
Hadoop入门学习整理(二)
2020-04-15
在上一篇文章中介绍了Linux虚拟机的安装,Hadoop的安装和配置,这里接着上一篇的内容,讲Hadoop的简要介绍和简单使用, 以及HBase的安装和配置。
1、首先要了解Hadoop的目录:
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
2、了解Hadoop的运行模式:
Hadoop包括3种安装模式
(1)单机模式。只在一台机器上运行,存储采用本地文件系统,没有采用分布式文件系统HDFS
(2)伪分布式模式。存储采用分布式文件系统HDFS,但是,HDFS的名称节点和数据节点都在同一台机器上
(3)分布式模式。存储采用分布式文件系统HDFS,而且,HDFS的名称节点和数据节点位于不同机器上。
在Linux虚拟机中安装完Hadoop后默认为单机模式,无需进行其它配置即可运行。
我个人在目前的学习当中,采用伪分布式模式。
若想让 Hadoop在伪分布式模式下顺利运行,则需要配置相关文件。
伪分布式模式:
Hadoop可以在单个节点(一台机器)上以伪分布式的方式运行,同一个节点既作为名称节点( Name Node),
也作为数据节点( Data Node),读取的是分布式文件系统HDFS中的文件。
3、伪分布式模式的配置修改
Hadoop的配置文件位于hadoop/etc/ hadoop/中,进行伪分布式模式配置时,需要修改2个配置文件,即 core-site.xml和 hdfs-site.xml。
可以使用vim编辑器打开 core-site.xml文件。
(a)配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[guan@ hadoop101 ~]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
修改JAVA_HOME 路径:
export JAVA_HOME=/opt/module/jdk1.8.0_144
(b)配置:core-site.xml
|
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101:9000</value> </property>
<!-- 指定Hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.7.2/data/tmp</value> </property> |
(c)配置:hdfs-site.xml
|
<!-- 指定HDFS副本的数量 --> <property> <name>dfs.replication</name> <value>1</value> </property> |
修改配置文件以后,要执行名称节点的格式化,命令如下:
[guan@hadoop101 hadoop-2.7.2]$ bin/hdfs namenode -format
【注】第一次启动时格式化,以后就不要总格式化。
我在格式化的过程中出现了以下错误:

原因是没有配置主机名称映射。解决办法:进入/etc/hosts,然后:

再次格式化,成功。
如果要格式化,那么需要在格式化之前:
(1、查看NameNode和DataNode进程是否关掉。(必须关掉)
关闭命令: sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
(2、将/data和/logs删掉
(3、格式化NameNode
4、启动伪分布式集群
(a)启动NameNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
(b)启动DataNode
[atguigu@hadoop101 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
(c)查看是否启动成功
[atguigu@hadoop101 hadoop-2.7.2]$ jps
13586 NameNode
13668 DataNode
13786 Jps
注意:jps是JDK中的命令,不是Linux命令。不安装JDK不能使用jps
启动集群也可以群起: sbin/start-dfs.sh
5.使用Web界面查看HDFS信息
Hadoop成功启动后,可以在 Linux系统中(不是 Windows系统)打开一个浏览器,
在地址栏输入地址http://localhost:50070 就可以查看名称节点和数据节点信息,还可以在线查看HDFS中的文件。
6、遇到bug时,可以查看产生的日志。具体方法如下:

7、关闭Hadoop
执行命令 /sbin/stop-dfs.sh
接下来是HBase的安装和使用。
( 具体参考 厦门大学大数据实验室 https://dblab.xmu.edu.cn/blog/install-hbase/)
其实HBase的安装非常简单,先下载 tar 包传输到Linux系统中,然后解压,配置环境变量,这样就好了,和前面的Hadoop安装差不多。
HBase也有三种运行模式:单机模式、伪分布式模式和分布式模式,也是通过修改配置文件来选择模式的。
但是注意,HBase的配置有以下先决条件:
- jdk
- Hadoop(单机模式不需要,伪分布式和分布式需要)
- SSH
其中SSH的配置参考 :https://blog.csdn.net/lixufei12138/article/details/102556824
接下来就是修改配置文件,按照上面链接的内容即可,这里不做过多的赘述。
这里放一张环境变量的截图,图中顺带有我安装的版本信息。

还是写一下HBase 伪分布式配置:
(1)配置 /opt/module/hbase-1.3.1/conf/hbase-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_CLASSPATH=/opt/module/hadoop-2.7.2/etc/hadoop
export HBASE_MANAGES_ZK=true
(2)配置/opt/module/hbase-1.3.1/conf/hbase-site.xml
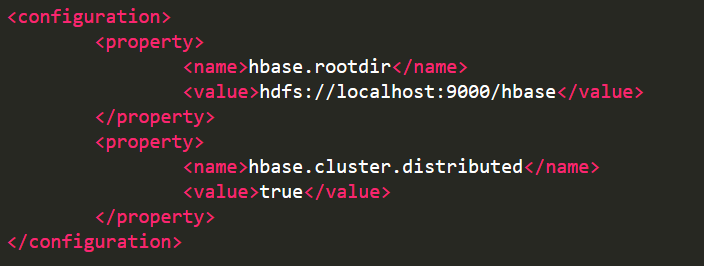
接下来就可以登录SSH,启动Hadoop,启动HBase
Hadoop的启动方式为 ./sbin/start-dfs.sh
Hbase 的启动方式为 bin/start-hbase.sh
输入jps查看是否启动成功,看到一下界面说明hbase启动成功

hbase进入shell界面的命令:
bin/hbase shell
注:Linux中安装eclipse的方式 https://blog.csdn.net/caoyang0105/article/details/77948145

