k8s的污点、容忍度以及亲和性的使用
亲和性
node节点亲和性调度
nodeAffinity
node亲和性是决定pod与节点的关系
$ kubectl explain pods.spec.affinity
KIND: Pod
VERSION: v1
RESOURCE: affinity <Object>
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity <Object>
podAffinity <Object>
podAntiAffinity <Object>
$ kubectl explain pods.spec.affinity.nodeAffinity
KIND: Pod
VERSION: v1
RESOURCE: nodeAffinity <Object>
DESCRIPTION:
Describes node affinity scheduling rules for the pod.
Node affinity is a group of node affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <Object>
- prefered开头的表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性
- require开头的表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性
$ kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <Object>
DESCRIPTION:
FIELDS:
nodeSelectorTerms <[]Object> -required-
Required. A list of node selector terms. The terms are ORed.
$ kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms
KIND: Pod
VERSION: v1
RESOURCE: nodeSelectorTerms <[]Object>
DESCRIPTION:
Required. A list of node selector terms. The terms are ORed.
A null or empty node selector term matches no objects. The requirements of
them are ANDed. The TopologySelectorTerm type implements a subset of the
NodeSelectorTerm.
FIELDS:
matchExpressions <[]Object>
matchFields <[]Object>
#matchExpressions:匹配表达式的
#matchFields: 匹配字段的
$ kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchFields
KIND: Pod
VERSION: v1
RESOURCE: matchFields <[]Object>
DESCRIPTION:
FIELDS:
key <string> -required-
values <[]string>
$ kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions
FIELDS:
key <string> -required-
The label key that the selector applies to.
operator <string> -required-
Represents a key's relationship to a set of values. Valid operators are In,
NotIn, Exists, DoesNotExist. Gt, and Lt.
Possible enum values:
- `"DoesNotExist"`
- `"Exists"`
- `"Gt"`
- `"In"`
- `"Lt"`
- `"NotIn"`
values <[]string>
An array of string values. If the operator is In or NotIn, the values array
must be non-empty. If the operator is Exists or DoesNotExist, the values
array must be empty. If the operator is Gt or Lt, the values array must
have a single element, which will be interpreted as an integer. This array
is replaced during a strategic merge patch.
#key:检查label
#operator:做等值选则还是不等值选则
#values:给定值
硬亲和性
requiredDuringSchedulingIgnoredDuringExecution
- nodeSelectorTerms
- matchExpressions:匹配表达式的
- key 标签的key
- operator 做等值选则还是不等值选则
- values 对应key的值
- matchFields: 匹配字段的
- key 标签的key
- operator 做等值选则还是不等值选则
- values 对应key的值
- matchExpressions:匹配表达式的
例子:
yaml配置文件
cat 2.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: qinghexin
namespace: default
labels:
app: http
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
#匹配标签为abc=a的节点
- key: abc
operator: In
values:
- a
containers:
- name: h1
image: httpd:latest
ports:
- containerPort: 80
查看节点标签
$ kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
centos7906 Ready <none> 25h v1.25.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetesubernetes.io/os=linux
centos7907 Ready <none> 25h v1.25.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetesubernetes.io/os=linux
centos7908 Ready <none> 25h v1.25.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetesubernetes.io/os=linux
node Ready control-plane 25h v1.25.2 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetestes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
没有带有这个标签的节点
应用pod
$ kubectl apply -f 2.yaml
可以看到,pod一直处于pod状态
$ kubectl get pods -o wide -w #加-w是为了能动态显示
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
qinghexin 0/1 Pending 0 0s <none> <none> <none> <none>
查看原因
$ kubectl describe pods qinghexin
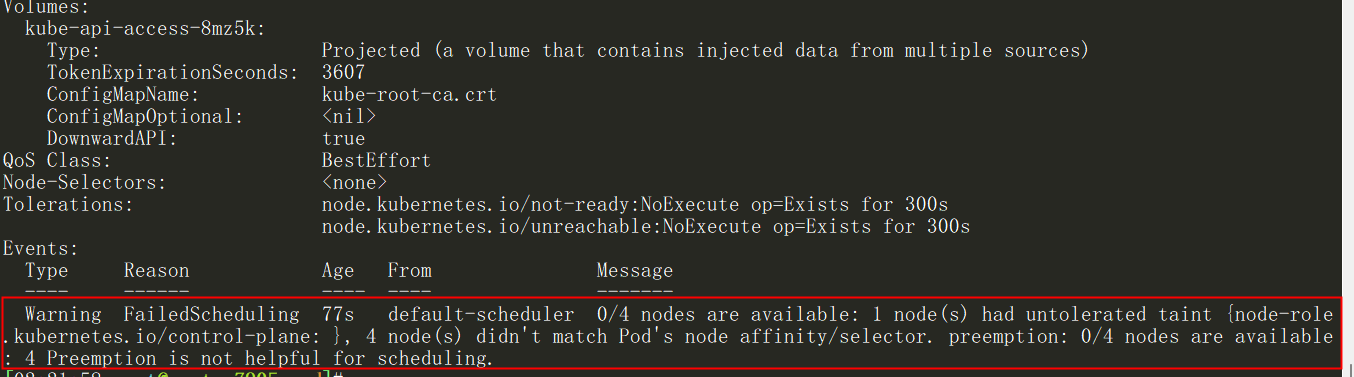
给其中一个节点添加对应的标签
$ kubectl label nodes centos7908 abc=a
node/centos7908 labeled
再次查看pod状态
显示立即完成了部署,对应的节点也是刚刚添加标签的节点

软亲和性
preferredDuringSchedulingIgnoredDuringExecution
- preference
- matchExpressions:匹配表达式的
- key 标签的key
- operator 做等值选则还是不等值选则
- values 对应key的值
- matchFields: 匹配字段的
- key 标签的key
- operator 做等值选则还是不等值选则
- values 对应key的值
- matchExpressions:匹配表达式的
- weight 权重
例子:
yaml配置文件
cat pod-nodeaffinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo-2
namespace: default
labels:
app: myapp
spec:
containers:
- name: myapp
image: docker.io/ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: zone1
operator: In
values:
- foo1
weight: 10
- preference:
matchExpressions:
- key: zone2
operator: In
values:
- foo2
weight: 20
直接应用配置文件
$ kubectl apply -f pod-nodeaffinity-demo-2.yaml
$ kubectl get pods -o wide |grep demo-2
pod-node-affinity-demo-2 1/1 Running 0 xianchaonode1
可以看到,软亲和性是可以运行这个pod的,尽管没有运行这个pod的节点定义的zone1或者zone2标签
Node节点亲和性针对的是pod和node的关系,Pod调度到node节点的时候匹配的条件
权重weight
当两个节点同时具有匹配的标签时,对应weight相对权重越高,pod调度的几率越大
Pod节点亲和性调度
pod亲和性是决定pod与pod关系
pod自身的亲和性调度有两种表示形式
-
podAffinity:pod和pod更倾向腻在一起,把相近的pod结合到相近的位置,如同一区域,同一机架,这样的话pod和pod之间更好通信,比方说有两个机房,这两个机房部署的集群有1000台主机,那么我们希望把nginx和tomcat都部署同一个地方的node节点上,可以提高通信效率; -
podAntiAffinity:pod和pod更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个pod随机选则一个节点,做为评判后续的pod能否到达这个pod所在的节点上的运行方式,这就称为pod亲和性;
亲和性的依据是位置
判断第一个节点位置的依据是标签,只要具有指定的同一标签,就认为是同一位置
$ kubectl explain pods.spec.affinity.podAffinity
KIND: Pod
VERSION: v1
RESOURCE: podAffinity <Object>
DESCRIPTION:
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
Pod affinity is a group of inter pod affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
$ kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
FIELDS:
labelSelector <Object>
namespaces <[]string>
topologyKey <string> -required-
$ kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector
KIND: Pod
VERSION: v1
RESOURCE: labelSelector <Object>
DESCRIPTION:
A label query over a set of resources, in this case pods.
A label selector is a label query over a set of resources. The result of
matchLabels and matchExpressions are ANDed. An empty label selector matches
all objects. A null label selector matches no objects.
FIELDS:
matchExpressions <[]Object>
matchLabels <map[string]string>
requiredDuringSchedulingIgnoredDuringExecution: 硬亲和性
- labelSelector 标签选择器 需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过namespace指定,如果不指定namespaces,那么就是当前创建pod的名称空间
- matchExpressions 匹配表达式
- key
- operator 判断的方式
- values key对应的值
- matchLabels 匹配标签
- matchExpressions 匹配表达式
- namespaceSelector 命名空间选择器
- matchExpressions 匹配表达式
- key
- operator 判断的方式
- values key对应的值
- matchLabels 匹配标签
- matchExpressions 匹配表达式
- namespaces 命名空间
- topologyKey 确定位置的依据 这个是必须字段
preferredDuringSchedulingIgnoredDuringExecution:软亲和性
- podAffinityTerm
- labelSelector 标签选择器
- matchExpressions 匹配表达式
- key
- operator 判断的方式
- values key对应的值
- matchLabels 匹配标签
- matchExpressions 匹配表达式
- namespaceSelector 命名空间选择器
- matchExpressions 匹配表达式
- key
- operator 判断的方式
- values key对应的值
- matchLabels 匹配标签
- matchExpressions 匹配表达式
- namespaces 命名空间
- topologyKey 确定位置的依据
- labelSelector 标签选择器
- weight 权重
软硬亲和力与上面的nodeAffinity一直
亲和性podAffinity
这里以硬亲和力为例
定义两个pod,第一个pod做为基准,第二个pod跟着它走
先运行第一个pod
cat demo-1.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app: myapp
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
部署
$ kubectl apply -f demo-1.yaml
运行第二个pod
cat demo-2.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- myapp
topologyKey: kubernetes.io/hostname
上面表示创建的pod必须与拥有app=myapp标签的pod在一个节点上
部署第二个pod
$ kubectl apply -f demo-2.yaml
#查看pod状态
$ kubectl get pods -o wide
pod-first running centos7906
pod-second running centos7906
上面说明第一个pod调度到哪,第二个pod也调度到哪,这就是pod节点亲和性
反亲和性podAntiAffinity
定义两个pod,第一个pod做为基准,第二个pod跟它调度节点相反
cat demo-1.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
部署第一个pod
$ kubectl apply -f pod-required-anti-affinity-demo-1.yaml
定义第二个pod
cat demo-2.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app1
operator: In
values:
- myapp1
topologyKey: kubernetes.io/hostname
部署第二个pod
$ kubectl apply -f demo-2.yaml
查看pod
$ kubectl get pods -o wide
pod-first running centos7906
pod-second running centos7907
显示两个pod不在一个node节点上,这就是pod节点反亲和性
换一个topologykey
$ kubectl label nodes centos7906 zone=foo
$ kubectl label nodes centos7907 zone=foo
定义第一个pod
cat demo-1.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app3: myapp3
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
部署第一个pod
$ kubectl apply -f demo-1.yaml
定义第二个pod
cat demo-2.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: ["sh","-c","sleep 3600"]
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app3
operator: In
values:
- myapp3
topologyKey: zone
部署第二个pod
$ kubectl apply -f demo-2.yaml
查看pod
$ kubectl get pods -o wide
pod-first running centos7907
pod-second pending <none>
第二个pod是pending,因为两个节点是同一个位置,现在没有不是同一个位置的了,而且我们要求反亲和性,所以就会处于pending状态,如果在反亲和性这个位置把required改成preferred,那么也会运行。
podAffinity: pod节点亲和性,pod倾向于哪个pod
podAntiAffinity: pod反亲和性
nodeAffinity: node节点亲和性,pod倾向于哪个node
污点、容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的pod就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些pod;
taints是键值数据,用在node上,定义污点;tolerations是键值数据,用在pod上,定义容忍度,能容忍哪些污点
pod亲和性是pod属性;
污点是node的属性,污点定义在k8s集群的节点上的一个字段
effect则用于定义对Pod对象的排斥等级,它主要包含以下三种类型
NoSchedule
不能容忍此污点的新Pod对象不可调度至当前节点,属于强制型约束关系,节点上现存的Pod对象不受影响。
PreferNoSchedule
NoSchedule的柔性约束版本,即不能容忍此污点的新Pod对象尽量不要调度至当前节点,不过无其他节点可供调度时也允许接受相应的Pod对象。节点上现存的Pod对象不受影响。
NoExecute
不能容忍此污点的新Pod对象不可调度至当前节点,属于强制型约束关系,而且节点上现存的Pod对象因节点污点变动或Pod容忍度变动而不再满足匹配规则时,Pod对象将被驱逐。
在
Pod对象上定义容忍度时,它支持两种操作符:一种是等值比较
Equal,表示容忍度与污点必须在key、value和effect三者之上完全匹配;另一种是存在性判断
Exists,表示二者的key和effect必须完全匹配,而容忍度中的value字段要使用空值。
一个节点可以配置使用多个污点,一个
Pod对象也可以有多个容忍度,不过二者在进行匹配检查时应遵循如下逻辑。
- 首先处理每个有着与之匹配的容忍度的污点
- 不能匹配到的污点上,如果存在一个污点使用了
NoSchedule效用标识,则拒绝调度Pod对象至此节点- 不能匹配到的污点上,若没有任何一个使用了
NoSchedule效用标识,但至少有一个使用了PreferNoScheduler,则应尽量避免将Pod对象调度至此节点- 如果至少有一个不匹配的污点使用了
NoExecute效用标识,则节点将立即驱逐Pod对象,或者不予调度至给定节点;另外,即便容忍度可以匹配到使用了NoExecute标识的污点,若在定义容忍度时还同时使用tolerationSeconds属性定义了容忍时限,则超出时限后其也将被节点驱逐。使用
kubeadm部署的Kubernetes集群,其Master节点将自动添加污点信息以阻止不能容忍此污点的Pod对象调度至此节点,因此,用户手动创建的未特意添加容忍此污点容忍度的Pod对象将不会被调度至此节点
1、当不指定 key 值时,表示容忍污点的所有key:
tolerations: - operator: “Exists”2、当不指定 effect 值时,表示容忍所有的污点作用
tolerations: - key: “key” operator: “Exists”
查看node的污点定义
$ kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required-
key <string> -required-
timeAdded <string>
value <string>
$ kubectl describe nodes node
#查看master这个节点是否有污点,显示如下:
Taints: node-role.kubernetes.io/control-plane:NoSchedule
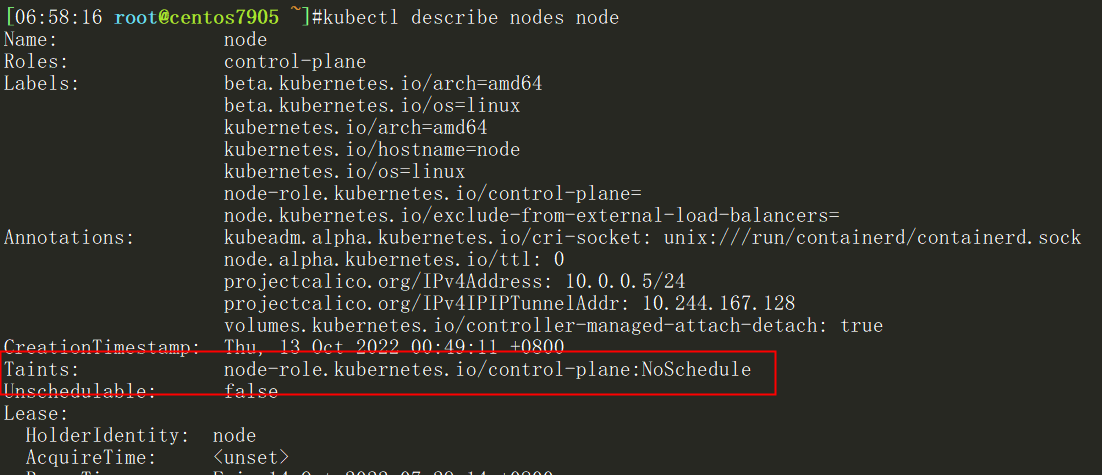
上面可以看到master这个节点的污点是Noschedule
所以创建的pod都不会调度到master上,因为我们创建的pod没有容忍度。
查看一个master节点上的pod的容忍度
$ kubectl describe pods kube-apiserver-node -n kube-system
........
Tolerations: :NoExecute op=Exists
........
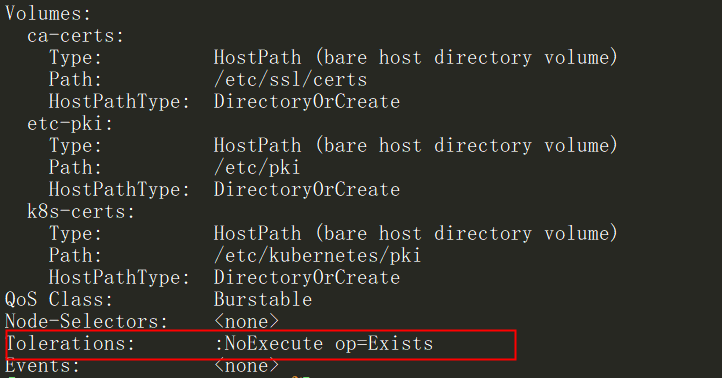
可以看到这个pod的容忍度是NoExecute,是最大程度的容忍度,而master的污点只是NoSchedule,所以是可以调度到master节点上的。
管理节点污点
查看帮助
$ kubectl taint --help
Update the taints on one or more nodes.
* A taint consists of a key, value, and effect. As an argument here, it is expressed as key=value:effect.
* The key must begin with a letter or number, and may contain letters, numbers, hyphens, dots, and underscores, up to
253 characters.
* Optionally, the key can begin with a DNS subdomain prefix and a single '/', like example.com/my-app.
* The value is optional. If given, it must begin with a letter or number, and may contain letters, numbers, hyphens,
dots, and underscores, up to 63 characters.
* The effect must be NoSchedule, PreferNoSchedule or NoExecute.
* Currently taint can only apply to node.
#会有一些案例
Examples:
# Update node 'foo' with a taint with key 'dedicated' and value 'special-user' and effect 'NoSchedule'
# If a taint with that key and effect already exists, its value is replaced as specified
kubectl taint nodes foo dedicated=special-user:NoSchedule
#添加污点
# Remove from node 'foo' the taint with key 'dedicated' and effect 'NoSchedule' if one exists
kubectl taint nodes foo dedicated:NoSchedule-
#删除节点上的dedicated污点
# Remove from node 'foo' all the taints with key 'dedicated'
kubectl taint nodes foo dedicated-
#删除节点的污点
# Add a taint with key 'dedicated' on nodes having label mylabel=X
kubectl taint node -l myLabel=X dedicated=foo:PreferNoSchedule
#在标签为mylabel=X的节点上添加污点dedicated
# Add to node 'foo' a taint with key 'bar' and no value
kubectl taint nodes foo bar:NoSchedule
#添加没有value的污点
例1:把centos7906当成是生产环境专用的,其他node是测试的
$ kubectl taint node xianchaonode2 node-type=production:NoSchedule
给centos7906打污点,pod如果不能容忍就不会调度过来
定义一个pod
cat pod-taint.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
部署
$ kubectl apply -f pod-taint.yaml
$ kubectl get pods -o wide
taint-pod running centos7907
可以看到都被调度到centos7907上了,因为centos7906这个节点打了污点,而我们在创建pod的时候没有容忍度,所以centos7906上不会有pod调度上去的
例2:给centos7907也打上污点
$ kubectl taint node centos7907 node-type=dev:NoExecute
$ kubectl get pods -o wide
taint-pod termaitering
上面可以看到已经存在的pod节点都被撵走了
定义一个带有容忍度的pod
cat pod-demo-1.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
tolerations:
- key: node-type
operator: Equal
value: production
effect: NoExecute
tolerationSeconds: 3600 #如果无法容忍,会在3600秒之后被驱逐,这个只能在NoExecute的强度下配置
部署
$ kubectl apply -f pod-demo-1.yaml
$ kubectl get pods
myapp-deploy 1/1 Pending 0 11s centos7906
还是显示pending,因为我们使用的是equal(等值匹配),所以key和value,effect必须和node节点定义的污点完全匹配才可以。
把上面配置effect: "NoExecute"变成effect: "NoSchedule"成;
然后把tolerationSeconds: 3600这行去掉
再部署
$ kubectl delete -f pod-demo-1.yaml
$ kubectl apply -f pod-demo-1.yaml
$ kubectl get pods
myapp-deploy 1/1 running 0 11s centos7906
上面就可以调度到centos7906上了,因为在pod中定义的容忍度能容忍node节点上的污点
例3:再次修改
修改如下部分:
tolerations:
- key: node-type
operator: Exists
value:
effect: NoSchedule
只要对应的键是存在的,exists,其值被自动定义成通配符
$ kubectl delete -f pod-demo-1.yaml
$ kubectl apply -f pod-demo-1.yaml
$ kubectl get pods
# 发现还是调度到centos7906上
myapp-deploy 1/1 running 0 11s centos7906
再次修改:
tolerations:
- key: node-type
operator: Exists
value:
effect:
有一个node-type的键,不管值是什么,不管是什么效果,都能容忍
$ kubectl delete -f pod-demo-1.yaml
$ kubectl apply -f pod-demo-1.yaml
$ kubectl get pods -o wide 显示如下:
myapp-deploy running centos7907
可以看到centos7906和centos7907节点上都有可能有pod被调度
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/16983665.html
