Python实现排序
冒泡排序
交换排序
- 相邻元素两两比较大小,有必要则交换
- 元素越小或越大,就会在数列中慢慢的交换并“浮”向顶端,如同水泡咕嘟咕嘟往上冒
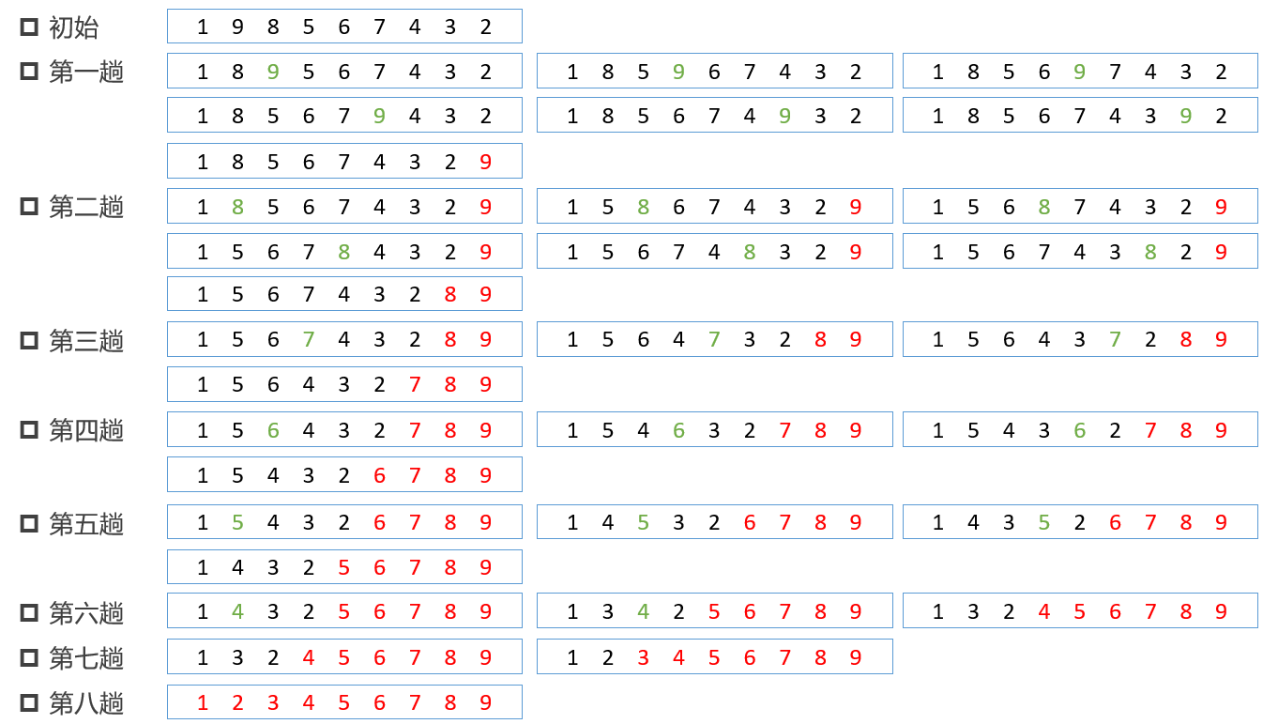
核心算法
- 排序算法,一般都实现为就地排序,输出为升序
- 扩大有序区,减小无序区。图中红色部分就是增大的有序区,反之就是减小的无序区
- 每一趟比较中,将无序区中所有元素依次两两比较,升序排序将大数调整到两数中的右侧
- 每一趟比较完成,都会把这一趟的最大数推倒当前无序区的最右侧
c = 0
b = []
n=7
while True:
a = input('输入数字:')
a = int(a)
b.append(a)
c += 1
if c == n:
break
print('原数据序列为', b)
print('最大值为', max(b))
for j in range(n-1):
for i in range(n-j-1):
if b[i] >b[i+1]:
b[i]=b[i]^b[i+1]
b[i+1]=b[i]^b[i+1]
b[i]=b[i]^b[i+1]
print('冒泡排序后的序列', b)
改进
n = 10
b=[9,8,1,2,3,4,5,6,7]
n=len(b)
print('原数据序列为', b)
for j in range(n - 1):
d = True
for i in range(n - j - 1):
if b[i] > b[i + 1]:
b[i] = b[i] ^ b[i + 1]
b[i + 1] = b[i] ^ b[i + 1]
b[i] = b[i] ^ b[i + 1]
d = False
if d:
break
print('冒泡排序后的序列', b)
print('最大值为', b[-1])
综合顺序和降序
import datetime
import time
from random import sample
from functools import wraps
def timer(fn) :
@wraps(fn)
def wraper(*args, **kwargs) :
now = time.time()
wrap_fn = fn(*args, **kwargs)
end = time.time() - now
print("耗时", end, "秒")
return wrap_fn
return wraper
@timer
def sorted(list1, desc = False) :
l = len(list1)
count = 0
if l > 0 :
# 控制排序次数
for i in range(l - 1) :
flag = True
# 控制比较次数
for j in range(l - 1 - i) :
if desc :
count += 1
# 当低序号的比高序号的小,就交换,完成降序
if list1[j] < list1[j + 1] :
list1[j], list1[j + 1] = list1[j + 1], list1[j]
flag = False
else :
count += 1
# 当低序号的比高序号的大,就交换,完成顺序
if list1[j] > list1[j + 1] :
list1[j], list1[j + 1] = list1[j + 1], list1[j]
flag = False
if flag :
break
return list1, count
if __name__ == '__main__' :
# 获取10个100以内的混乱数据
old_list = sample(range(100), k = 10)
print(old_list)
# [96, 31, 25, 38, 84, 11, 59, 10, 1, 61]
print("*" * 30)
list1, count1 = sorted(old_list) # 一万数据顺序4.3580591678619385秒
print("循环次数:", count1)
print(list1)
print("*" * 30)
list2, count2 = sorted(old_list, True) # 一万数据倒序5.853176116943359秒
print("循环次数:", count2)
print(list2)
总结
- 冒泡法需要数据一趟趟比较
- 可以设定一个标记判断此轮是否有数据交换发生,如果没有发生交换,可以结束排序,如果发生交换,继续下一轮排序
- 最差的排序情况是,初始顺序与目标顺序完全相反,遍历次数1,...,n-1之和n(n-1)/2
- 最好的排序情况是,初始顺序与目标顺序完全相同,遍历次数n-1
- 时间复杂度O(n2)
选择排序
简单选择排序
每一趟两两比较大小,找出极值(极大值或极小值)并放置到有序区的位置
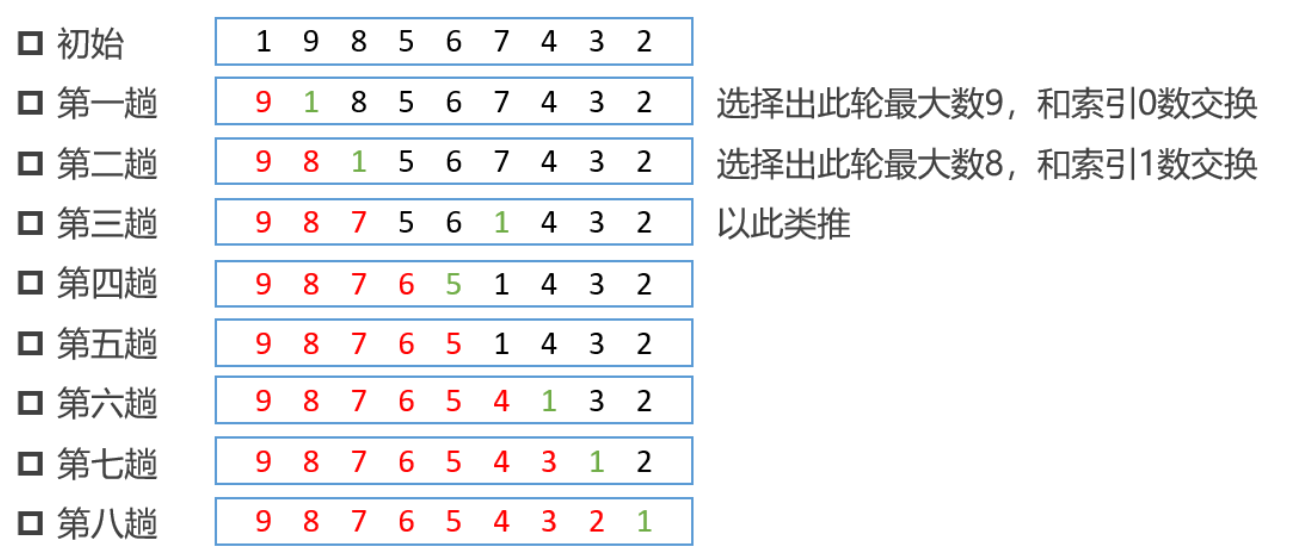
核心算法
- 结果可为升序或降序排列,默认升序排列
- 扩大有序区,减小无序区。图中红色部分就是增大的有序区,反之就是减小的无序区
- 以降序为例
- 相邻元素依次两两比较,获得每一次比较后的最大值,并记住此值的索引
- 每一趟都从无序区中选择出最大值,然后交换到当前无序区最左端
a = [3, 5, 7, 0, 8, 9, 2, 1, 4, 6]
print(a)
for i in range(len(a) - 1):
max_index = i
for j in range(i + 1, len(a)):
if a[j] > a[max_index]:
max_index = j
if max_index != i:
a[max_index], a[i] = a[i], a[max_index]
print('-'*30,a,sep='\n')
二元选择排序
改进----》同时选择出每一趟的最大值和最小值,并分别固定到两端的有序区;减少迭代的趟数
from random import sample
a = sample(range(10), k=10)
# a = [1, 0, 4, 2, 9, 6, 3, 7, 5, 8]
print(a)
for i in range(len(a) // 2):
max_index = i
min_index = i
for j in range(i + 1, len(a) - i):
if a[j] > a[max_index]:
max_index = j
elif a[j] < a[min_index]:
min_index = j
if min_index == max_index:
break
if min_index != len(a) - i - 1:
a[min_index], a[-i - 1] = a[-i - 1], a[min_index]
if max_index == len(a) - i - 1:
max_index=min_index
if max_index != i :
a[max_index], a[i] = a[i], a[max_index]
print(a, '-' * 32, sep='\n')
综合顺序倒序
import time
from random import sample
from functools import wraps
def timer(fn) :
@wraps(fn)
def wraper(*args, **kwargs) :
now = time.time()
wrap_fn = fn(*args, **kwargs)
end = time.time() - now
print("耗时", end, "秒")
return wrap_fn
return wraper
@timer
def sorted(l, desc = False) :
le = len(l)
count = 0
# [96, 31, 25, 38, 84, 11, 59, 10, 1, 61]
# 对半循环
for i in range(le // 2) :
# 假定最大值和最小值的序号都是每次遍历的的一个
max = min = i
for j in range(i + 1, le - i) :
count += 1
# 遍历取到此次遍历则最大和最小值的序号
if l[j] > l[max] :
max = j
elif l[j] < l[min] :
min = j
# 如果最大值和最小值的序号一样,表示此次遍历的都是同样大小的,剩下的就不必遍历了
if max == min :
break
# 如果是倒序
if desc :
# 判断最小的需要是不是在此次遍历的最后一位上
if min != le - i - 1 :
# 如果不是就交换位置
l[min], l[-i - 1] = l[-i - 1], l[min]
# 如果最大值又刚好是在交换位置前的最后一个位置上,就需要把最小值的序号给最大值序号
if max == le - i - 1 :
max = min
# 如果最大值序号不再此次遍历的第一个,就交换
if max != i :
l[max], l[i] = l[i], l[max]
# 如果是顺序
else :
# 顺序逻辑与倒序刚好相反
if max != le - i - 1 :
l[max], l[-i - 1] = l[-i - 1], l[max]
if min == le - i - 1 :
min = max
if min != i :
l[min], l[i] = l[i], l[min]
return l, count
if __name__ == '__main__' :
# 获取10个100以内的混乱数据
old_list = sample(range(100), k = 10)
print(old_list)
# [96, 31, 25, 38, 84, 11, 59, 10, 1, 61]
print("*" * 30)
list1, count1 = sorted(old_list) # 一万数据顺序1.127711296081543秒
print("循环次数:", count1)
print(list1)
print("*" * 30)
list2, count2 = sorted(old_list, True) # 一万数据倒序0.7428731918334961
print("循环次数:", count2)
print(list2)
总结
- 简单选择排序需要数据一趟趟比较,并在每一趟中发现极值
- 没有办法知道当前这一趟是否已经达到排序要求,但是可以知道极值是否在目标索引位置上
- 遍历次数1,...,n-1之和n(n-1)/2
- 时间复杂度O(n2)
- 减少了交换次数,提高了效率,性能略好于冒泡法
插入排序
每一趟都要把待排序数放到有序区中合适的插入位置
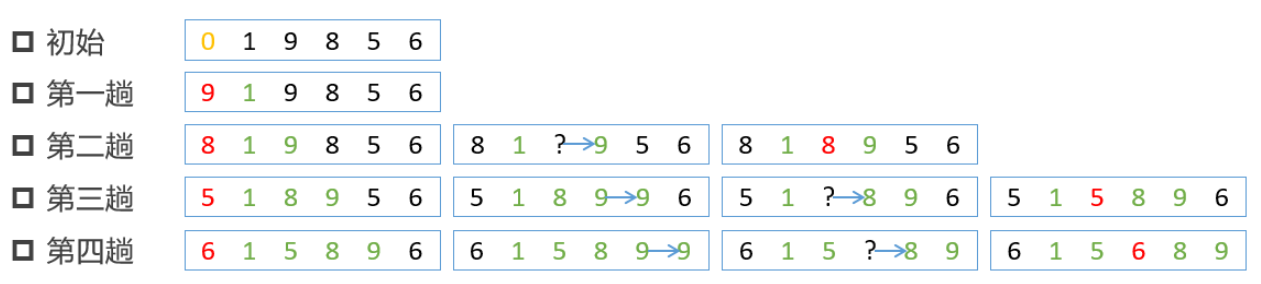
核心算法
- 结果可为升序或降序排列,默认升序排列。以升序为例
- 扩大有序区,减小无序区。图中绿色部分就是增大的有序区,黑色部分就是减小的无序区
- 增加一个哨兵位,图中最左端红色数字,其中放置每一趟待比较数值
- 将哨兵位数值与有序区数值从右到左依次比较,找到哨兵位数值合适的插入点
算法实现
-
增加哨兵位
- 为了方便,采用列表头部索引0位置插入哨兵位
- 每一次从有序区最右端后的下一个数,即无序区最左端的数放到哨兵位
-
比较与挪动
- 从有序区最右端开始,从右至左依次与哨兵比较
- 比较数比哨兵大,则右移一下,换下一个左边的比较数
- 直到找到不大于哨兵的比较数,这是把哨兵插入到这个数右侧的空位即可
实现代码
a = [1, 6, 9, 5, 8]
for i in range(1, len(a)):
c = i
b = a[i]
for j in range(i):
if a[i - j - 1] > b:
a[i - j] = a[i - j - 1]
c = i - j - 1
if c != i:
a[c] = b
print(a)
综合顺序倒序
import time
from random import sample
from functools import wraps
# 计时装饰器,做简单的耗时测试
def timer(fn) :
@wraps(fn)
def wraper(*args, **kwargs) :
now = time.time()
wrap_fn = fn(*args, **kwargs)
end = time.time() - now
print("耗时", end, "秒")
return wrap_fn
return wraper
@timer
def sorted(l, desc = False) :
le = len(l)
# [31, 96, 25, 38, 84, 11, 59, 10, 1, 61]
count = 0
for i in range(1, le) :
index = i
sentry = l[i]
for j in range(i) :
if desc :
count += 1
if sentry > l[i - j - 1] :
l[index], l[i - j - 1] = l[i - j - 1], l[index]
index = i - j - 1
else :
break
else :
count += 1
if sentry < l[i - j - 1] :
l[index], l[i - j - 1] = l[i - j - 1], l[index]
index = i - j - 1
else :
break
return l, count
if __name__ == '__main__' :
# 获取10个100以内的混乱数据
old_list = sample(range(100), k = 10)
print(old_list)
# [96, 31, 25, 38, 84, 11, 59, 10, 1, 61]
print("*" * 30)
list1, count1 = sorted(old_list) # 一万数据顺序3.3780910968780518秒
print("循环次数:", count1)
print(list1)
print("*" * 30)
list2, count2 = sorted(old_list, True) # 一万数据倒序6.526946783065796秒
print("循环次数:", count2)
print(list2)
排序稳定性
- 冒泡排序,相同数据不交换,稳定
- 直接选择排序,相同数据前面的先选择到,排到有序区,不稳定
- 直接插入排序,相同数据不移动,相对位置不变,稳定
总结
- 最好情况,正好是升序排列,比较迭代n-1次
- 最差情况,正好是降序排列,比较迭代1,2,...,n-1即 n(n-1)/2,数据移动非常多
- 使用两层嵌套循环,时间复杂度O(n^2)
- 稳定排序算法
- 如果待排序序列R中两元素相等,即Ri等于Rj,且i < j ,那么排序后这个先后顺序不变,这种排序算法就称为稳定排序
- 适用小规模数据比较
- 优化
- 如果比较操作耗时大的话,可以采用二分查找来提高效率,即二分查找插入排序
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/17052952.html



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义