

Mysql 验证枚举上也可以建立索引
mysql 8.0 十万数据 9.9w success 1000条 fail、wait
表结构
CREATE TABLE `orders` (
`order_id` int NOT NULL AUTO_INCREMENT,
`status` varchar(20) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`order_id`),
KEY `status_index` (`status`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
插入100w 26个字母
DELIMITER //
CREATE PROCEDURE insert_letters()
BEGIN
DECLARE counter INT DEFAULT 0;
DECLARE letter CHAR(1);
SET letter = 'A';
WHILE ASCII(letter) <= ASCII('Z') DO
SET counter = 0;
WHILE counter < 3800 DO
INSERT INTO orders (status) VALUES (letter);
SET counter = counter + 1;
END WHILE;
SET letter = CHAR(ASCII(letter) + 1);
END WHILE;
END//
DELIMITER ;
CALL insert_letters();
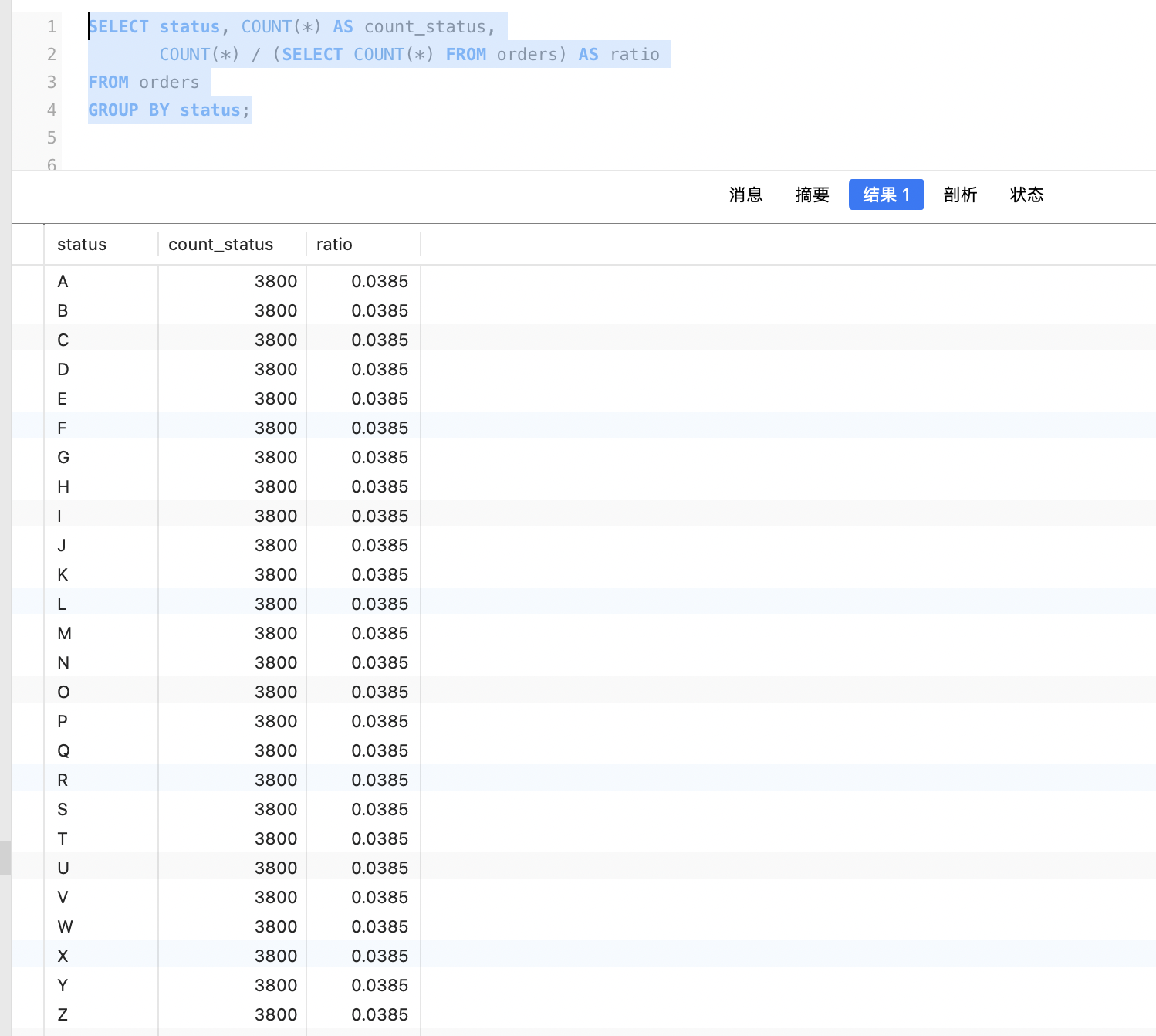
查询数据占比
SELECT status, COUNT(*) AS count_status,
COUNT(*) / (SELECT COUNT(*) FROM orders) AS ratio
FROM orders
GROUP BY status;
使用explain分析

- 明显看到 扫描了3800行 ,检索比例10% 也就是380行
经过验证其实status 加索引
- 例如订单表 1000w 数据大多都是sucess 只有少数是 fail 、wait等值情况 ,基数很低,可能对于某地值很有效
- 1000w 数据中 枚举值为 27个字母 基数很高,索引的选择性就很低
- 需要排序的场景
- 索引维护度很高的 就放弃索引 查看 rows 和filtered 字段 filtered值越高表示选择性越低 一般低于5% 维护成本很大
本文来自博客园,作者:vx_guanchaoguo0,转载请注明原文链接:https://www.cnblogs.com/guanchaoguo/p/18265061
