数据库三大范式 ,mysql的索引类型及使用,事务的特性和隔离级别
一 数据库三大范式是什么
详情可见:https://zhuanlan.zhihu.com/p/618012849
范式,英文:Normal Form,简称NF。是我们在设计数据库时需要遵守的守则
1.第一范式:1NF 是指数据库表的每一列都是不可分割
- 每列的值具有原子性,不可再分割
- 每个字段的值都只能是单一值

eg:
当staff表中有一个字段(mobile)是用来存储职员电话,但是一般职员都有办公电话和家庭电话两个号码,那么就会出现在这个字段插入的数据会出现多个电话号码,违背了1NF
所以只要将mobile字段拆分成办公电话和家庭电话就满足1NF
2.第二范式(2NF)是在第一范式(1NF)的基础上建立起来得,满足第二范式(2NF)必须先满足第一范式(1NF)
- 如果表是单主键,那么主键以外的列必须完全依赖于主键,其它列需要跟主键有关系
- 如果表是复合主键,那么主键以外的列必须完全依赖于主键,不能仅依赖主键的一部分
以上面那张职员表(staff)为例,在这张表中一个候选键是{id,mobile,deptNo},而deptName依赖于deptNo,同样 name 依赖于 id,因此不符合第二范式的。为了满足第二范式的条件,可以将这个表拆分成staff、dept、staff_dept、staff_mobile四个表。
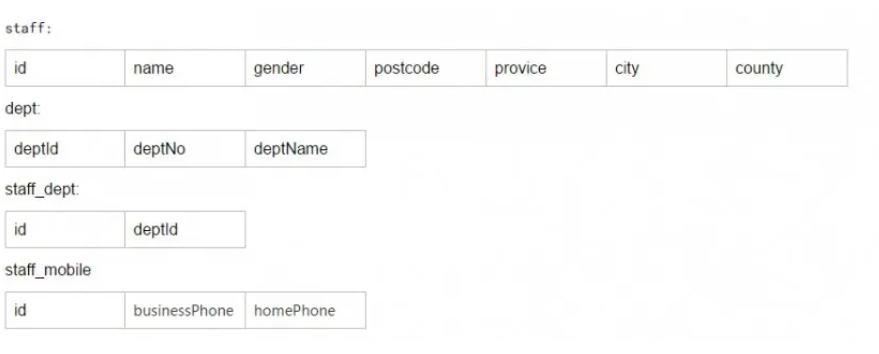
将有数据冗余的数据表通过表和表之间的外键关联起来,从而减小了数据库的冗余
3. 第三范式(3NF)是在第二范式的基础上建立起来的,即满足第三范式必须要先满足第二范式
- 表中的非主键列必须和主键直接相关而不能间接相关;也就是说:非主键列之间不能相关依赖
- 不存在传递依赖
再以上面的staff表为例,province、city、county依赖于postcode(邮编),而postcode依赖于id,换句话说,province、city、county传递依赖于id,违反了第三范式规则。为了满足第三范式的条件,我们可以再将staff表拆分成staff和address两个表
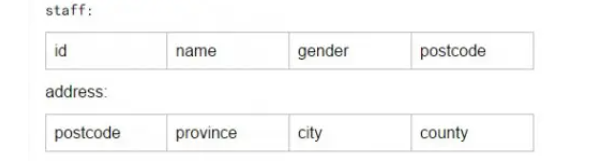
二 mysql有哪些索引类型,分别有什么作用
索引的本质:通过不断的缩小想要的数据范围筛选出最终的结果,同时将随机事件(一页一页的翻)变成顺序事件(先找目录、找数据)
1.主键索引(聚簇索引)
主键,表不建立主键,也会有个隐藏字段是主键,是主键索引,mysql是基于主键索引构建的b+树,如果没有主键,如果按主键搜索,速度是最快的--->一定会有主键索引
2.辅助索引(普通索引,其他索引)
给某个自己字段加索引,django中 index=True,通过该字段查询,会提高速度,如果字段 变化小(性别,年龄),不要建立普通索引
CREATE INDEX index_id ON tb_student(id);
3.唯一索引(unique)
- 不是为了提高访问速度,而是为了避免数据出现重复
- 唯一索引通常使用 UNIQUE 关键字
CREATE UNIQUE INDEX index_id ON tb_student(id);
4.组合索引(联合索引)
-django 中:class Meta:
class Meta:
indexes = [
models.Index(fields=['field1', 'field2'], name='composite_index'),
]
-CREATE INDEX index_name ON table_name (column1, column2, column3);
5.全文索引-->基本不用
like %你%
全文索引主要用来查找文本中的关键字,只能在 CHAR、VARCHAR 或 TEXT 类型的列上创建。
在 MySQL 中只有 MyISAM 存储引擎支持全文索引。
全文索引允许在索引列中插入重复值和空值。
不过对于大容量的数据表,生成全文索引非常消耗时间和硬盘空间。
创建全文索引使用 FULLTEXT 关键字
6.倒排索引
7.hash索引
8.B+树索引
9.前缀索引
用于快速检索包含特定前缀的字符串。它通常用于搜索引擎、自动补全功能和单词查找等应用中。前缀索引将字符串按照前缀逐级存储,以便快速定位包含特定前缀的字符串。这种数据结构可以大大提高字符串检索的效率。
三 事务的特性和隔离级别
1.事务的四大特性:
- 原子性(Atomicity):事务中的所有操作要么全部提交成功,要么全部失败回滚,保证了事务的完整性。
- 一致性(Consistency):事务执行前后的状态要一致。
- 隔离性(Isolation):事务之间相互隔离,不受影响。
- 持久性(Durability):一旦事务提交,其对数据库的修改就是永久性的,即使数据库发生故障也不会丢失。
2.隔离级别
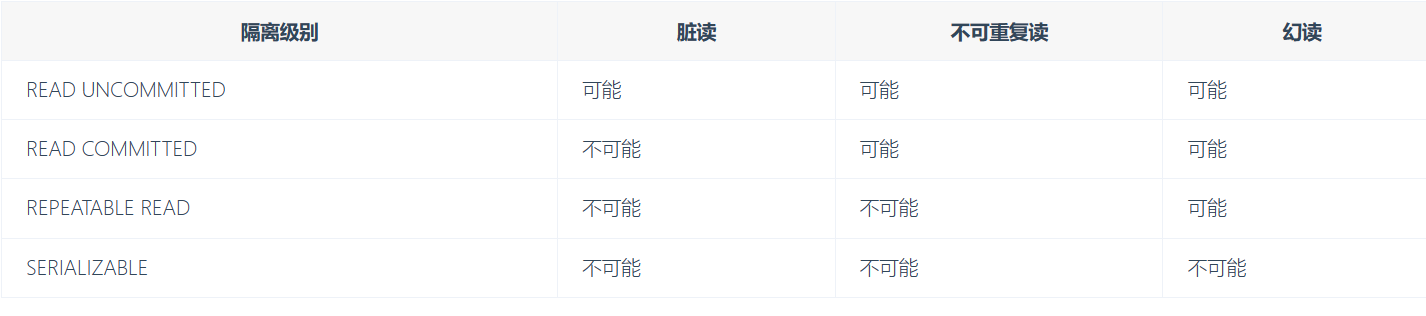
# 如果不考虑事务的隔离性,会发生以下问题:
脏写(Dirty Write):一个事务修改了另一个事务提交修改过的数据
脏读(Dirty Read):读到了其他事务未提交的数据
不可重复读:是在一个事务内,最开始读到的数据和事务结束前的任意时刻读到的同一批数据出现不一致的情况
幻读:select 某记录是否存在,不存在,准备插入此记录,但执行 insert 时发现此记录已存在,无法插入,此时就发生了幻读
# 不可重复读侧重表达 读-读,幻读则是说 读-写
事务执行过程中可能会遇到的一些现象,这些现象会对事务的一致性产生不同程度的影响。上面严重性现象排序:脏写 > 脏读 > 不可重复读 > 幻读
为了解决上面的问题,数据库就指定了一个隔离级别标准,隔离级别越低,就越可能发生严重的问题
-
Read uncommitted(读未提交)-ru
事务B读取到了事务A未提交的数据--->解决了更新丢失,会出现脏读
A事务在写数据时,不允许B事务进行写操作,但允许B事务进行读操作
于是 B就会读到A事务写入,但没提交的数据,于是出现脏读 -
Read committed(读已提交)-rc
写事务提交之前不允许其他事务的读操作,可以解决脏读问题。
但会出现一个事务范围内两个相同的查询却返回了不同数据
解决了更新丢失和脏读问题 -
Repeatable read(可重复读取)-rr
在开始读取数据(事务开启)时,不再允许修改操作,这样就可以在同一个事务内两次读到的数据是一样的,因此称为是可重复读隔离级别,但是有时可能会出现幻读
解决了更新丢失、脏读、不可重复读、但是还会出现幻读 -
Serializable(序列化)
要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行,如果仅仅通过“行级锁”是无法实现序列化的,必须通过其他机制保证新插入的数据不会被执行查询操作的事务访问到。
序列化是最高的事务隔离级别,同时代价也是最高的,性能很低,一般很少使用,在该级别下,事务顺序执行
可以避免脏读、不可重复读,幻读
总结:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理