


springboot项目适配国产神通数据库
若依系统改中间件用的是中创,数据库用的是神通
问题就三个吧,一个maven中央仓库没有神通连接jar包,需要手动打包,一个神通数据库不支持replace into语法,一个神通数据库不支持find_in_set函数
首先解决第一个,maven仓库没有神通连接jar包。
可以使用maven本地打包,命令如下
mvn install:install-file -DgroupId=com.stdb -DartifactId=stoscarJDBC16 -Dversion=1.0 -Dpackaging=jar -Dfile=D:\神通数据库连接工具\dbstudio\lib\oscarJDBC.jar
-DgroupId与-DartifactId这个可以自己随意填写,在pom文件中引入时修改对应即可,-Dfile为你jar包所在的目录(可以在神通连接工具的目录下找到),打包成功后在pom文件中引入即可,引入方法如下,之后就可以正常连接了
dependency>
<groupId>com.stdb</groupId>
<artifactId>oscar</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${pom.basedir}/src/main/resources/lib/oscarJDBC.jar</systemPath>
</dependency>
或者
<dependency>
<groupId>com.stdb</groupId>
<artifactId>stoscarJDBC16</artifactId>
<version>1.0</version>
</dependency>
数据源配置如下:

# 数据源配置 spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.oscar.Driver druid: master: url: jdbc:oscar://192.168.xx.xx:2003/OSRDB username: xxxxxx password: xxxxx
或者
# 数据源配置 spring: datasource: type: com.alibaba.druid.pool.DruidDataSource driverClassName: com.oscar.Driver #驱动名 druid: # 主库数据源 master: url: jdbc:oscar://你的IP:2004/数据库名?serverTimezone=UTC&useSSL=FALSE #神通数据库默认端口为2003 username: 连接的用户 password: 密码
第二个,不支持replace into,这个找了挺久,包括问了神通那边的人,确定神通数据库是不支持这个,所以只能改SQL,把一条拆分为两条
此语法逻辑就是存在则更新/不存在就新增
第三个,不支持find_in_set,这个函数具体作用此处就不写了,百度上大把,也是确定神通数据库不支持的,解决方法如下:
在神通数据库的函数新增名为find_in_set的函数,具体代码如下
CREATE OR REPLACE FUNCTION MONITOR_DEV.FIND_IN_SET(PIV_STR1 IN CHARACTER VARYING(8000),PIV_STR2 IN CHARACTER VARYING(8000),P_SEP IN CHARACTER VARYING(8000) DEFAULT ',') RETURNS NUMERIC(1000,38) AS l_idx number:=0; -- 用于计算piv_str2中分隔符的位置 str varchar2(500); -- 根据分隔符截取的子字符串 piv_str varchar2(500) := piv_str2; -- 将piv_str2赋值给piv_str res number:=0; -- 返回结果 loopIndex number:=0; BEGIN -- 如果piv_str中没有分割符, 直接判断piv_str1和piv_str是否相等, 相等 res=1 IF instr(piv_str, p_sep, 1) = 0 THEN IF piv_str = piv_str1 THEN res:= 1; END IF; ELSE -- 循环按分隔符截取piv_str LOOP l_idx := instr(piv_str,p_sep); loopIndex:=loopIndex+1; -- 当piv_str中还有分隔符时 IF l_idx > 0 THEN -- 截取第一个分隔符前的字段str str:= substr(piv_str,1,l_idx-1); -- 判断 str 和piv_str1 是否相等, 相等 res=1 并结束循环判断 IF str = piv_str1 THEN res:= loopIndex; EXIT; END IF; piv_str := substr(piv_str,l_idx+length(p_sep)); ELSE -- 当截取后的piv_str 中不存在分割符时, 判断piv_str和piv_str1是否相等, 相等 res=1 IF piv_str = piv_str1 THEN res:= loopIndex; END IF; -- 无论最后是否相等, 都跳出循环 EXIT; END IF; END LOOP; -- 结束循环 END IF; -- 返回res RETURN res; END FIND_IN_SET;
然后测试一下
所有数据如图:
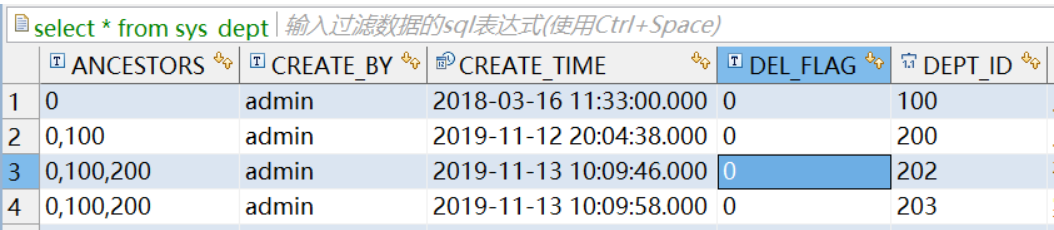
使用此函数查询ancestors字段包含100的内容
select * from sys_dept where find_in_set(100, ancestors) > 0
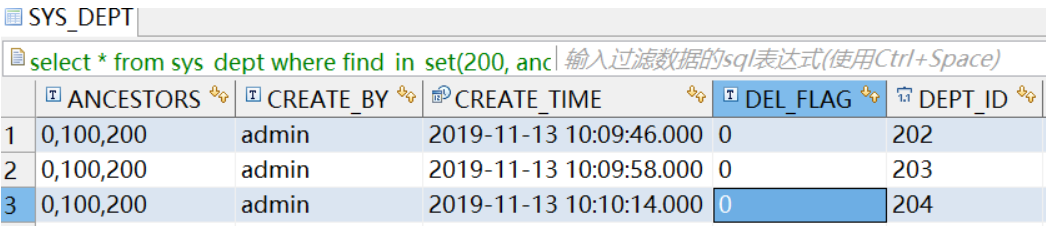
完美
转载:https://blog.csdn.net/u011738139/article/details/118701245
侵删
标签:
神通数据库


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架