃后,等同于IntField) |
| FloatField | 浮点数字段。 |
| BooleanField | 布尔类型的字段 |
| DateTimeField | 日期时间字段。 如果可用,使用python-dateutil库来解析日期。注意:python-dateutil的解析器功能齐全,安装后,您可以使用它来将不同类型的日期格式转换为有效的Python datetime对象。 注意:要将字段默认设置为当前日期时间,请使用: DateTimeField(default=datetime.utcnow)注意:微秒被四舍五入到最近的毫秒。 在UTC之前的微秒支持实际上已经中断。如果您需要准确的微秒支持,请使用ComplexDateTimeField。 |
| ComplexDateTimeField | ComplexDateTimeField可以精确地处理微秒,而不是像DateTimeField那样进行四舍五入。 它从StringField派生,因此您可以在过滤和排序字符串时使用字典顺序进行比较,以进行gte和lte过滤。 存储的字符串具有以下格式: YYYY,MM,DD,HH,MM,SS,NNNNNN其中NNNNNN表示所表示的datetime的微秒数。逗号作为分隔符,在初始化字段时传递separator关键字,可以轻松地修改分隔符。 注意:要将字段默认设置为当前日期时间,请使用: DateTimeField(default=datetime.utcnow) |
| ListField | 一个列表字段,它封装了一个标准字段,允许在该字段中使用多个实例作为数据库中的列表。 |
| SortedListField | 一个ListField,在向数据库写入之前对列表内容进行排序,以确保始终检索到已排序的列表。 |
| DictField | 一个字典字段,它包含一个标准的Python字典。这类似于嵌入式文档,但其结构没有定义。 |
| MapField | 一个将名称映射到指定字段类型的字段。与DictField类似,但每个项的“值”必须匹配指定的字段类型。 |
| BinaryField | 二进制数据字段。 |
| ImageField | 一个图像文件存储字段。 |
| UUIDField | 一个UUID字段。 在数据库中存储UUID数据。 |
管理器
类似于Django的管理器,默认名字也叫作objects。操作的方法也很类似。
默认查询集
默认情况下,文档上的 objects 属性返回一个不筛选集合的QuerySet,即返回所有对象。
这可以通过在文档上定义一个修改查询集的方法来改变。
该方法应接受两个参数
doc_cls方法所在的Document类(在这个意义上,该方法更像是类方法()而不是普通方法)queryset初始查询集
为了被识别,该方法需要用 queryset_manager() 装饰器进行装饰。
class BlogPost(Document):
title = StringField()
date = DateTimeField()
@queryset_manager
def objects(doc_cls, queryset):
# 返回一个新的查询集
return queryset.order_by('-date')
也可以不重写 objects管理器 ,你可以定义尽可能多的自定义管理器方法。
class BlogPost(Document):
title = StringField()
published = BooleanField()
@queryset_manager
def live_posts(doc_cls, queryset):
return queryset.filter(published=True)
BlogPost(title='test1', published=False).save()
BlogPost(title='test2', published=True).save()
assert len(BlogPost.objects) == 2
assert len(BlogPost.live_posts()) == 1
自定义查询集
如果您想为与文档的交互或过滤添加自定义方法,扩展 QuerySet 类可能是一个好方法。
在文档的元字典中,将 queryset_class 设置为自定义类,以在文档上使用自定义的 QuerySet 类:
from mongoengine import QuerySet
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
# 自定义查询集
class CustomQuerySet(QuerySet):
# 查询管理员的方法
def get_admin(self):
return self.filter(is_admin = True)
# 查询年龄小于等于30的方法
def get_lte_30(self):
return self.filter(age__lte = 30)
class User(Document):
meta = {
"collection" : "users",
'queryset_class': AdminQuerySet # 设置查询集
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True)
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
# 调用自定义查询集的方法
print(*User.objects.get_admin(), sep = '\n')
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c91,name: tom0, age: 47, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c93,name: tom2, age: 53, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c94,name: tom3, age: 31, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c95,name: tom4, age: 34, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c96,name: tom5, age: 51, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c97,name: tom6, age: 49, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c9a,name: tom9, age: 31, is_admin: True, score: 0.0 >
"""
print(*User.objects.get_lte_30(), sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
"""
增
通过管理器添加
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users"
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True, )
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
# 管理器objects添加
u1 = User.objects.create(name = "jerry", age = 31)
print(u1)
"""
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 31, is_admin: False, score: 0 >
"""
通过User对象添加
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users"
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True, )
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
# 初始化对象,通过对象添加
u1 = User(name = "tom")
u1.age = 55
u1.is_admin = True
u1.save()
print(u1)
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0 >
"""

查询
查所有
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users"
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True, )
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
# 查询所有数据可以省略all()
# allUser = User.objects.all()
allUser = User.objects
for u in allUser:
print(type(u), u.pk, u.id, u.name, u.age)
"""
<class '__main__.User'> 658e6fc77124acd9148ba183 658e6fc77124acd9148ba183 jerry 31
<class '__main__.User'> 658e704e675617d32afa4fa4 658e704e675617d32afa4fa4 tom 55
<class '__main__.User'> 658e7150ebb88eedb7969c91 658e7150ebb88eedb7969c91 tom0 47
<class '__main__.User'> 658e7150ebb88eedb7969c92 658e7150ebb88eedb7969c92 tom1 22
<class '__main__.User'> 658e7150ebb88eedb7969c93 658e7150ebb88eedb7969c93 tom2 53
<class '__main__.User'> 658e7150ebb88eedb7969c94 658e7150ebb88eedb7969c94 tom3 31
<class '__main__.User'> 658e7150ebb88eedb7969c95 658e7150ebb88eedb7969c95 tom4 34
<class '__main__.User'> 658e7150ebb88eedb7969c96 658e7150ebb88eedb7969c96 tom5 51
<class '__main__.User'> 658e7150ebb88eedb7969c97 658e7150ebb88eedb7969c97 tom6 49
<class '__main__.User'> 658e7150ebb88eedb7969c98 658e7150ebb88eedb7969c98 tom7 28
<class '__main__.User'> 658e7150ebb88eedb7969c99 658e7150ebb88eedb7969c99 tom8 25
<class '__main__.User'> 658e7150ebb88eedb7969c9a 658e7150ebb88eedb7969c9a tom9 31
"""
查一个
u = User.objects.get(name = "tom")
print(u)
这么查会有个问题,就是当查不到的时候,会报错
Traceback (most recent call last):
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\mongoengine\queryset\base.py", line 269, in get
result = next(queryset)
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\mongoengine\queryset\base.py", line 1608, in __next__
raw_doc = next(self._cursor)
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\pymongo\cursor.py", line 1267, in next
raise StopIteration
StopIteration
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "E:\Codes\python\mengma\mm_api\测试mongoEngine的使用.py", line 50, in <module>
u = User.objects.get(name = "tom")
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\mongoengine\queryset\base.py", line 272, in get
raise queryset._document.DoesNotExist(msg)
__main__.DoesNotExist: User matching query does not exist.
可以换一种方式
u = User.objects(name = "tom")
if u:
u = u.get()
print(u)
用objects查到的就是一个查询集,是列表,是一个集合,如果查到的查询集是有数据的,再get,就不会报错了
文档pk
https://docs.mongoengine.org/guide/document-instances.html#document-ids
每一个文档(集合中的一条记录)都有唯一的id。
不设置主键
如果没有定义主键,那么会自动生成一个主键 _id ,可以使用.id或.pk访问
allUser = User.objects
for u in allUser:
print(u.pk, u.id)
"""
658e6fc77124acd9148ba183 658e6fc77124acd9148ba183
658e704e675617d32afa4fa4 658e704e675617d32afa4fa4
658e7150ebb88eedb7969c91 658e7150ebb88eedb7969c91
658e7150ebb88eedb7969c92 658e7150ebb88eedb7969c92
658e7150ebb88eedb7969c93 658e7150ebb88eedb7969c93
658e7150ebb88eedb7969c94 658e7150ebb88eedb7969c94
658e7150ebb88eedb7969c95 658e7150ebb88eedb7969c95
658e7150ebb88eedb7969c96 658e7150ebb88eedb7969c96
658e7150ebb88eedb7969c97 658e7150ebb88eedb7969c97
658e7150ebb88eedb7969c98 658e7150ebb88eedb7969c98
658e7150ebb88eedb7969c99 658e7150ebb88eedb7969c99
658e7150ebb88eedb7969c9a 658e7150ebb88eedb7969c9a
"""
不设置主键,会自动创建一个id属性,作为pk,和_id字段建立映射关系
定义主键
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users"
}
# 在这里加上primary_key = True 设置name为主键,那么无论pk还是id,还是name,都是name的值
name = StringField(primary_key = True, min_length =2, max_length = 10, required = True)
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
allUser = User.objects
for u in allUser:
print(u.pk, u.id, u.name, u.age)
"""
jerry jerry jerry 31
tom tom tom 55
tom0 tom0 tom0 47
tom1 tom1 tom1 22
tom2 tom2 tom2 53
tom3 tom3 tom3 31
tom4 tom4 tom4 34
tom5 tom5 tom5 51
tom6 tom6 tom6 49
tom7 tom7 tom7 28
tom8 tom8 tom8 25
tom9 tom9 tom9 31
"""
再添加新数据
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
class User(Document):
meta = {
"collection": "users"
}
name = StringField(primary_key = True, min_length = 2, max_length = 10, required = True)
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
u1 = User()
u1.name = "ben"
u1.age = 22
print(u1)
u1.save()
u2 = User(name = "jemmy")
u2.save()
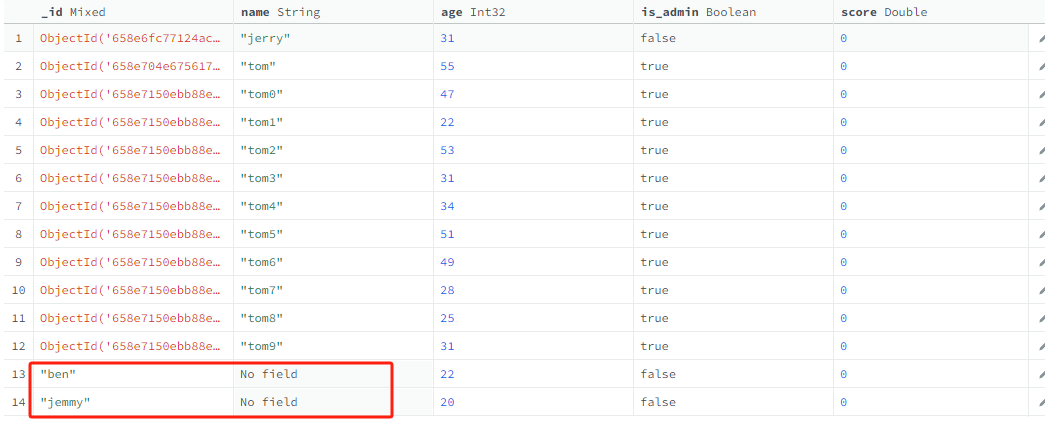
指定name为主键pk,自动创建一个id属性直接引用name字段,那么内部就会把_id和name之间的映射关系。也就是在这种情况下,_id、id、name就是同一个字段。
多字段联合主键
在MongoDB和MongoEngine中,由于文档型数据库的特性,实际上并没有明确的“联合主键”概念。每个文档都有一个唯一的 _id 字段作为主键,并且默认情况下它是自动生成的ObjectId。
然而,为了模拟关系型数据库中的联合主键效果,即多个字段组合起来唯一标识一个文档,您可以在创建模型类时通过 unique_with 装饰器来指定一组字段的组合必须是唯一的
如果只是两个字段联合主键
class User(Document):
# 可以设置单独的unique
username = StringField(unique=True)
# 也可以通过unique_with来设置联合主键,这里是first_name和last_name联合唯一性,所以这里是单独的字段字符串
first_name = StringField()
last_name = StringField(unique_with='first_name')
三个以上字段的联合主键
class User1(Document):
name = StringField(unique_with = ["age", "is_admin", "score"])
# unique_with可以是一个字段的字符串,也可以是多个字段的列表或元组
age = IntField()
is_admin = BooleanField()
score = FloatField()
注意,一旦为
unique_with中,就默认加上了required=True,除非字段加上了默认值,否则,会报mongoengine.errors.ValidationError: ValidationError
条件查询
查询操作符
https://mongoengine-odm.readthedocs.io/guide/querying.html#query-operators
print(*User.objects(age__gte = 50), sep = "\n") # 大于等于50岁的
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c93,name: tom2, age: 53, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c96,name: tom5, age: 51, is_admin: True, score: 0.0 >
"""
print(*User.objects(age__not__gte = 30), sep = "\n") # 不是大于等于30岁的
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
"""
print(*User.objects(name__not__istartswith='T'), sep='\n') # 不是以T开头的 前面加了i是不区分大小写的
"""
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 31, is_admin: False, score: 0.0 >
"""
查询操作符
ne– 不等于
lt– 小于lte– 小于或等于gt– 大于gte– 大于或等于not– 否定一个标准检查,可以在其他操作符之前使用(例如Q(age__not__mod=(5, 0)))in– 值应在列表中(应提供值的列表)nin– 值不在列表中(应提供值的列表)mod–value % x == y, 其中x和y是两个给定的值all– 提供的值列表中的每个项目都在数组中。size– 数组的大小是exists– 字段值已存在
字符串查询
exact– 字符串字段与值完全匹配iexact– 字符串字段完全匹配值(不区分大小写)contains– 字符串字段包含值icontains– 字符串字段包含值 (不区分大小写)startswith– 字符串字段以值开头istartswith– 字符串字段以值开头 (不区分大小写)endswith– 字符串字段以值结尾iendswith– 字符串字段以值结尾 (不区分大小写)wholeword– 字符串字段包含整个单词iwholeword– 字符串字段包含整个单词 (不区分大小写)regex– 通过正则表达式匹配字符串字段iregex– 通过正则表达式匹配字符串字段 (不区分大小写)match– 执行$elemMatch操作,以便在数组中匹配整个文档。
原始查询
https://mongoengine-odm.readthedocs.io/guide/querying.html#raw-queries
可以将原始的 PyMongo 查询作为查询参数提供,该查询将直接集成到查询中。
这是通过使用 __raw__ 关键字参数完成的:
Page.objects(__raw__={'tags': 'coding'})
同样,也可以将原始更新提供给 update() 方法:
Page.objects(tags='coding').update(__raw__={'$set': {'tags': 'coding'}})
而两者也可以结合在一起:
Page.objects(__raw__={'tags': 'coding'}).update(__raw__={'$set': {'tags': 'coding'}})
排序
https://mongoengine-odm.readthedocs.io/guide/querying.html#sorting-ordering-results
使用order_by()方法,可以根据一个或多个键来对结果进行排序。
每个键前面可以加上 + 或 - 来指定排序顺序。
如果没有前缀,则默认为升序。
# 按升序 date 排序
blogs = BlogPost.objects().order_by('date') # 等于 .order_by('+date')
# 首先按 date 升序排序,然后按 title 降序排序。
blogs = BlogPost.objects().order_by('+date', '-title')
# 也可以省略objects后的括号
blogs = BlogPost.objects.order_by('+date', '-title')
分页
https://mongoengine-odm.readthedocs.io/guide/querying.html#limiting-and-skipping-results
就像传统的 ORM 一样,您可以在查询中限制返回的结果数量或跳过一些结果。
QuerySet 对象上有 limit() 和 skip() 方法
print(*User.objects.limit(2), sep = '\n')
"""
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 31, is_admin: False, score: 0.0 >
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
"""
print(*User.objects.limit(2).skip(1), sep = '\n')
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c91,name: tom0, age: 47, is_admin: True, score: 0.0 >
"""
但数组切片语法更受青睐:
# 只有前5个人
users = User.objects[:5]
# 除了前5个人之外的所有人
users = User.objects[5:]
# 从第11个用户开始,取5个用户。
users = User.objects[10:15]
您还可以通过索引来检索单个结果。
如果该索引处的项目不存在,则会引发IndexError。
还提供了一个用于检索第一个结果并在没有结果存在时返回None的快捷方式(first()):
# 确保没有条目
User.drop_collection()
User.objects[0]
"""
会报错
Traceback (most recent call last):
File "E:\Codes\python\mengma\mm_api\测试mongoEngine的使用.py", line 86, in <module>
print(User.objects[0])
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\mongoengine\queryset\base.py", line 203, in __getitem__
queryset._cursor[key],
File "E:\Codes\python\mengma\mm_api\venv\lib\site-packages\pymongo\cursor.py", line 769, in __getitem__
raise IndexError("no such item for Cursor instance")
IndexError: no such item for Cursor instance
"""
print(User.objects.first())
"""
None
"""
# 存入数据
User(name='Test User').save()
print(User.objects[0] == User.objects.first())
"""
None
"""
聚合
https://mongoengine-odm.readthedocs.io/guide/querying.html#aggregation
MongoDB 提供了开箱即用的聚合方法,但并不像通常的 RDBMS 那样多。
MongoEngine 在内置方法周围提供了一个包装器,并提供了自己的实现,这些实现作为 JavaScript 代码在数据库服务器上执行。
统计
num_users = User.objects.count()
从技术上讲,您可以使用 len(User.objects) 来获得相同的结果,但它的速度会比 count() 慢得多。
当您执行一个服务器端 count 查询时,您让 MongoDB 进行繁重的工作,并通过网络接收一个整数。
同时,len() 检索所有结果,将它们放入本地缓存,并最后计算它们。如果我们比较这两种操作的性能,len() 比 count() 慢得多。
求和
yearly_expense = Employee.objects.sum('salary')
如果字段在文档中不存在,则该文档将从总和中被忽略。
求平均数
mean_age = User.objects.average('age')
MongoDB聚合API
如果你需要运行聚合管道,MongoEngine通过aggregate()方法提供了Pymongo聚合框架的入口点。
查看Pymongo的文档以了解语法和管道。
以下是使用它的一个示例:
class Person(Document):
name = StringField()
Person(name='John').save()
Person(name='Bob').save()
pipeline = [
{"$sort" : {"name" : -1}},
{"$project": {"_id": 0, "name": {"$toUpper": "$name"}}}
]
data = Person.objects().aggregate(pipeline)
print(data)
"""
[{'name': 'BOB'}, {'name': 'JOHN'}]
"""
提高查询效率和性能
https://mongoengine-odm.readthedocs.io/guide/querying.html#query-efficiency-and-performance
只获取需要的字段
通过 only() 方法,可以获取对应的字段值
其他的字段如果定义了默认值就是默认值,没有定义默认值的就是None
print(*User.objects, sep = '\n')
"""
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 31, is_admin: False, score: 0.0 >
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c91,name: tom0, age: 47, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c93,name: tom2, age: 53, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c94,name: tom3, age: 31, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c95,name: tom4, age: 34, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c96,name: tom5, age: 51, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c97,name: tom6, age: 49, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c9a,name: tom9, age: 31, is_admin: True, score: 0.0 >
"""
print(*User.objects.only('name'), sep = '\n')
"""
# 对比上面的完整数据,可以发现,当只有pk和name是真实数据,其他的都是默认值
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 20, is_admin: False, score: 0 >
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c91,name: tom0, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c93,name: tom2, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c94,name: tom3, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c95,name: tom4, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c96,name: tom5, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c97,name: tom6, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 20, is_admin: False, score: 0 >
<User pk: 658e7150ebb88eedb7969c9a,name: tom9, age: 20, is_admin: False, score: 0 >
"""
exclude()是only()的反义词,如果你想排除一个字段。
取消自动解引用
自动解引用是指MongoEngine在处理查询结果时,会自动将MongoDB文档中的ObjectId字段转换为相应的Python对象。
例如,如果MongoDB文档中有一个ObjectId字段,查询结果将返回一个ObjectId类型的Python对象,而不是原始的字符串表示。
from mongoengine import connect, Document, fields
# 连接到MongoDB数据库
connect('mydatabase')
# 定义一个自定义文档类
class MyDocument(Document):
id = fields.ObjectIdField()
# 创建一个MyDocument对象并保存到数据库
my_doc = MyDocument(id = 'some_object_id')
my_doc.save()
# 执行查询操作
results = MyDocument.objects(id = 'some_object_id')
# 输出查询结果中的id字段
for result in results:
print(result.id) # 输出: ObjectId('some_object_id') 这就是自动解引用
# 关闭自动解引用
for res in MyDocument.objects(id = 'some_object_id').no_dereference():
print(res.id) # 输出: some_object_id 输出的就是字符串,而没有转换为ObjectId对象
Q对象查询
from mongoengine.queryset.visitor import Q
# 两个q对象的或运算
Post.objects(Q(published=True) | Q(publish_date__lte=datetime.now()))
# 两个Q对象的与结果再跟另外一个Q对象求或
Post.objects((Q(featured=True) & Q(hits__gte=1000)) | Q(hits__gte=5000))
必须使用位运算。
不能使用 or 或 and 来组合查询,因为 Q(a=a) or Q(b=b) 并不等同于 Q(a=a) | Q(b=b)。
因为 Q(a=a) 等于 true,所以 Q(a=a) or Q(b=b) 等于 Q(a=a)。
修改
https://mongoengine-odm.readthedocs.io/guide/querying.html#atomic-updates
可以使用 QuerySet 上的 update_one()、update() 和 modify() 方法,或者 Document 上的 modify() 和 save()(带有 save_condition 参数)来原子性地更新文档。
对Document修改
通过save() 方法完成修改
u1 = User.objects(name = "tom").first()
print(u1)
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 0.0 >
"""
u1.score = 50
u1.save()
print(u1)
"""
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 50 >
"""
对 QuerySet 进行修改
操作符
set– 设置一个特定的值set_on_insert– 仅当这是新文档时才设置,需要添加upsert=Trueunset– 删除特定值(自MongoDB v1.3起)inc– 将一个值增加一个给定的量push– 向列表中添加一个值push_all– 将多个值附加到一个列表中pop– 根据值删除列表的第一个或最后一个元素pull– 从列表中删除一个值pull_all– 从列表中删除多个值add_to_set– 仅当值不在列表中时,才向列表中添加值
update_one()
u1 = User.objects(age__lte = 30)
print(*u1, sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
"""
u1.update_one(set__score = 1)
for u in u1:
u.reload() # 文档已经更改,所以我们需要重新加载它。
print(*u1, sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 100.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
"""
update()
u1 = User.objects(age__lte = 30)
print(*u1, sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 0.0 >
"""
u1.update(set__score = 100)
for u in u1:
u.reload()
print(*u1, sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 100.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 100.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 100.0 >
"""
原生语句
使用 __raw__ 属性
u1.update(__raw__={"$set": {"age": 55}})
其他例子
# inc
u1.update(inc__score = 100)
for u in u1:
u.reload()
print(*u1, sep = '\n')
"""
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 22, is_admin: True, score: 200.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 200.0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 200.0 >
"""
# 如果是减的话,需要使用原生语句
u1.update(__raw__={"$inc": {"score": -20}})
# unset
u1.update_one(unset__score=1)# 删掉第一个文档的score字段
如果没有指定修饰符操作符,则默认值为$set。因此,以下句子是相同的:
BlogPost.objects(id=post.id).update(title='Example Post')
BlogPost.objects(id=post.id).update(set__title='Example Post')
删除
users = User.objects(age__in=[20, 33])
print(*users)
users.delete()
print(*User.objects)
同时维护多套配置
from mongoengine import connect, QuerySet, register_connection, connection
from mongoengine import Document, StringField, IntField, BooleanField, FloatField
conf1 = {
"db" : "test1",
"host" : "10.0.0.12",
"port" : 27017,
"username": "root",
"password": "111111"
}
# 设置第一个数据库连接 别名为a1 如果不指定别名,就是default
connect(alias = "a1", **conf1)
class User1(Document):
meta = {
"collection": "users",
"db_alias" : "a1" #重点是需要在元数据meta中明确指定对应的连接别名,否则会被是为default的连接
}
name = StringField(min_length = 2, max_length = 10, required = True, unique = True)
age = IntField(min_value = 18, max_value = 150, default = 20)
is_admin = BooleanField(default = False)
score = FloatField(min_value = 0, max_value = 100, default = 0)
def __str__(self):
return "<User pk: %s,name: %s, age: %s, is_admin: %s, score: %s >" % (
self.pk, self.name, self.age, self.is_admin, self.score
)
# 创建第二套配置
conf2 = {
"db" : "test2",
"host" : "10.0.0.12",
"port" : 27017,
"username": "root",
"password": "111111"
}
# 注册第二个数据库连接,给它一个别名 'a2'
register_connection(alias = "a2", **conf2)
class User2(Document):
meta = {
"collection": "users",
"db_alias" : "a2" # 同样指定连接的别名
}
username = StringField(min_length = 2, max_length = 10)
password = StringField(min_length = 2, max_length = 10)
def __str__(self):
return "<User pk: %s,username: %s, password: %s>" % (
self.pk, self.username, self.password
)
# 可以看到有两套配置
print(connection._connection_settings)
"""
{
"a1": {
"name": "test1",
"host": [
"10.0.0.12"
],
"port": 27017,
"read_preference": Primary(),
"username": "root",
"password": "111111",
"authentication_source": None,
"authentication_mechanism": None,
"authmechanismproperties": None,
"uuidRepresentation": "pythonLegacy"
},
"a2": {
"name": "test2",
"host": [
"10.0.0.12"
],
"port": 27017,
"read_preference": Primary(),
"username": "root",
"password": "111111",
"authentication_source": None,
"authentication_mechanism": None,
"authmechanismproperties": None,
"uuidRepresentation": "pythonLegacy"
}
}
"""
# 但是连接目前只有一个
print(connection._connections)
"""
{
"a1": MongoClient(
host=["10.0.0.12:27017"],
document_class=dict,
tz_aware=False,
connect=True,
read_preference=Primary(),
uuidrepresentation=3
)
}
"""
# 使用User1模型,调用的就是别名为a1的连接
u1 = User1.objects
print(*u1, sep = "\n")
"""
<User pk: 658e6fc77124acd9148ba183,name: jerry, age: 31, is_admin: False, score: 0.0 >
<User pk: 658e704e675617d32afa4fa4,name: tom, age: 55, is_admin: True, score: 50.0 >
<User pk: 658e7150ebb88eedb7969c91,name: tom0, age: 47, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c92,name: tom1, age: 20, is_admin: True, score: 180.0 >
<User pk: 658e7150ebb88eedb7969c93,name: tom2, age: 53, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c94,name: tom3, age: 31, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c95,name: tom4, age: 34, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c96,name: tom5, age: 51, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c97,name: tom6, age: 49, is_admin: True, score: 0.0 >
<User pk: 658e7150ebb88eedb7969c98,name: tom7, age: 28, is_admin: True, score: 0 >
<User pk: 658e7150ebb88eedb7969c99,name: tom8, age: 25, is_admin: True, score: 180.0 >
<User pk: 658e7150ebb88eedb7969c9a,name: tom9, age: 31, is_admin: True, score: 0.0 >
"""
print("+" * 80)
# 使用User2模型就调用的是别名为a2的连接
u2 = User2.objects
print(*u2, sep = "\n")
"""
<User pk: 65957e05081198574f002891,username: john0, password: aaaaaaa>
<User pk: 65957e05081198574f002892,username: john1, password: aaaaaaa>
<User pk: 65957e05081198574f002893,username: john2, password: aaaaaaa>
<User pk: 65957e05081198574f002894,username: john3, password: aaaaaaa>
<User pk: 65957e05081198574f002895,username: john4, password: aaaaaaa>
<User pk: 65957e05081198574f002896,username: john5, password: aaaaaaa>
<User pk: 65957e05081198574f002897,username: john6, password: aaaaaaa>
<User pk: 65957e05081198574f002898,username: john7, password: aaaaaaa>
<User pk: 65957e05081198574f002899,username: john8, password: aaaaaaa>
<User pk: 65957e05081198574f00289a,username: john9, password: aaaaaaa>
"""
# 最后会发现,连接变成了两个,因为这里是懒连接
print(connection._connections)
"""
{
"a1": MongoClient(
host=["10.0.0.12:27017"],
document_class=dict,
tz_aware=False,
connect=True,
read_preference=Primary(),
uuidrepresentation=3
),
"a2": MongoClient(
host=["10.0.0.12:27017"],
document_class=dict,
tz_aware=False,
connect=True,
read_preference=Primary(),
uuidrepresentation=3
)
}
"""
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/17940976



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 25岁的心里话
· 按钮权限的设计及实现