一 测试环境的搭建 (test.py)
tests.py的用法
在test文件中直接写跟django没有关系的代码是直接可以写,也可以直接运行,但是只要和django相关的都不行
平时项目是如何运行django的?
在manage.py中运行
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'day48_dj.settings') # day48_dj.settings加载项目配置文件
from django.core.management import execute_from_command_line
#导入django相关的执行命令
execute_from_command_line(sys.argv)#执行来自于命令行的数据
runserver 参数传给 sys.argv
CommandParser 执行命令的
**想要执行django语句就要制作django环境**
import os
import sys
if __name__ == '__main__':
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'day58_dj.settings')
import django
django.setup() # 这时已具备django环境
# 创建表格
models.py:
class UserInfo(models.Model):
username = models.CharField(max_length=64)
password = models.CharField(max_length=64)
test.py:
# 增加数据方式一:
from app01 import models # 只能放在这里,django环境才搭建好
models.UserInfo.objects.create(username='jack1',password=123)
models.UserInfo.objects.create(username='jack2',password=123)
models.UserInfo.objects.create(username='jack3',password=123)
models.UserInfo.objects.create(username='jack4',password=123)
# 增加数据方式二:
# res=models.UserInfo(username='jack',password=123)
# res.save() # 保存数据
二 常见的查询方法
1.filter all first last
res = models.UserInfo.objects.filter() #查询所有
print(res) #<QuerySet [<UserInfo: UserInfo object (1)>, <UserInfo: UserInfo object (2)>, <UserInfo: UserInfo object (3)>, <UserInfo: UserInfo object (4)>]>
#在UserInfo类中加上,这样查询出来的结果将带上用户名,方便识别:
def __str__(self):
return self.username
res = models.UserInfo.objects.filter().all() #查询所有
print(res) #<QuerySet [<UserInfo: jack1>, <UserInfo: jack2>, <UserInfo: jack3>, <UserInfo: jack4>]>
print(res[0]) # jack1
print(res[0].username) #jack1 对象.属性
res = models.UserInfo.objects.filter().all().first() #查询出第一条
res = models.UserInfo.objects.filter().all().last() #查询出最后一条
2.values value_list
"""
values:查询的结果是列表套字典
value_list:查询结果是列表套元组,其他的用法都跟values一样
"""
res =models.UserInfo.objects.values() # 默认查询所有字段,列表套字典
print(res) # <QuerySet [{'id': 1, 'username': 'jack1', 'password': '123'}, {'id': 2, 'username': 'jack2', 'password': '123'}, {'id': 3, 'username': 'jack3', 'password': '123'}, {'id': 4, 'username': 'jack4', 'password': '123'}]>
res =models.UserInfo.objects.values('username')# 可以限制查询的字段
print(res) # <QuerySet [{'username': 'jack1'}, {'username': 'jack2'}, {'username': 'jack3'}, {'username': 'jack4'}]>
res = models.UserInfo.objects.values_list()#列表套元组,其他的用法都和values一样
print(res) # <QuerySet [(1, 'jack1', '123'), (2, 'jack2', '123'), (3, 'jack3', '123'), (4, 'jack4', '123')]>
res = models.UserInfo.objects.values_list('username')
print(res) #<QuerySet [('jack1',), ('jack2',), ('jack3',), ('jack4',)]>
3.order_by 排序 默认是升序排列,加负号就是降序
res = models.UserInfo.objects.order_by('-id')
print(res) # <QuerySet [<UserInfo: jack4>, <UserInfo: jack3>, <UserInfo: jack2>, <UserInfo: jack1>]> 按照id降序排列
4.reverse 反转,先排序,数据要先有序才能翻转
res=models.User.objects.all().order_by('-age').reverse()
print(res)
5.count 查看数量的
res = models.UserInfo.objects.count()
print(res) # 4
6.exclude 排除 除了username='kevin1的都打印出来
res=models.User.objects.exclude(username='kevin1')
7.exist 判断pk=20的是否存在 返回布尔值
res = models.User.objects.filter(pk=20).first()
三 补充:查看原生sql语句
1. 只要返回的QuerySet对象都有一个query属性,通过打印.query就可以得到原生sql语句
方法一:
res = models.UserInfo.objects.values_list('username','password','id')
print(res) # 只要返回的QuerySet对象都有一个query属性
print(res.query) # SELECT "app01_userinfo"."username", "app01_userinfo"."password", "app01_userinfo"."id" FROM "app01_userinfo"
2. 增加,更新,删除返回的都不是Queryset对象,分别返回的是 object,影响行数,影响行数,这个时候就只能使用方法二
方法二:
将以下文件放入配置文件中
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level': 'DEBUG',
},
}
}
四 基于双下滑线的查询
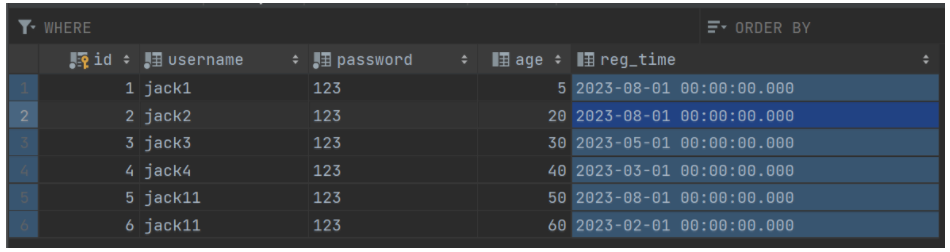
models.py:
class UserInfo(models.Model):
username = models.CharField(max_length=64)
password = models.CharField(max_length=64)
age = models.IntegerField(default=0)
reg_time = models.DateTimeField(null=True)
# create_time = models.DateTimeField(auto_now_add= True) 这条记录什么时间增加,不会更改,除非是手动更改
"""
reg_time里的参数:
auto_now = False,只要这条记录有修改,不管改的是那个字段,会自动把字段的时间修改为当前时间
auto_now_add = False,在创建一条记录的时候,会默认把当前时间填入
"""
1.年龄大于35岁的数据
res = models.UserInfo.objects.filter(age__gt=35).all()
print(res) #<QuerySet [<UserInfo: jack4>, <UserInfo: jack11>, <UserInfo: jack11>]>
2.年龄小于10岁的数据
res = models.UserInfo.objects.filter(age__lt=10).all()
print(res) # <QuerySet [<UserInfo: jack1>]>
3.年龄是10 或者 20 或者 30
res = models.UserInfo.objects.filter(age__in=[10, 20, 30]).all()
print(res) #<QuerySet [<UserInfo: jack2>, <UserInfo: jack3>]>
4.年龄在18到40岁之间的 首尾都要
# from table where age between 18 and 40
res = models.UserInfo.objects.filter(age__range=[18, 40])
print(res) <QuerySet [<UserInfo: jack2>, <UserInfo: jack3>, <UserInfo: jack4>]>
5.查询出名字里面含有s的数据 模糊查询
# from table where username like '%s%'
res = models.UserInfo.objects.filter(username__contains='s').all()
# 用户名以s开头的
res = models.UserInfo.objects.filter(username__startswith='s').all() # like 's%'
# 用户名以s结尾的
res = models.UserInfo.objects.filter(username__endswith='s').all() # like '%s'
6.查询出注册时间是 2023 5月
res = models.UserInfo.objects.filter(reg_time__month=5, reg_time__year=2023, reg_time__day=1).all()
五 外键字段的查询
5.1 数据准备
class Book(models.Model):
title = models.CharField(max_length=64)
price = models.DecimalField(max_digits=8,decimal_places=2)
publish_data = models.DateField(auto_now_add=True)
# 图书表和作者表示一对多的关系,外键建在图书表中
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
# 图书表和作者表是多对多的关系
authors = models.ManyToManyField(to='Author')
class Publish(models.Model):
name = models.CharField(max_length=64)
addr = models.CharField(max_length=64)
email = models.EmailField() # 本质还是varchar(254),该字段类型不是给models看的,而是给后面我们会学到的校验形组件看的
class Author(models.Model):
name = models.CharField(max_length=64)
age = models.IntegerField()
# 作者表和作者详情表是一对一的关系
author_detail = models.OneToOneField(to='AuthorDetail',on_delete=models.CASCADE)
class AuthorDetail(models.Model):
phone = models.CharField(max_length=64)
addr = models.CharField(max_length=64)
5.2一对多的外键字段增删改查
1.增加
# 方式一:直接写时间字段 publish_id
models.Book.objects.create(title = '三国演义',price = 123.23,publish_id=1)
# 方式二:写虚拟字段,对象,先查询出版社对象
publish_obj = models.Publish.objects.filter(pk=2).first()
models.Book.objects.create(title='红楼梦', price=666.23, publish=publish_obj)
# 在一对多创建数据的时候,既可以直接写实际的字段直接给数据的主键值,也可以写虚拟字段publish然后直接给一个数据对象,内部会自动找到当前对象的主键,然后塞入
删
models.Book.objects.filter(pk=3).delete()
修改
方式一:
models.Book.objects.filter(pk=1).update(publish_id =2)
方式二:
publish_obj=models.Publish.objects.filter(pk =1).first()
models.Book.objects.filter(pk=1).update(publish=publish_obj)
# 总结:一对多字段在增删时,既可以传id值,也可以传对象,取决于前面的字段是用实际字段还是虚拟字段
5.3多对多的外键字段增删改查
多对多的增删改查,就是在操作第三张关系表(虚拟表)的增删改查
1.如何给书籍添加作者?add
"""
add给第三张关系表添加数据,括号内既可以传数字,也可以传对象,并且都支持多个
"""
book_obj = models.Book.objects.filter(pk = 1).first()
print(book_obj.authors) # 就类似于你已经到了第三张关系表了
book_obj.authors.add(1) # 给书籍id为1的书籍绑定一个主键为1的作者
book_obj.authors.add(2,3) # 给书籍id为1的书籍分别绑定主键为2和3的作者
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
author_obj2 = models.Author.objects.filter(pk=3).first()
book_obj.authors.add(author_obj)
book_obj.authors.add(author_obj1,author_obj2)
2.删 remove
"""
remove给第三张关系表删除数据,括号内既可以传数字,也可以传对象,并且都支持多个
"""
book_obj.authors.remove(2)
book_obj.authors.remove(1,3)
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.remove(author_obj,author_obj1)
3.修改 set
"""
括号内必须传一个可迭代对象,但队形内可以是数字,也可以是对象,并且支持多个
"""
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set([1,2]) # 括号内必须给一个可迭代对象,列表元组都可以
book_obj.authors.set([3])
author_obj = models.Author.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=2).first()
book_obj.authors.set([author_obj,author_obj1])
4.清空 clear
"""
clear 括号内不要加参数,
"""
# 在第三张关系表中清空某个书籍与作者的绑定关系
book_obj.authors.clear()
六 多表查询
6.1 子查询和连表查询
1.子查询:一个SQL语句的执行结果当成另一个SQL语句的执行条件,分步操作
2.连表查询:把多个表关联在一起拼接成一个大的虚拟表,然后按照单表查询
inner join
left join
right join
union
select * from course inner join teacher on course.id=teacher_course_id where id=1;
select * from course as c inner join teacher as t on course.id=teacher_course_id left join class on class.id=c.class_id where c.id=1
6.2 正反向的概念
# 先判断是正向还是反向查询
1.正向
外键字段在我手上,我查你就是正向查询
# 图书查出版社:外键字段在图书表中,正向查询
2.反向
外键字段在我手上,你查我就是反向查询
# 出版社查图书,外键字段在图书表中,反向查询
# 判断出来正向和反向之后有什么用
正向查询按照字段查询(外键字段)
反向查询按照表名小写或者表名小写_set
6.3 子查询(基于对象的跨表查询)
1.查询书籍主键为1的出版社
# 书籍查出版社----------->正向查询------------>按字段查询
res = models.Book.objects.filter(pk=1).first()
print(res.publish) # 人民出版社 publish_obj
print(res.publish.name)
print(res.publish.addr)
2.查询书籍主键为2的作者
# 书籍查询作者------------>正向查询------------>按字段
book_obj = models.Book.objects.filter(pk=2).first()
print(book_obj.authors.all()) # app01.Author.None <QuerySet [<Author: Author object (1)>]>
print(book_obj.authors.all()[0].name)
print(book_obj.authors.all()[0].age)
for i in book_obj.authors.all():
print(i.name)
3.查询作者jack的电话号码
# 作者查作者详情------------->正向查询---------------->按字段查询
author_obj = models.Author.objects.filter(name='jerry').first()
print(author_obj.author_detail) # AuthorDetail object (1)
print(author_obj.author_detail.phone)
4.查询出版社是北京出版社出版的书
# 出版社查询书籍--------------->反向查询---------------->按照表名小写或者_set
publich_obj = models.Publish.objects.filter(name='北京出版社').first()
print(publich_obj.book_set) # app01.Book.None
print(publich_obj.book_set.all()) # <QuerySet [<Book: Book object (2)>]>
print(publich_obj.book_set.all()[0].title) # 洋哥自转1
5.查询作者是jack写过的书
# 作者查询书籍------------->反向查询------------>按照表名小写或者_set
author_obj = models.Author.objects.filter(name='tom').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all()) # <QuerySet []>
6.查询手机号是110的作者姓名
# 作者详细查询作者--------------->反向查询------------>按照表名小写或者_set
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(author_detail_obj.author) # Author object (1)
print(author_detail_obj.author.name) # Author object (1)
总结:
1. 什么时候加_Set
2. 什么时候.all()
# 当查询的结果是有多个的时候,就需要以上两个操作
6.4 多表查询之连表查询(基于双下划线的查询)
1.查询jerry的手机号和作者姓名
# 作者查询作者详情----------->正向查询------------>按字段
res = models.Author.objects.filter(name='jerry').values('author_detail__phone', 'name')
# 作者详情查询作者信息------------->反向----------------->表名小写
res = models.AuthorDetail.objects.filter(author__name='jerry').values('phone', 'author__name')
2.查询书籍主键为1的出版社名称和书的名称
# 书籍查出版社------------------>正向查询------------>按字段
res = models.Book.objects.filter(pk=1).values('publish__name', 'title')
# 出版社查询书籍---------->反向查询----------->按表名小写
res = models.Publish.objects.filter(book__pk=1).values('name', 'book__title')
3.查询书籍主键为1的作者姓名
# 书籍查询作者------------->正向查询------------>按字段
res = models.Book.objects.filter(pk=1).values('authors__name')
# 作者查询书籍-------------->反向查询----------->按表名小写
res = models.Author.objects.filter(book__pk=1).values('name')
4 查询书籍主键是1的作者的手机号
# 书籍---->作者----->作者详情
# book 正向 author 正向 author_detail
res = models.Book.objects.filter(pk=2).values('authors__author_detail__phone')
10.5 聚合查询(aggregate)
sum max min avg count
先导入:from django.db.models import Max, Min, Sum, Avg, Count
"""
以后在导模块的时候,只要是跟数据库相关的一般都在
django.db
django.db.models
"""
求书籍表中得书的平均价格
# sql:select avg(price) from table group by ''
res = models.Book.objects.aggregate(Avg('price'))
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('id'))
print(res)
6.6分组查询(annocate)
# 分组查询 sql中是:group by
"""
分组之后只能取到分组的依据,按照什么字段分组就只能取到这个字段的值,前提是严格模式
设置严格模式
1. 使用命令修改
查看sql_mode
show variables like '%mode%';
@@select sql_mode;
# 设置严格模式
set global sql_mode='ONLY_FULL_GROUP_BY'
2. 使用配置文件
"""
# 非严格模式就可以取到所有字段的值
1.统计每一本书的作者个数
# 按照书的id来分组
# select * from table group by id
res = models.Book.objects.annotate() # annotate这个关键字它就是按照models后面的这个表分组
res = models.Book.objects.annotate(author_num=Count('authors__pk')).values('autr_num', 'title')
res = models.Book.objects.annotate(author_num=Count('authors')).values('author_num', 'title')
2.统计每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(min_price=Min('book__price')).values('min_price', 'name')
3.统计不止一个作者的图书
# 先按照图书分组,求出每个图书的作者个数,包括了作者个数为0或者1的等,再次过滤做这个个数大于1的
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('author_num', 'title','id')
4.查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('sum_price', 'name')
6.7 F与Q查询
6.7.1 F查询
"""
1.使用F查询需要先导入:from django.db.models import F
2.作用:能够帮助你直接获取到表中某个字段对应的数据
3.在操作字符类型数据的时候,F不能够直接做到字符串的拼接
需要导入模块:from django.db.models.functions import Concat
from django.db.models import Value
"""
from django.db.models import F
1. 查询卖出数大于库存数的书籍
res = models.Book.objects.filter(maichu__gt=F('kucun')).all()
print(res[0].title)
2.将所有书籍的价格提升500块
# sql: update book set price = price+500 ;
res = models.Book.objects.update(price=F('price')+500)
3.将所有书的名称后面加上爆款两个字
# 如果是更新的字符串不能够这么来写,专业的语法来写
res = models.Book.objects.update(title=F('title')+'爆款') # 不能这样写,会报错
from django.db.models.functions import Concat
from django.db.models import Value
res = models.Book.objects.update(title=Concat(F('title'), Value('爆款')))
6.7.2 Q 查询
"""
filter括号内多个参数是and关系
使用Q查询需要先导入:from django.db.models import Q
Q 包裹 | 与,分隔实现or关系
~ 非,相当于not关系
高阶用法:能够将查询条件的左边也变成字符串的形式
q = Q() 先产生一个空对象
and 关系是可以修改的
q.connector = 'or' ,就把and关系改成or了
q.children.append(('sale__gt',100))
q.children.append(('price__lt',100))
models.Book.objects.filter(q) # 默认的还是q关系
"""
# 适用于或者的关系查询
'''Q查询'''
from django.db.models import Q
# 1.查询卖出数大于100或者价格小于600的书籍
# select *from table where maichu>100 or price < 600;
res = models.Book.objects.filter(maichu__gt=100, price__lt=600).all() # and关系
res = models.Book.objects.filter(Q(maichu__gt=100), Q(price__lt=600)).all() # and关系 <QuerySet []>
res = models.Book.objects.filter(Q(maichu__gt=100)| Q(price__lt=600)).all() # OR关系 <QuerySet []>
res = models.Book.objects.filter(~Q(maichu__gt=100)| Q(price__lt=600)).all() # OR关系 <QuerySet []>
res = models.Book.objects.filter(~Q(maichu__gt=100)| ~Q(price__lt=600)).all() # OR关系 <QuerySet []>
res = models.Book.objects.filter(~(Q(maichu__gt=100)| Q(price__lt=600))).all() # OR关系 <QuerySet []>
# Q的高阶用法
q = Q()
q.connector = 'or'
# param = requests.GET.get("param")
q.children.append(("maichu__gt", 600))
# q.children.append((param +"__gt", 600))
q.children.append(("price__lt", 100))
res = models.Book.objects.filter(q)
print(res)
七 django中如何开启事务
# 事务的四大特性(ACID)
原子性:不可分割的最小单位
隔离性:跟原子性是相辅相成的
持久性:事物之间互相不干扰
一致性:事物一旦确认永久生效
# 事务的隔离级别
# 事务的几个关键
1.开启事务
start transaction;
2. 提交事务
commit;
3. 回滚事务
rollback;
# 作用:保证安全,保证多个SQL语句要么同时执行成名, 要么同时失败
'''Django中如何开启事务'''
from django.db import transaction
try:
with transaction.atomic():
# sql1
# sql2
...
# 在with 代码块书写的所有的orm操作都属于同一个事务
models.Book.objects.filter(maichu__gt=100, price__lt=600).update()
models.Book.objects.filter(maichu__gt=100, price__lt=600).create()
except Exception as e:
print(e)
transaction.rollback()
'''BBS作业里面就可以使用事务'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号