RabbitMQ工作原理及应用
工作模式
https://www.rabbitmq.com/getstarted.html
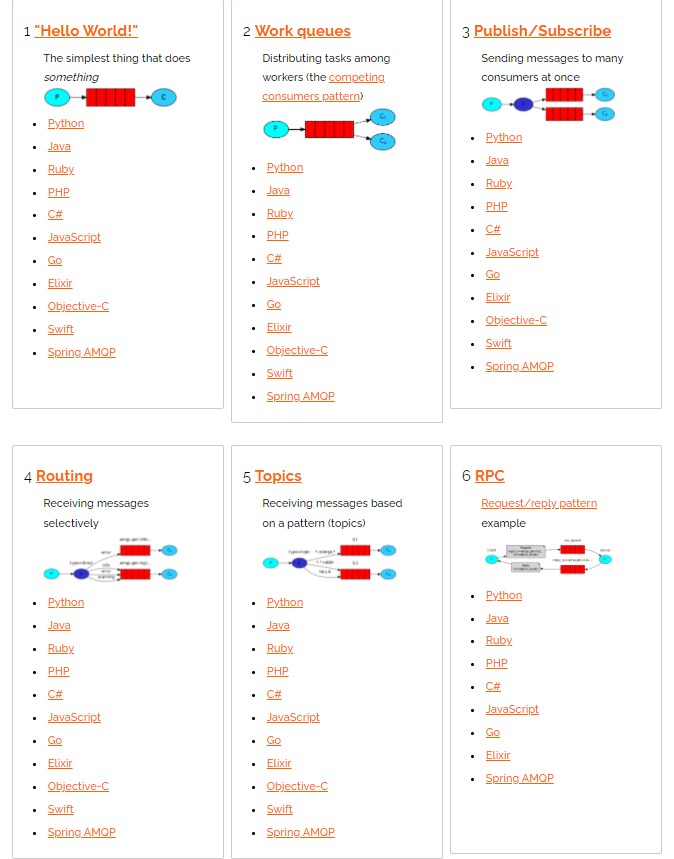
上图,列出了RabbitMQ的使用模式,学习上面的模式,对理解所有消息队列都很重要。
名词解释
| 名词 | 说明 |
|---|---|
| server | 服务器 接收客户端连接,实现消息队列及路由功能的进程(服务),也称为 消息代理 注意,客户端是生产者,也可以是消费者,它们都需要连接到Server |
| Connection | 网络物理连接 |
| Channel | 一个连接允许多个客户端连接 |
| Exchange | 交换器。接收生产者发来的消息,决定如何路由给服务器中的队列。 常用的类型有: direct (point-to-point)点对点 topic (publish-subscribe)话题 高级路由 fanout (multicast)广播 |
| Message | 消息 |
| Message Queue |
消息队列 数据的存储载体 |
| Bind | 绑定 建立消息队列和交换器之间的关系,也就是说交换器拿到数据,把什么样的数据 送给哪个队列 |
| Virtual Host | 虚拟主机 一批交换机、消息队列和相关对象的集合。为了多用户互不干扰,使用虚拟主机 分组交换机、消息队列 |
| Topic | 主题、话题 |
| Broker | 可等价为Server |
1、队列
https://www.rabbitmq.com/tutorials/tutorial-one-python.html
这种模式就是最简单的 生产者消费者模型,消息队列就是一个FIFO的队列

生产者send.py,消费者receive.py
官方例子
https://www.rabbitmq.com/tutorials/tutorial-one-python.html
参照官方例子,写一个程序
生产者
# send.py 生产者代码
import pika
from pika.credentials import PlainCredentials
# #连接的参数
# param=pika.ConnectionParameters(
# #服务器地址
# host='10.0.0.5',
# #服务器amqp端口
# port='5672',
# #虚拟主机
# virtual_host='test',
# #用户
# credentials=PlainCredentials('hxg','hxg')
# )
#或者通过URL的方式来添加参数
param=pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
#创建连接
connection = pika.BlockingConnection(param)
#创建通道
channel = connection.channel()
#声明队列,如果没有,就创建 hello是队列名
channel.queue_declare(queue='hello')
#生产任务
channel.basic_publish(exchange='',#指定交换机,用来路由的,如果不指定,就是默认交换机
routing_key='hello',#指定队列
body='Hello World!')#任务
print("发送成功 'Hello World!'")
#关闭通道
channel.close()
在ConnectionParameters中并没有用户名、密码填写的参数,它使用参数credentials传入,这需要构建一个pika.credentials.Credentials对象。
import pika
from pika.credentials import PlainCredentials
#连接的参数
param=pika.ConnectionParameters(
#服务器地址
host='10.0.0.5',
#服务器amqp端口
port='5672',
#虚拟主机
virtual_host='test',
#用户
credentials=PlainCredentials('hxg','hxg')
)
也可以改成URL的方式
param=pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
- queue_declare声明一个queue,有必要的话,创建它
- basic_publish exchange为空就使用缺省exchange,如果找不到指定的exchange,抛异常
使用缺省exchange,就必须指定routing_key,使用它找到queue
receive.py 消费者代码
批量消费消息
# recieve.py 消费者代码
import pika
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
conn = pika.BlockingConnection(param)
# 创建通道
chann = conn.channel()
# 声明队列,没有则创建
chann.queue_declare(queue='hello')
# 消费函数
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 消费
chann.basic_consume(
# 指定队列
queue='hello',
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
# 阻塞等待任务
chann.start_consuming()
2、工作队列
https://www.rabbitmq.com/tutorials/tutorial-two-python.html
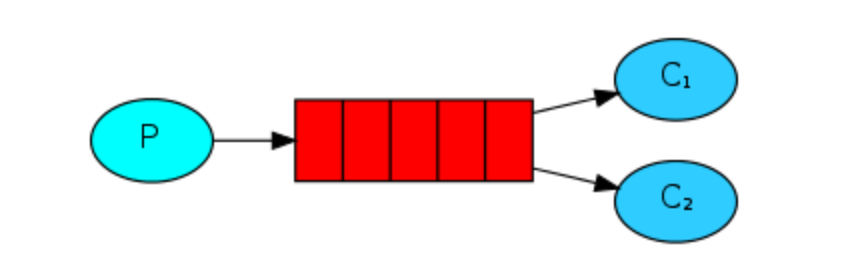
两种方式:
- 继续使用队列模式的生产者和消费者代码,启动2个消费者
- 修改消费者代码,增加basic_consume方法
# recieve.py 消费者代码
import pika
params = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
connection = pika.BlockingConnection(params)
def callback(channel, method, properties, body):
print('Get a message = {}'.format(body))
def callback1(channel, method, properties, body):
print('Get a message1 = {}'.format(body))
with connection:
channel = connection.channel()
# 消费者,每一个消费者使用一个basic_consume
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback)
channel.basic_consume(queue=queue_name,
auto_ack=True,
on_message_callback=callback1)
print('Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
观察结果,可以看到,2个消费者是交替拿到不同的消息。
这种工作模式是一种竞争工作方式,对某一个消息来说,只能有一个消费者拿走它。
从结果知道,使用的是轮询方式拿走数据的。
如果启动2个消费者解释器进程,实际上就有了4个消费者,还是采用轮询来获取消息。
注意:虽然上面的图中没有画出exchange,用到缺省exchange。
应答
消息队列一般需要缓冲成千上万条消息,队列中消息只有一份,只能给一个消费者处理。消费者读取一个消息后,需要给RabbitMQ Server一个确认(acknowledgement),然后RabbitMQ才会删除它。
默认basic_consume中auto_ack为False,也就是需要手动确认收到了,不会自动回应。
持久化
交换机、队列都不会持久化,如需持久化需要交换机、队列设置durable为True。
消息持久化,需要队列首先持久化,然后生产者发布消息时增加持久化属性。
- 交换机持久化
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 交换机声明
# durable=True 持久化交换机
channel.exchange_declare(durable=True)
- 队列持久化
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 声明队列,如果没有,就创建 hello是队列名
# durable=True 持久化队列
channel.queue_declare(queue='hello', durable=True)
- 消息持久化
消息持久化的前提是队列也持久化
properties=pika.BasicProperties(delivery_mode=2),
添加参数,delivery_mode是持久化的参数,1表示不持久化,2表示持久化
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 声明队列,如果没有,就创建 hello是队列名
# durable=True 持久化队列
channel.queue_declare(queue='hello', durable=True)
# 生产任务
channel.basic_publish(exchange='', # 指定交换机,用来路由的,如果不指定,就是默认交换机
routing_key='hello', # 指定队列
properties=pika.BasicProperties(delivery_mode=2),# 添加参数,delivery_mode是持久化的参数,1表示不持久化,2表示持久化
body='data-{}'.format(i + 1)) # 任务
特别注意,持久化不能保证百分之百消息不丢失,如果数据在缓存中,还未真正写入磁盘,数据还是有部分丢失的风险。
公平分发
上面的轮询方式,不管消费者是否空闲还是繁忙,只是看似公平的分发,但其实Server没有关注消费者未确认消息数。
使用basic_qos(prefetch_count=1)来解决,该方法告诉RabbitMQ不要一直给消费者发多条消息,如果消费者为确认上一条消息,就不要给它发了,发给别的不忙的消费者。
(推荐在direct交换机模式下配置)
# 消费者1
def callback(ch, method, properties, body):
print("{}-{}".format('c1', body))
time.sleep(5) # 故意放慢处理
channel.basic_ack(delivery_tag = method.delivery_tag) # 手动应答
with connection:
#一定是在消费前设置qos
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue=qname,
auto_ack=False, # 默认为False,手动应答
on_message_callback=callback)
channel.start_consuming()
# 消费者2
def callback(ch, method, properties, body):
print("{}-{}".format('c2', body))
channel.basic_ack(delivery_tag = method.delivery_tag) # 手动应答
with connection:
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue=qname,
auto_ack=False, # 默认为False,手动应答
on_message_callback=callback)
channel.start_consuming()
注意:经测试,在自动应答的情况下,如果消费者处理时间过长,会报错,如图所示
所以,强烈建议手动应答

3、发布、订阅模式
https://www.rabbitmq.com/tutorials/tutorial-three-python.html
Publish/Subscribe发布和订阅,想象一下订阅报纸,所有订阅者(消费者)订阅这个报纸(消息),都应该拿到一份同样内容的报纸。
订阅者和消费者之间还有一个exchange,可以想象成邮局,消费者去邮局订阅报纸,报社发报纸到邮局,邮局决定如何投递到消费者手中。
上例中工作队列模式的使用,相当于,每个人只能拿到不同的报纸。所以,不适用发布订阅模式。
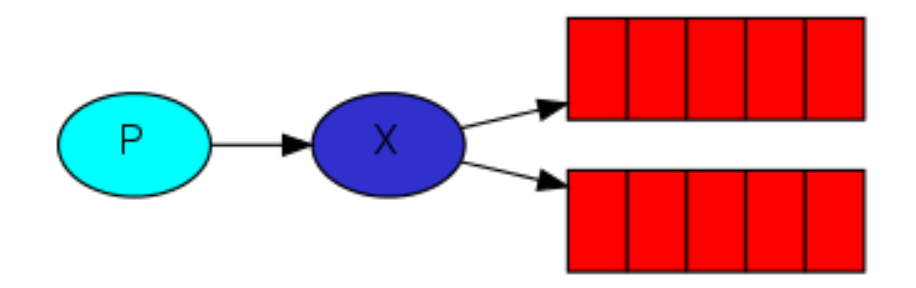
当前模式的exchange的type是fanout,就是一对多,即广播模式。
注意,同一个queue的消息只能被消费一次,所以,这里使用了多个queue,相当于为了保证不同的消费者拿到同样的数据,每一个消费者都应该有自己的queue。
# 生成一个交换机
channel.exchange_declare(
exchange='logs', # 新交换机
exchange_type='fanout' # 广播
)
生产者使用广播模式。
在test虚拟主机主机下构建了一个logs交换机。这个交换机不持久的,服务重启就消失了。一般也不需要持久,如果需要持久,设置参数durable=True。
至于queue,可以由生产者创建,也可以由消费者创建。
本次采用使用消费者端创建,生产者把数据发往交换机logs,采用了fanout,然后将数据通过交换机发往已经绑定到此交换机的所有queue。
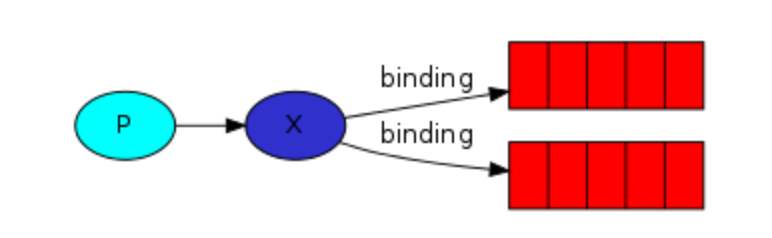
绑定Bingding,建立exchange和queue之间的联系
result = channel.queue_declare(queue='') # 生成一个随机名称的queue 重启之后才消失
result = channel.queue_declare(queue='', exclusive=True) # 生成一个随机名称的queue 断开连接就消失
exclusive意思是只允许当前connection访问,当前连接断开时删除queue
# 消费者端
# 生成queue
q1 = channel.queue_declare(queue='', exclusive=True)
q2 = channel.queue_declare(queue='', exclusive=True)
q1name = q1.method.queue # 可以通过q1.method.queue 查看随机名称
q2name = q2.method.queue
print(q1name, q2name)
# 绑定
channel.queue_bind(exchange='logs', queue=q1name)
channel.queue_bind(exchange='logs', queue=q2name)
生产者代码
注意观察 交换机和队列
import pika
from pika.credentials import PlainCredentials
from time import sleep
n = 10
ex_name = 'log'
ex_type = 'fanout'
# 或者通过URL的方式来添加参数
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 交换机声明
channel.exchange_declare(
exchange=ex_name,
exchange_type=ex_type
)
#因为本次使用消费者端创建,所以生产者不需要声明
# 声明队列,如果没有,就创建 hello是队列名
# channel.queue_declare(queue='hello')
for i in range(n):
# 生产任务
channel.basic_publish(exchange=ex_name, # 指定交换机,用来路由的,如果不指定,就是默认交换机
routing_key='', # 指定队列,当交换机为fanout模式时,不需要指定
# properties=pika.BasicProperties(delivery_mode=2),# 添加参数,delivery_mode是持久化的参数,1表示不持久化,2表示持久化
body='data-{}'.format(i + 1)) # 任务
sleep(0.5)
print("发送成功 'Hello World!'")
消费者代码
构建queue并绑定到test虚拟主机的log交换机上
import time
import pika
from pika.frame import Method
from pika.adapters.blocking_connection import BlockingChannel
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
ex_name = 'log'
ex_type = 'fanout'
# 创建连接
with pika.BlockingConnection(param) as conn:
# 创建通道
channel = conn.channel()
# 声明交换机
channel.exchange_declare(exchange=ex_name, exchange_type=ex_type)
# 声明队列,没有则创建
q1: Method = channel.queue_declare(queue='', exclusive=True)
q1_name = q1.method.queue
q2: Method = channel.queue_declare(queue='', exclusive=True)
q2_name = q2.method.queue
# 绑定
channel.queue_bind(queue=q1_name, exchange=ex_name)
channel.queue_bind(queue=q2_name, exchange=ex_name)
# 消费函数
def callback(ch: BlockingChannel, method, properties, body):
print('队列名:{} 交换机:{} 数据的次序:{} 数据:{}'.format(method.consumer_tag, method.exchange, method.delivery_tag, body))
# 消费
channel.basic_consume(
# 指定队列
queue=q1_name,
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
channel.basic_consume(
# 指定队列
queue=q2_name,
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
# 阻塞等待任务
channel.start_consuming()
先启动消费者可以看到已经创建了exchange
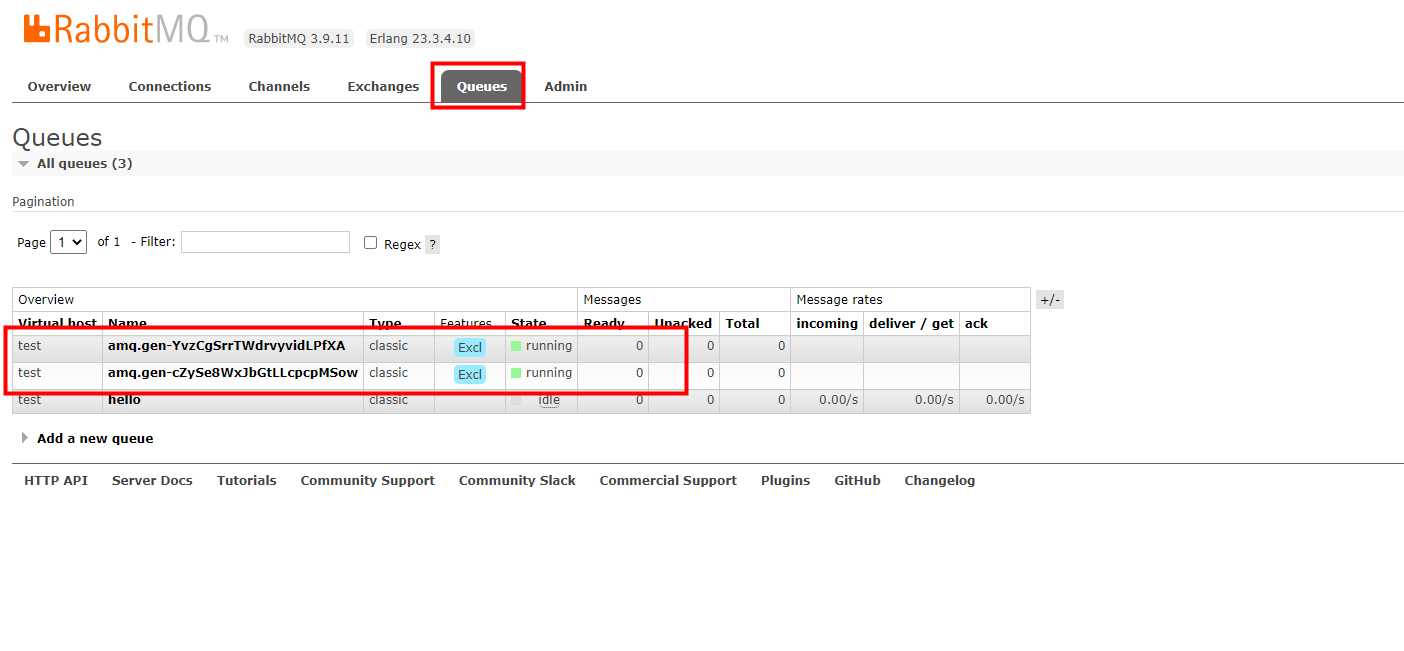
如果exchange是fanout,也就是广播了,routing_key(路由)就不需要了
交换机也已经创建了
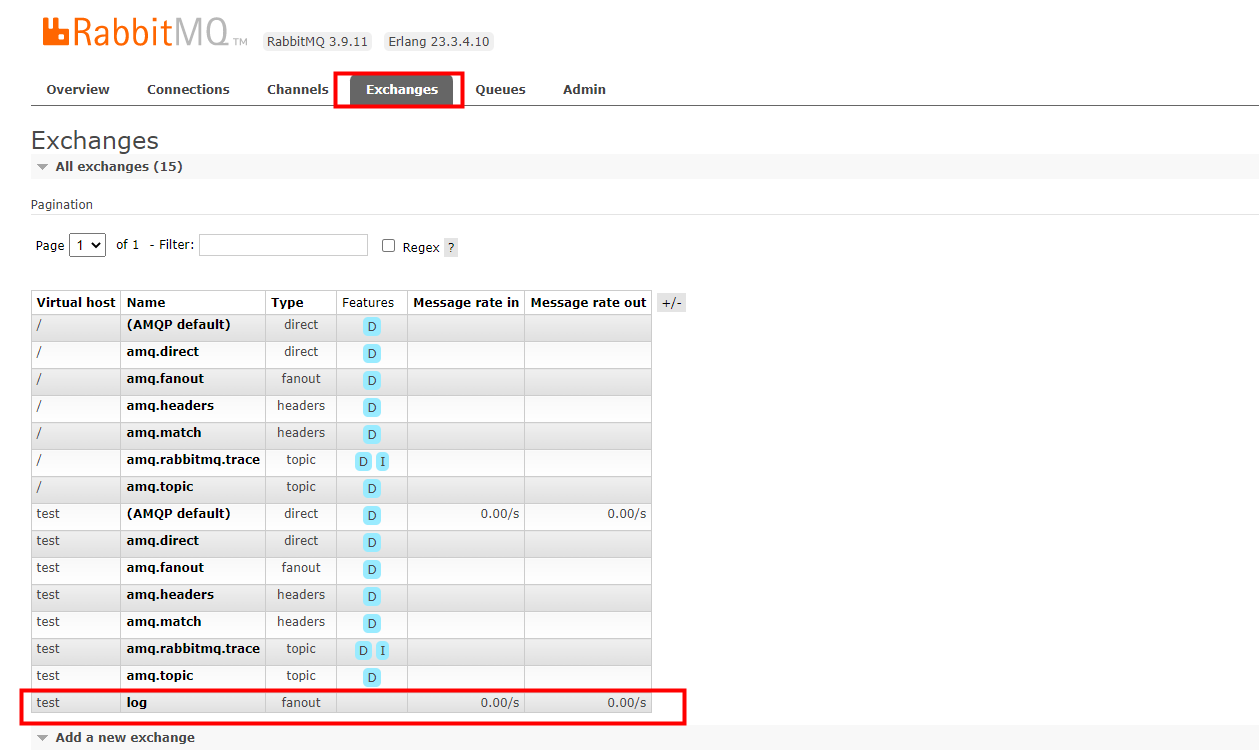
尝试先启动生产者,再启动消费者试试看。
部分数据丢失,因为,exchange收到了数据,没有queue接收,所以,exchange丢弃了这些数据。
4、路由Routing
https://www.rabbitmq.com/tutorials/tutorial-four-python.html
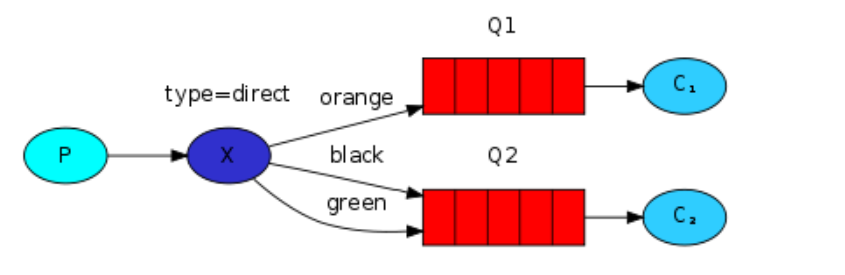
路由其实就是生成者的数据经过exchange的时候,通过匹配规则,决定数据的去向。
生产者代码
交换机类型为direct,指定路由的key
import pika
from pika.credentials import PlainCredentials
from time import sleep
from random import choice
n = 20
ex_name = 'log'
ex_type = 'direct'
l = ('red', 'black', 'green')
# 或者通过URL的方式来添加参数
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 交换机声明
channel.exchange_declare(exchange=ex_name, exchange_type=ex_type)
# 声明队列,如果没有,就创建 hello是队列名
channel.queue_declare(queue='a')
channel.queue_declare(queue='b')
for i in range(n):
rk = choice(l)
# 生产任务
channel.basic_publish(exchange=ex_name, # 指定交换机,用来路由的,如果不指定,就是默认交换机
routing_key=rk, # 指定路由
# properties=pika.BasicProperties(delivery_mode=2),# 添加参数,delivery_mode是持久化的参数,1表示不持久化,2表示持久化
body='{}------data-{}'.format(rk, i + 1)) # 任务
sleep(1)
print("发送成功 'Hello World!'")
消费者代码
import time
import pika
from pika.frame import Method
from pika.adapters.blocking_connection import BlockingChannel
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
ex_name = 'log'
ex_type = 'direct'
l = ('red', 'black', 'green')
# 创建连接
with pika.BlockingConnection(param) as conn:
# 创建通道
channel = conn.channel()
# 声明交换机
channel.exchange_declare(exchange=ex_name, exchange_type=ex_type)
# 声明队列,没有则创建
channel.queue_declare(queue='a')
channel.queue_declare(queue='b')
# 绑定
channel.queue_bind(queue="a", exchange=ex_name, routing_key=l[0])
channel.queue_bind(queue="b", exchange=ex_name, routing_key=l[1])
channel.queue_bind(queue="b", exchange=ex_name, routing_key=l[2])
# 消费函数
def callback(ch, method, properties, body):
print('队列名:{} 交换机:{} 数据的次序:{} 数据:{}'.format(method.consumer_tag, method.exchange, method.delivery_tag, body))
# 消费
channel.basic_consume(
# 指定队列
queue="a",
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
channel.basic_consume(
# 指定队列
queue="b",
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
# 阻塞等待任务
channel.start_consuming()
绑定结果

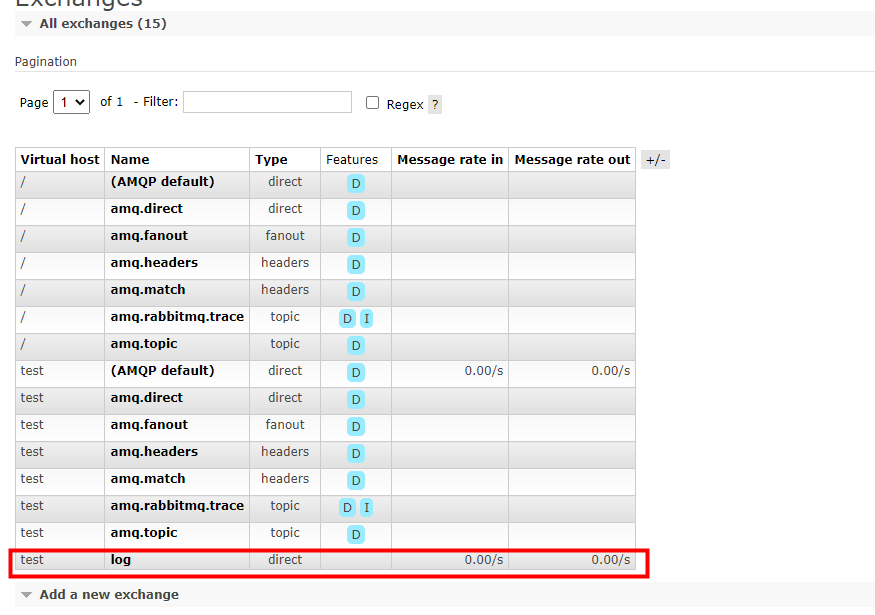

5、Topic 话题
https://www.rabbitmq.com/tutorials/tutorial-five-python.html
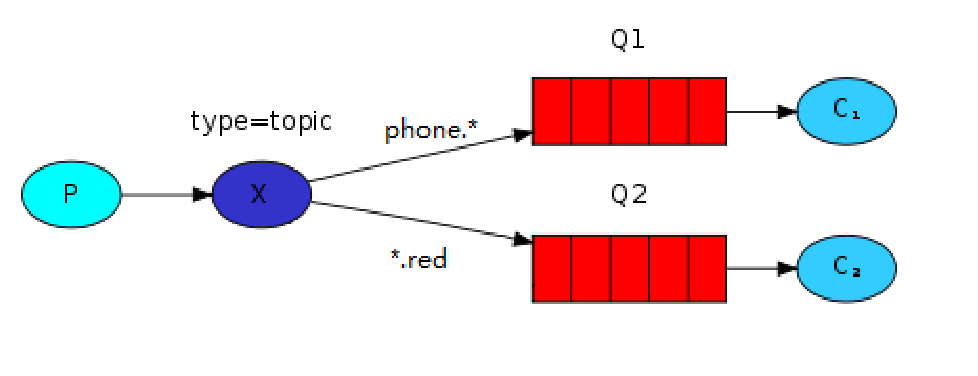
Topic就是更加高级的路由,支持模式匹配而已。
Topic的routing_key必须使用 . 点号分割的单词组成。最多255个字节。
支持使用通配符:
*表示严格的一个单词#表示0个或者多个单词
如果queue绑定的routing_key只是一个#,这个queue其实可以接收所有的消息。
如果没有使用任何通配符,效果类似于direct,因为只能和字符匹配了。
生产者代码
import pika
from pika.credentials import PlainCredentials
from time import sleep
from random import choice
n = 20
ex_name = 'log'
ex_type = 'topic'
s = ('phone', 'pc', 'tv')
l = ('red', 'black', 'green')
# 或者通过URL的方式来添加参数
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
# 创建连接
with pika.BlockingConnection(param) as connection:
# 创建通道
channel = connection.channel()
# 交换机声明
channel.exchange_declare(exchange=ex_name, exchange_type=ex_type)
# 声明队列,如果没有,就创建 hello是队列名
channel.queue_declare(queue='a')
channel.queue_declare(queue='b')
for i in range(n):
rk = '{}.{}'.format(choice(s), choice(l))
msg = '{}------data-{}'.format(rk, i + 1)
# 生产任务
channel.basic_publish(exchange=ex_name, # 指定交换机,用来路由的,如果不指定,就是默认交换机
routing_key=rk, # 指定队列,当交换机为fanout模式时,不需要指定
# properties=pika.BasicProperties(delivery_mode=2),# 添加参数,delivery_mode是持久化的参数,1表示不持久化,2表示持久化
body=msg) # 任务
print('消息是:', msg)
sleep(1)
print("发送成功 'Hello World!'")
"""
消息是: tv.green------data-1
消息是: phone.red------data-2
消息是: pc.black------data-3
消息是: tv.red------data-4
消息是: phone.red------data-5
消息是: tv.red------data-6
消息是: phone.green------data-7
消息是: pc.green------data-8
消息是: tv.green------data-9
消息是: phone.red------data-10
消息是: phone.red------data-11
消息是: pc.green------data-12
消息是: tv.green------data-13
消息是: pc.green------data-14
消息是: pc.black------data-15
消息是: phone.black------data-16
消息是: pc.red------data-17
消息是: pc.green------data-18
消息是: phone.black------data-19
消息是: pc.red------data-20
发送成功 'Hello World!'
"""
消费者代码
import time
import pika
from pika.frame import Method
from pika.adapters.blocking_connection import BlockingChannel
param = pika.URLParameters('amqp://hxg:hxg@10.0.0.5:5672/test')
ex_name = 'log'
ex_type = 'topic'
s = ('phone', 'pc', 'tv')
l = ('red', 'black', 'green')
rule = ('tv.*', '*.red')
# 创建连接
with pika.BlockingConnection(param) as conn:
# 创建通道
channel = conn.channel()
# 声明交换机
channel.exchange_declare(exchange=ex_name, exchange_type=ex_type)
# 声明队列,没有则创建
q1: Method = channel.queue_declare(queue='a')
q1_name = q1.method.queue
q2: Method = channel.queue_declare(queue='b')
q2_name = q2.method.queue
# 绑定
channel.queue_bind(queue=q1_name, exchange=ex_name, routing_key=rule[0])
channel.queue_bind(queue=q2_name, exchange=ex_name, routing_key=rule[1])
# 消费函数
def callback(ch, method, properties, body):
print('队列名:{} 交换机:{} 数据的次序:{} 数据:{}'.format(method.consumer_tag, method.exchange, method.delivery_tag, body))
# 消费
channel.basic_consume(
# 指定队列
queue=q1_name,
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
channel.basic_consume(
# 指定队列
queue=q2_name,
# 自动确认
auto_ack=True,
# 执行的函数
on_message_callback=callback
)
# 阻塞等待任务
channel.start_consuming()
"""
队列名:ctag1.7544295fac6a4b2383e9c3280dc64929 交换机:log 数据的次序:1 数据:b'tv.green------data-1'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:2 数据:b'phone.red------data-2'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:3 数据:b'tv.red------data-4'
队列名:ctag1.7544295fac6a4b2383e9c3280dc64929 交换机:log 数据的次序:4 数据:b'tv.red------data-4'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:5 数据:b'phone.red------data-5'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:6 数据:b'tv.red------data-6'
队列名:ctag1.7544295fac6a4b2383e9c3280dc64929 交换机:log 数据的次序:7 数据:b'tv.red------data-6'
队列名:ctag1.7544295fac6a4b2383e9c3280dc64929 交换机:log 数据的次序:8 数据:b'tv.green------data-9'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:9 数据:b'phone.red------data-10'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:10 数据:b'phone.red------data-11'
队列名:ctag1.7544295fac6a4b2383e9c3280dc64929 交换机:log 数据的次序:11 数据:b'tv.green------data-13'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:12 数据:b'pc.red------data-17'
队列名:ctag1.d454e698a8aa4474b9fd8f218967c887 交换机:log 数据的次序:13 数据:b'pc.red------data-20'
"""
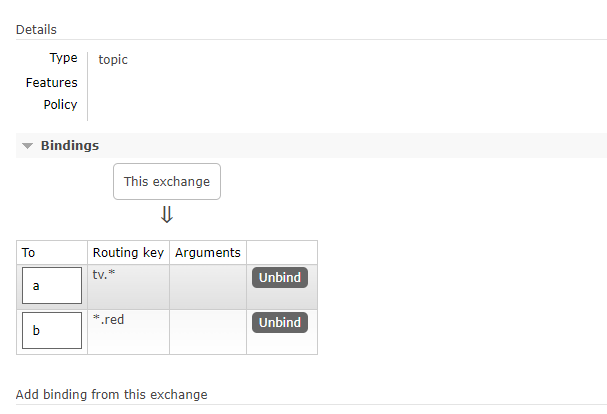
观察消费者拿到的数据,注意观察 phone.red 的数据出现的次数。
由此,可以知道 交换机在路由消息的时候,只要和queue的routing_key匹配,就把消息发给该queue。
消息队列的作用
-
系统间解耦
-
解决生产者、消费者速度匹配
由于稍微上规模的项目都会分层、分模块开发,模块间或系统间尽量不要直接耦合,需要开放公共接口提供给别的模块或系统调用,而调用可能触发并发问题,为了缓冲和解耦,往往采用中间件技术。
RabbitMQ只是消息中间件中的一种应用程序,也是较常用的消息中间件服务。
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/17133187.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix