Robot Framework--05 案例设计之流程与数据分离
转自:http://blog.csdn.net/tulituqi/article/details/7651049
这一讲主要说一下案例设计了。还记得我们前面做的case么?先打开浏览器访问百度,输入关键字,点击搜索。
我们再加上个检查点,检查一下标题是否包含我的关键字,然后关闭浏览器。就是下面这样了。

这样就可以算是一个比较完整的案例了,包含完整的流程和检查点,那么这时候如果我要增加一个案例,搜索另外的内容怎么办呢?
在原来的case上修改肯定是不合适的,毕竟那个案例可能还是需要保留的。
最简单的办法,把这个case复制一个,修改搜索内容。那么我们复制出一个case2吧

然后我们把2个一起运行一下。

都运行成功了。但是如果我们这样的方法虽然简单,但是并不合理,因为如果我要再加5个、10个、100个呢?
都是同样的流程,只是搜索内容和检查点不同,为什么不能把流程抽离出来与数据分开呢?也就是案例分层设计。
这时候就用到了之前讲过的User Keyword,如果你的案例已经写好了,那么可以用下面这个方法,如果是新建的时候就准备好分层了,那么直接在资源里新建userkeyword就可以了。
=======分层方法=======
1、选中case中的所有脚本,点击右键,选择Extract Keyword

输入Keyword的name,Arguments先不管。

点击OK,就会看到生成了一个userkeyword了。

而我们再看case的内容就只有这个关键字了。

2、新建一个Resource文件,把UserKeyword移动过去(或者移动到已有的Resource文件里)
这样做的目的是为了更清晰,在测试套件中一般不放置UserKeyword,前面第2讲的时候我们就说过了,首要建议UserKeyword放在Resource里。
我这里新建一个Resource,叫TestFlow.txt,然后把这个搜索测试移动过去,就成了这样。

我这是新版的RIDE0.46.1,貌似又新增了一些特性,比如图片里我新增的Resource文件TestFlow.txt是灰色的,因为他没有被加载过。前面我们介绍了怎么把Resource加载到TestSuite上,现在也照着做一遍。加载后就是和res1.txt一样了,就不放图片了。
3、接下来我们针对这个测试流程进行分离,因为这个案例流程比较简单,实际上就只有搜索内容这一个值是变化的,因此我们把他改成一个变量,同时把这个UserKeyword的参数加上这个变量。

忽然发现这些关键字都是黑色的了,别急,这是因为我们在TestFlow.txt上没有加载Library,参考前面添加Library的地方把S2L(Selenium2Library缩写)加进去就可以了。实际上不加也不影响,只要在运行的地方有加载过Library,就可以正常执行。只是这里显示看的不太舒服而已。为了证明可以正常执行,我这就先不加S2L了。
4、再回头看看case的内容

在搜索测试的后面一个格子变红色了,这是提醒我们这个UserKeyword有一个参数必须要填写,我们写上case要测试搜索的内容。

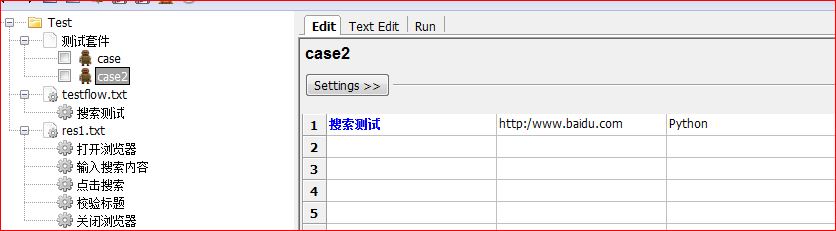
5、接着我们再把case2的内容都清掉,重新写一个和case一样的脚本,来调用搜索测试这个UserKeyword

6、再运行一次, 结果和之前相同,都是pass了。大家可以自己运行一下看看。
到现在我们完成了一个简单的分层,把搜索测试这个流程剥离成一个关键字,然后在不同的case调用这个关键字,然后传递不同的参数,用以进行不同数据在同一个流程下的测试。
这样就不用担心再新增10个或100个案例了,因为这个案例比较简单,通过复制也可以做出10个或100个案例,但是最大的区别在于,如果我的流程中间需要做一点小的调整和优化,对于流程和数据分离的案例来说,我这样维护一下搜索测试这个UserKeyword就行了;对于复制的案例,那你就要辛苦了,你有多少个案例就改多少吧。
其实这个道理引申出来,我们做自动化测试也是一样,选择不同的方法或者工具都可以实现最终的目标,但是我们需要考虑的不是把案例做起来,因为这个比较容易实现。对于自动化案例来说,最大的难度不是在于怎么做案例,而是怎么维护案例。因为随着需求的更新,系统的流程或者页面会发生很多的变化,这时候的维护成本的高低才是我们首要考虑的,如果自动化案例建立起来之后,没有后续维护的投入,最终经过若干个版本,这些自动化案例基本就是废弃的了。
首先我们看一下testflow这个resource里的内容。

可以看到在这个搜索测试的关键字中,我们堆积了很多最底层的代码,这样是不够灵活的。
对于我们分层来说,还是要把一些底层的代码级关键字继续拆分出来。
先做2个,后面的类似。这时候我们看res1的资源下面有一个打开浏览器的,这是我之前添加了,目的就是留到这里来分层的。
我们把open browser这一行挪过去。

记得给res1加载Selenium2Library
然后在res1下面新增一个输入搜索内容,并把第二行input text挪过来。

剩下的第3行、第45行、第6行,也分别增加3个关键字。效果如图:
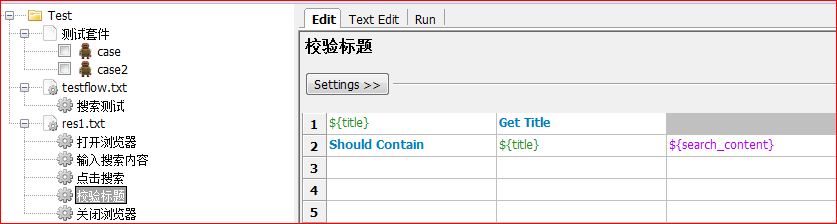
接着我们把对应的搜索测试中的代码都换成相应的关键字。

这样还不行,因为有一些关键字是有参数的,我们最好把他们继续完善相应的参数。
打开浏览器:
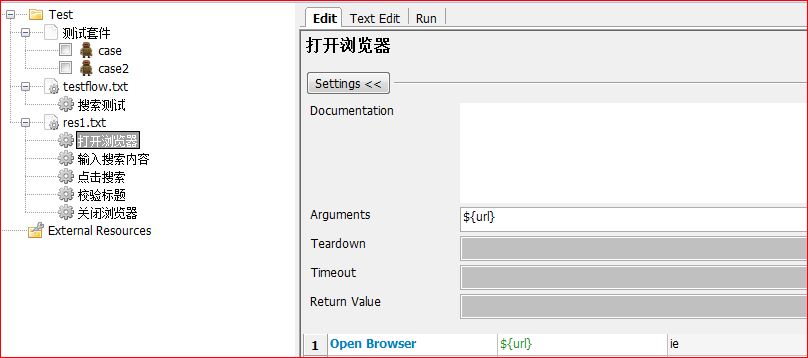
输入搜索内容:

点击搜索和关闭浏览器不需要加参数了。
校验标题:

搜索测试里面的内容我们也顺势一起修改一下,加个url的参数。

因为修改了搜索测试的arguments,所以必须把case的也进行修改。所以大家以后注意要提前设计好关键字的arguments,否则后面修改的时候很容易遗漏。
至此,我们这个案例就已经完成分层了,因为案例比较简单,所以只分了3层,分别是案例层,流程层,元素层。他们的调用关系也是逐层深入的。

一般情况下,做一个系统或项目,大概分4层就够了,如果系统比较复杂可以考虑分5层。
看一下分4层的图(手头没有例子,先借用一下吴博PPT里的图):

分别是案例层、流程层、流程构件(页面层)、元素层,加载资源也是从上到下的。
案例层中放的是流程层的关键字,流程层放的是页面层的关键字,页面层放的是元素层的关键字。
我们自己的项目分5层的:
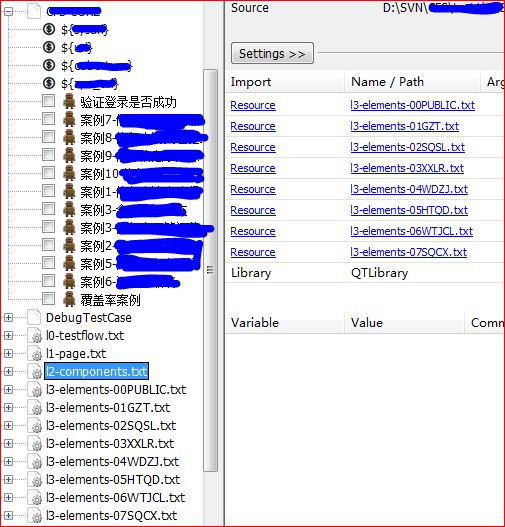
和4层的比起来,我这里多了一个components组件层。因为我们的有很多页面内容比较多,我把每个页面分成了几个区域,一个区域就是一个components。
所以我这边的加载顺序是case层加载l0-testflow,testflow加载l1-page,page加载l2-components,components加载l3-elements层。一个elements文件就是一个页面内所有的元素,由于元素较多,所以这样来组织,然后在组件层加载所有页面的元素,然后拼出相应的组件。
=============总结一下=============
这样做的好处不单是为了以后维护方便,也使得案例的架构层级清晰。越是靠近上层的部分,脚本越贴近自然语言,或者说很像我们的测试案例;越靠近下层的部分,越是接近页面元素的代码级部分。这样以后如果发生维护的时候,根据需要维护的内容,只需要在很少的地方进行调整即可。比如一个元素的id变了,那我只要在elements里面更新就行了。比如测试的流程调整了,以前是ABC的页面顺序,现在是ACB的页面顺序,那么只要在testflow层进行调整即可。
那么回到我们的标题,流程与数据分离,实际上目前我们的流程都集中在testflow以及下面的部分,而数据一般都是在案例层去给流程层传递,这就是我们的流程与数据分离了。当然,我们还可以再进一步的分离,把数据放到外面,脱离我们的案例,在运行的时候才传递进行,也是可以实现的。后面我会做个简单的例子给大家看。
在前一篇的基础上,我们继续做一下进一步的数据分离。大体上有三种方式,第一种适合和Jenkins集成用的,第二种适合有大量数据的,第三种么只有思路,暂时还未实现,如有朋友能实现的话也欢迎分享一下。
一、运行时参数(-v 参数)
先看一下case的脚本:

然后我们改造一下,把url和搜索文字都改成变量。

然后我们选择RUN页面,在Arguments栏输入参数 -v testURL:http://www.baidu.com/ -v searchText:齐涛-老道长,接着运行一下,这个是木有问题的。

作用:这种方式的作用在和Jenkins整合做持续集成的时候非常方便,可以在JOB运行的时候根据传入的参数决定在哪个环境运行。
二、参数文件(-V)
这个和上一个的区别就是一个使用大V,一个使用小v,并且大V的是使用文件的。使用文件的好处就是这里你可以写很多的
我们先增加一下var.py的文件(pyc是运行后自动编译生成的,不用管),内容如图。这里要注意的就是中文字符串前面要加u。还有__all__要列出所有的变量。
另外增加了2个变量,一个是LIST型变量,另一个是使用了一个随机数方法,每次都会生成一个1-10的随机数。接着再改造一下我们的案例,增加2个log,把那2个变量的值打印一下。

接着我们要加载这个var.py文件,这里有几种方式,推荐第一个。
1、在测试套件上使用Add Variables增加var.py进来,因为我的var.py文件就放在案例相同的目录,所以不用写路径了。

2、和刚才的小v在一个地方RUN的这里写,不过要写完整的路径。感觉不如第一种方便,如果不写路径会报错。或许我没找到如何缩短路径的办法。

3、在脚本中使用import variables,这里可以用${CURDIR}代表当前路径,这样比2好一些,不用写那么长的路径。

最后运行一下,可以看到test log里的值已经是使用了var.py文件里的变量值。

三、使用外部excel文件
对于这种方案目前我这里还只是构思,没有代码实现出来,所以只说一下思路。
就是类似于QTP的加载excel差不多,但是我们这里需要使用Python脚本来写excel的读写方法,貌似有个xlrd的库,但是好像还要自己做拓展开发,一直没啥时间去写这个公共方法,加上俺Python经验有限,之前写自己的测试库都是边查帮助边写的,缺乏系统化的学习 。如果有朋友有实现的方法,可以提供给我参考一下哈。
。如果有朋友有实现的方法,可以提供给我参考一下哈。
实现了excel读写之后,就可以在测试过程中使用外部的excel文件读取数据或写入数据了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号