
利用 python 抽取pdf 中表格到 excel
首先推荐 camelot
pdf_file_input = "TTAF086-2021.pdf"
tables = camelot.read_pdf(pdf_file_input, pages='11', flavor='stream')
df = tables[0].df
df.to_excel("TTAF086-2021.xlsx",index=False)
pdf 表格
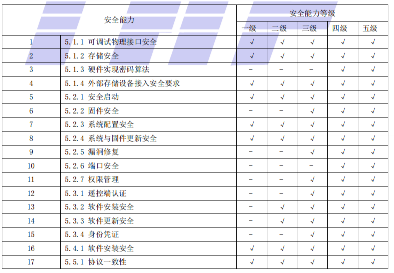
效果如下
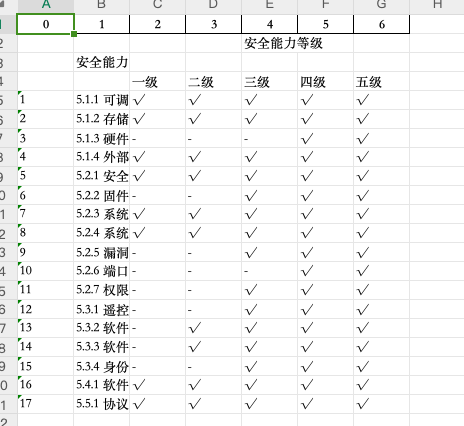
其次是使用 pdfplumber
pdf_file_input = "TTAF086-2021.pdf"
tables = pdfplumber.open(pdf_file_input).pages[10].extract_table()
df = pd.DataFrame(tables)
df.to_excel("TTAF086-2021.xlsx",index=False)
效果如下
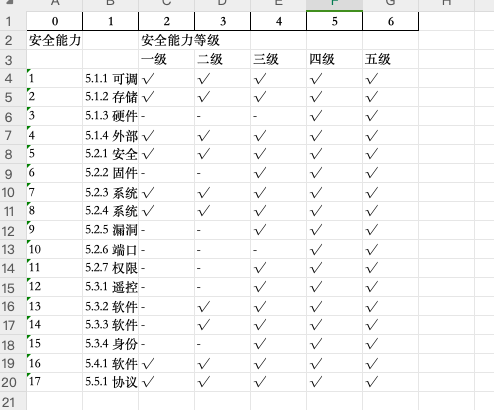
给 excel 添加边框 需要优化
writer = pd.ExcelWriter("output.xlsx", engine="xlsxwriter")
for table in tables:
df = table.df
df.to_excel(writer, sheet_name=f"Sheet1", index=False)
workbook = writer.book
worksheet = writer.sheets['Sheet1']
header_format = workbook.add_format({'border': 1})
for col_num, value in enumerate(df.columns.values):
for index, row in df.iterrows():
worksheet.write(index + 1, col_num, row[col_num], header_format)
writer.close()
本文来自博客园,作者:vx_guanchaoguo0,转载请注明原文链接:https://www.cnblogs.com/guanchaoguo/p/17772980.html

