jieba分词库
简介
gojieba 是一个高性能的中文分词库,非常适合做文本分析,文本搜索等业务;它的计算分词过程,词典载入过程都非常快;gojieba 底层代码都由 C++ 封装而来,比原生 Go 拥有更高的性能,但在之 gojieba 上二次扩展开发不是很便利,满足需求的情况推荐使用。
官网
https://github.com/yanyiwu/gojieba
分词模式
gojieba 支持多种分词方式:
- 全模式:把文本中所有可能的词语都扫描出来,存在冗余词汇,存在歧义
- 精确模式:把文本精准的切分开,不存在冗余词语,适合文本分析
- 搜索引擎模式:在精准模式基础上,对长词语再次切分,提高召回率,适合用于搜索引擎分词
- 最大概率模式:把文本中的句子按概率最大的结果切分
- HMM 新词发现模式:对于未记录词,采用了基于汉字成词能力的 HMM 模型
安装
$ go get github.com/yanyiwu/gojieba
问题
1、GCC相关
注意:一定要保证本地环境有GCC编译器,否则会报如下的错误
cgo: C compiler "gcc" not found: exec: "gcc": executable file not found in %PATH%
解决办法
安装GCC
下载
https://sourceforge.net/projects/mingw-w64/files/
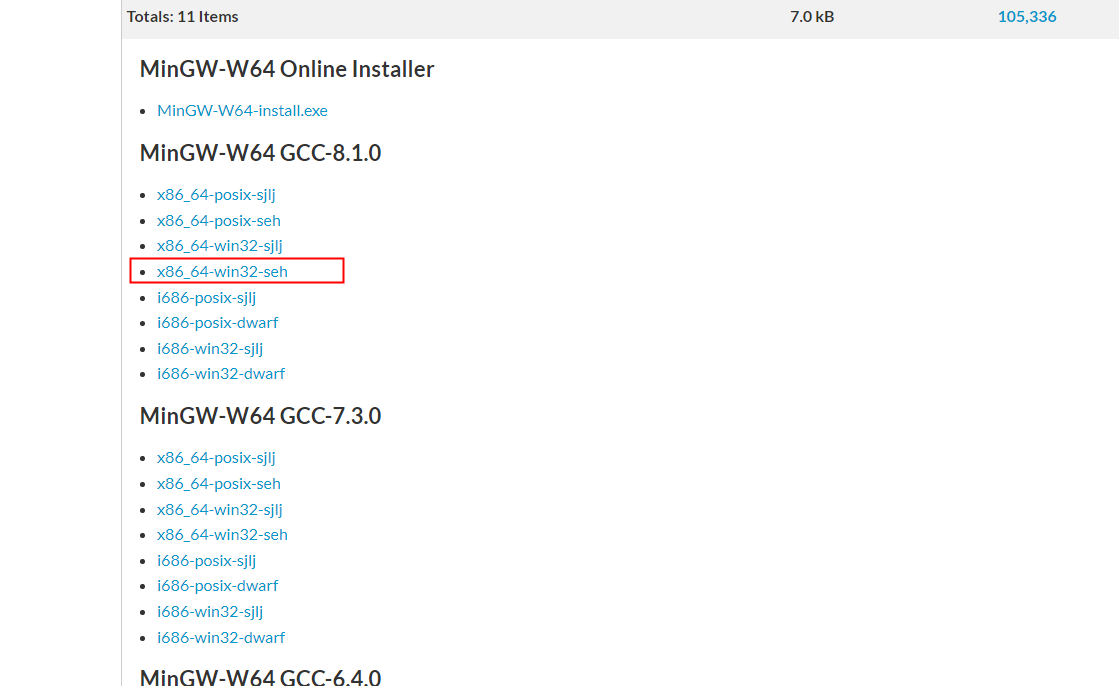
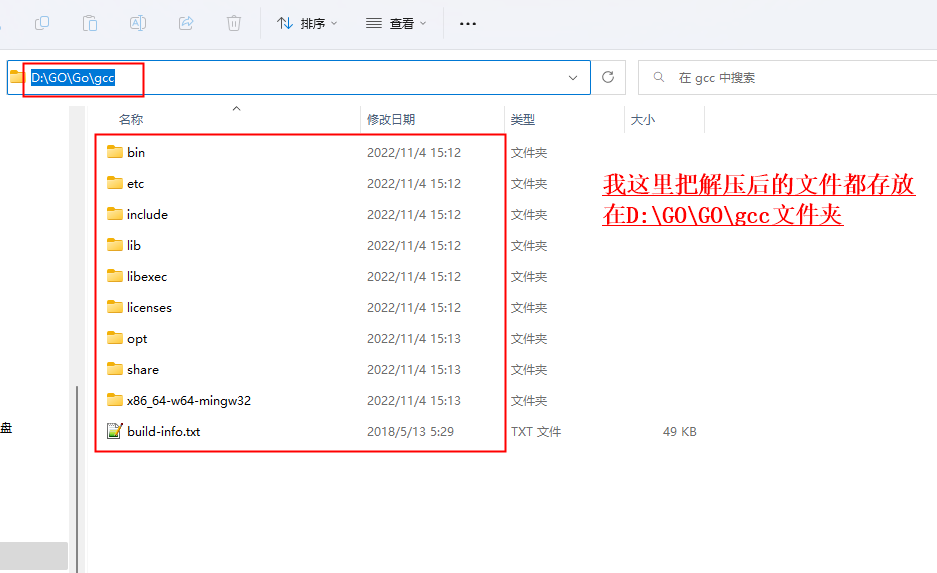
下载好后,解压到文件夹,添加环境变量
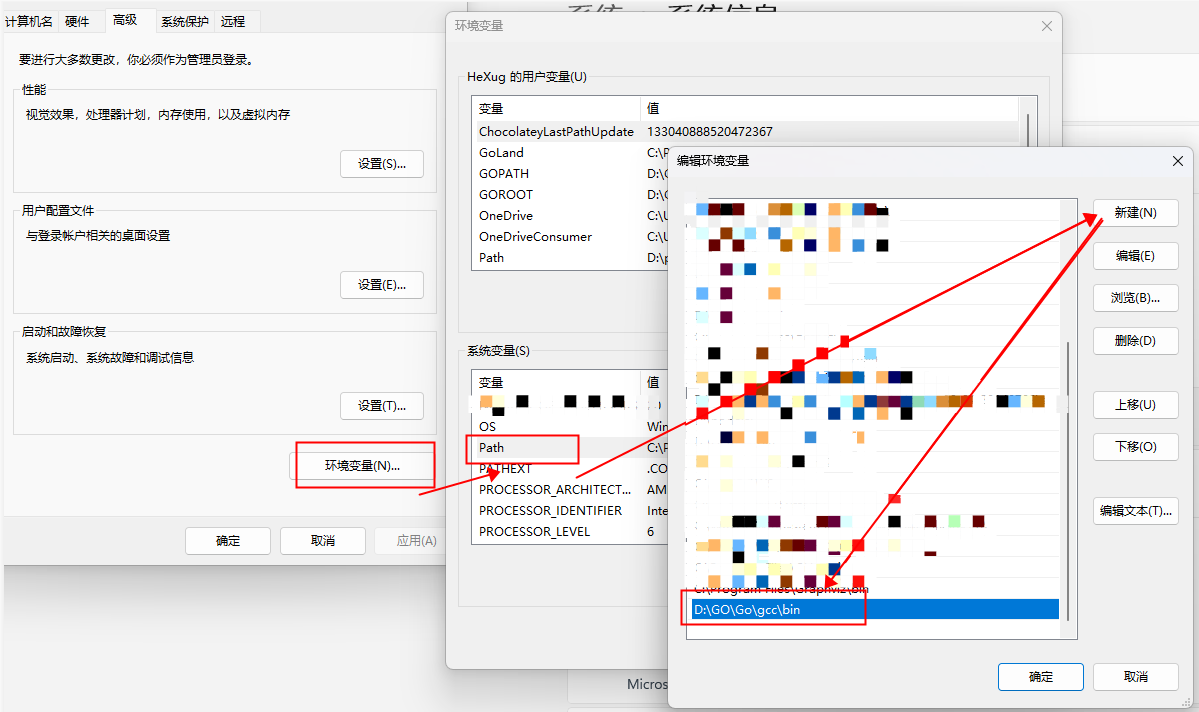
将D:\GO\Go\gcc\bin添加环境变量
使用
新建分词器
x := gojieba.NewJieba()//新建分词器
defer x.Free() //释放分词器
全模式分词
使用func (x *Jieba) CutAll(s string) []string函数
返回的是分词过后的字符串切片
注意:单词会分的很细,英文单词会分割成单个的字母
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
var words []string
use_hmm := true
x := gojieba.NewJieba()
defer x.Free()
s = "Gojieba 使用示例"
words = x.CutAll(s)
fmt.Println(s)
fmt.Println("全模式:", strings.Join(words, "/")) //全模式: G/o/j/i/e/b/a/ /使用/示例
}
精准模式
使用func (x *Jieba) Cut(s string, hmm bool) []string函数
返回切割后的字符串切片
这里会需要设置一个标记参数
hmm参数如果为true,则不会把单词细分,为false则会细分,例如英文单词会被分成单个的字母
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
var words []string
use_hmm := true
x := gojieba.NewJieba()
defer x.Free()
s = "Gojieba 使用示例"
words = x.Cut(s, use_hmm)
fmt.Println(s)
fmt.Println("精确模式:", strings.Join(words, "/")) //精确模式: Gojieba/ /使用/示例
words = x.Cut(s, !use_hmm)
fmt.Println(s)
fmt.Println("精确模式:", strings.Join(words, "/")) //精确模式: G/o/j/i/e/b/a/ /使用/示例
}
设置整词
使用func (x *Jieba) AddWord(s string)函数给字典添加新词
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
var words []string
use_hmm := true
x := gojieba.NewJieba()
defer x.Free()
s = "比特币"
words = x.Cut(s, use_hmm)
fmt.Println(s)
fmt.Println("精确模式:", strings.Join(words, "/")) //精确模式: 比特/币
x.AddWord("比特币")//添加整词
s = "比特币"
words = x.Cut(s, use_hmm)
fmt.Println(s)
fmt.Println("添加词典后,精确模式:", strings.Join(words, "/")) //添加词典后,精确模式: 比特币
s = "他来到了网易杭研大厦"
words = x.Cut(s, use_hmm)
fmt.Println(s)
fmt.Println("新词识别:", strings.Join(words, "/")) //新词识别: 他/来到/了/网易/杭研/大厦
}
搜索引擎模式
使用func (x *Jieba) CutForSearch(s string, hmm bool) []string函数
在精准模式基础上,对长词语再次切分,提高召回率,适合用于搜索引擎分词
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
var words []string
use_hmm := true
x := gojieba.NewJieba()
defer x.Free()
s = "小明硕士毕业于中国科学院计算所,后在日本京都大学深造"
words = x.CutForSearch(s, use_hmm)
fmt.Println(s)
fmt.Println("搜索引擎模式:", strings.Join(words, "/"))
//搜索引擎模式: 小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
}
通过指定分词模式的方式分词
使用函数func (x *Jieba) Tokenize(s string, mode TokenizeMode, hmm bool) []Word
分两种模式
- SearchMode 浏览器模式
- DefaultMode 默认模式
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
use_hmm := true
x := gojieba.NewJieba()
defer x.Free()
s = "长江大桥"
wordinfos := x.Tokenize(s, gojieba.SearchMode, !use_hmm)
fmt.Println(s)
fmt.Println("Tokenize:(搜索引擎模式)", wordinfos) //Tokenize:(搜索引擎模式) [{长江 0 6} {大桥 6 12} {长江大桥 0 12}]
wordinfos = x.Tokenize(s, gojieba.DefaultMode, !use_hmm)
fmt.Println(s)
fmt.Println("Tokenize:(默认模式)", wordinfos) //Tokenize:(默认模式) [{长江大桥 0 12}]
}
其他不常用模式
package main
import (
"fmt"
"strings"
gojieba "github.com/yanyiwu/gojieba"
)
func main() {
var s string
var words []string
x := gojieba.NewJieba()
defer x.Free()
s = "长春市长春药店"
words = x.Tag(s)
fmt.Println(s)
fmt.Println("词性标注:", strings.Join(words, ",")) //词性标注: 长春市/ns,长春/ns,药店/n
s = "区块链"
words = x.Tag(s)
fmt.Println(s)
fmt.Println("词性标注:", strings.Join(words, ",")) //词性标注: 区块链/nz
//选择最大概率的次
keywords := x.ExtractWithWeight(s, 5)
fmt.Println("Extract:", keywords) //Extract: [{长江大桥 11.1926274509}]
}
本文来自博客园,作者:厚礼蝎,转载请注明原文链接:https://www.cnblogs.com/guangdelw/p/16891757.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号