
软件工程第二次作业:深度学习和pytorch基础
第一部分
心得:
-
通过绪论学习对于人工智能的三大层面,机器学习的内容及应用,知识工程与机器学习关系,人工智能、机器学习、深度学习之间关系也有清楚了解,以及对于深度学习的不能及相关研究也有了了解
-
通过第二节深度学习概述学习了激活函数,单多层感知器、万有逼近定理的内容,神经网络每层作用、梯度消失、受限玻尔兹曼机和自编码器也有所学习,内容好多
问题:
- 梯度消失问题好像还不太理解
- 预训练的实际作用也不太明白感觉涉及名词过多
第二部分
代码练习
pytorch 基础练习
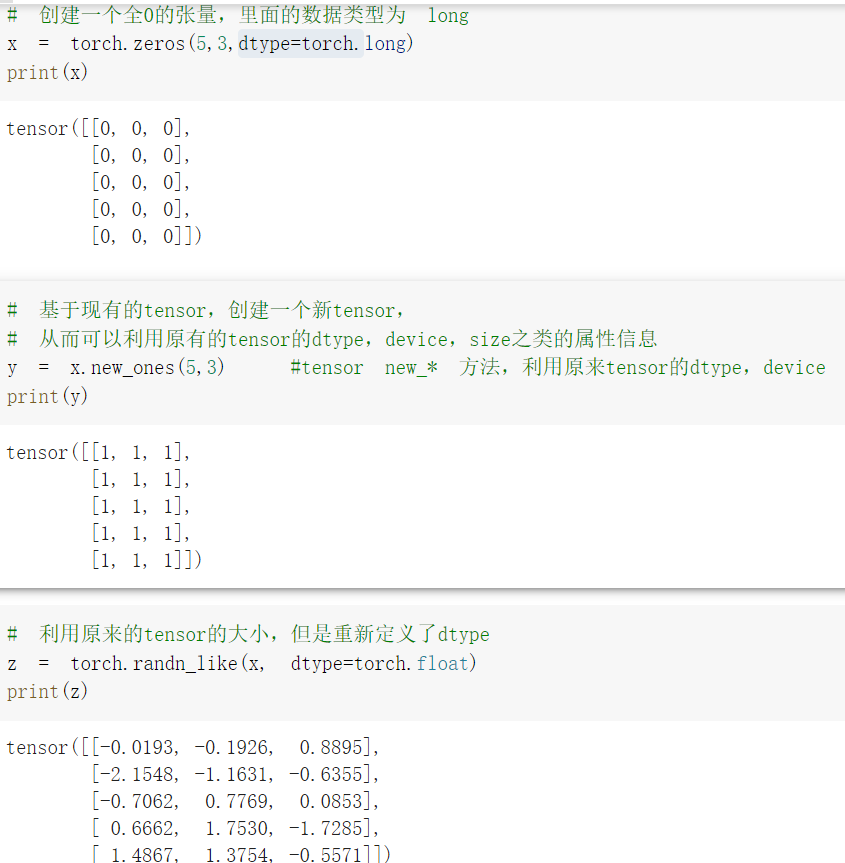
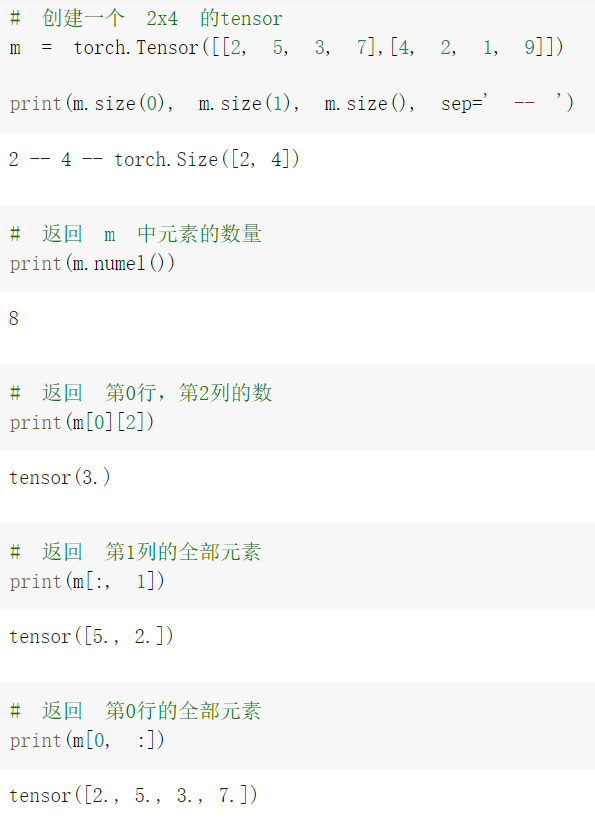
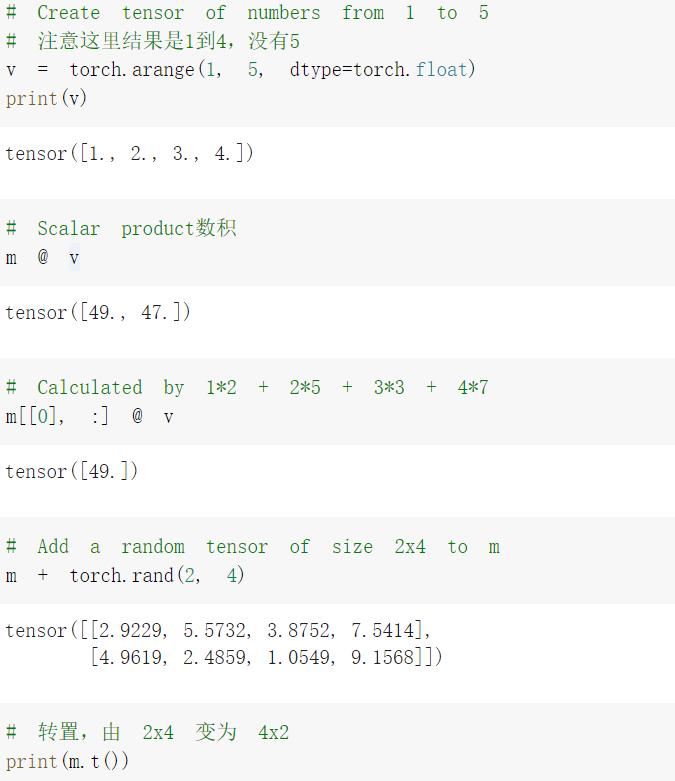
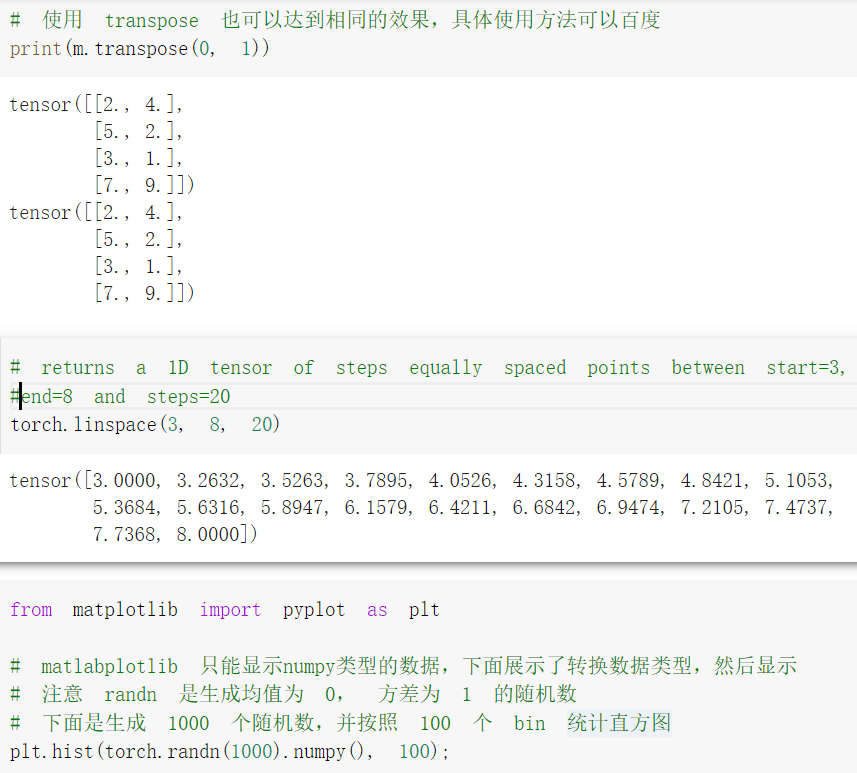
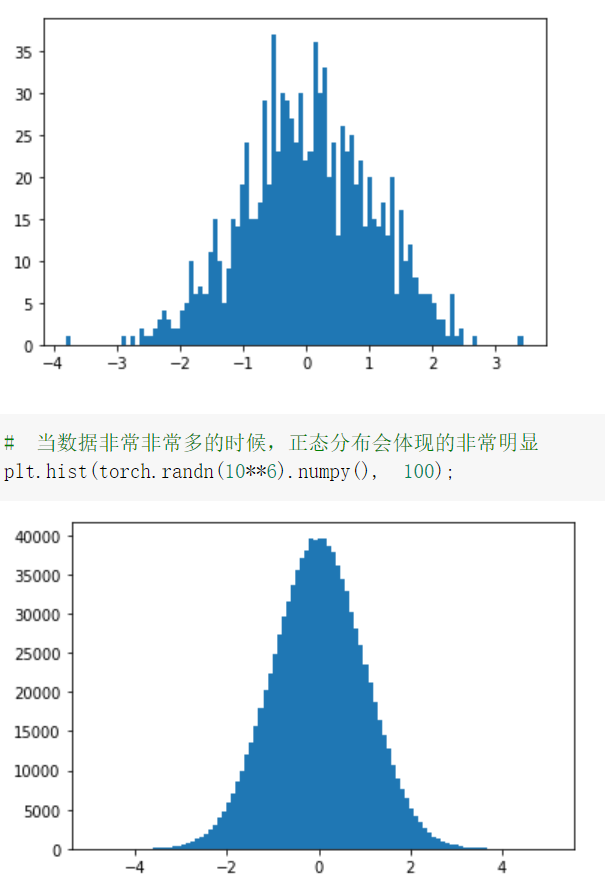
基础练习部分包括 pytorch 基础操作, 把代码输入 colab,在线运行观察效果。
 |
 |
 |
 |
|---|---|---|---|
 |
 |
 |
 |
心得:基础练习部分使学生对于基础相关代码有了一定了解,虽然记忆可能不是很深刻,但是遇到基础相关代码会及时查询,以求加深记忆,进一步学习。
螺旋数据分类
用神经网络实现简单数据分类,把代码输入 colab,在线运行观察效果
| 下载绘图函数到本地,引入基本的库,然后初始化重要参数 |
|---|
 |
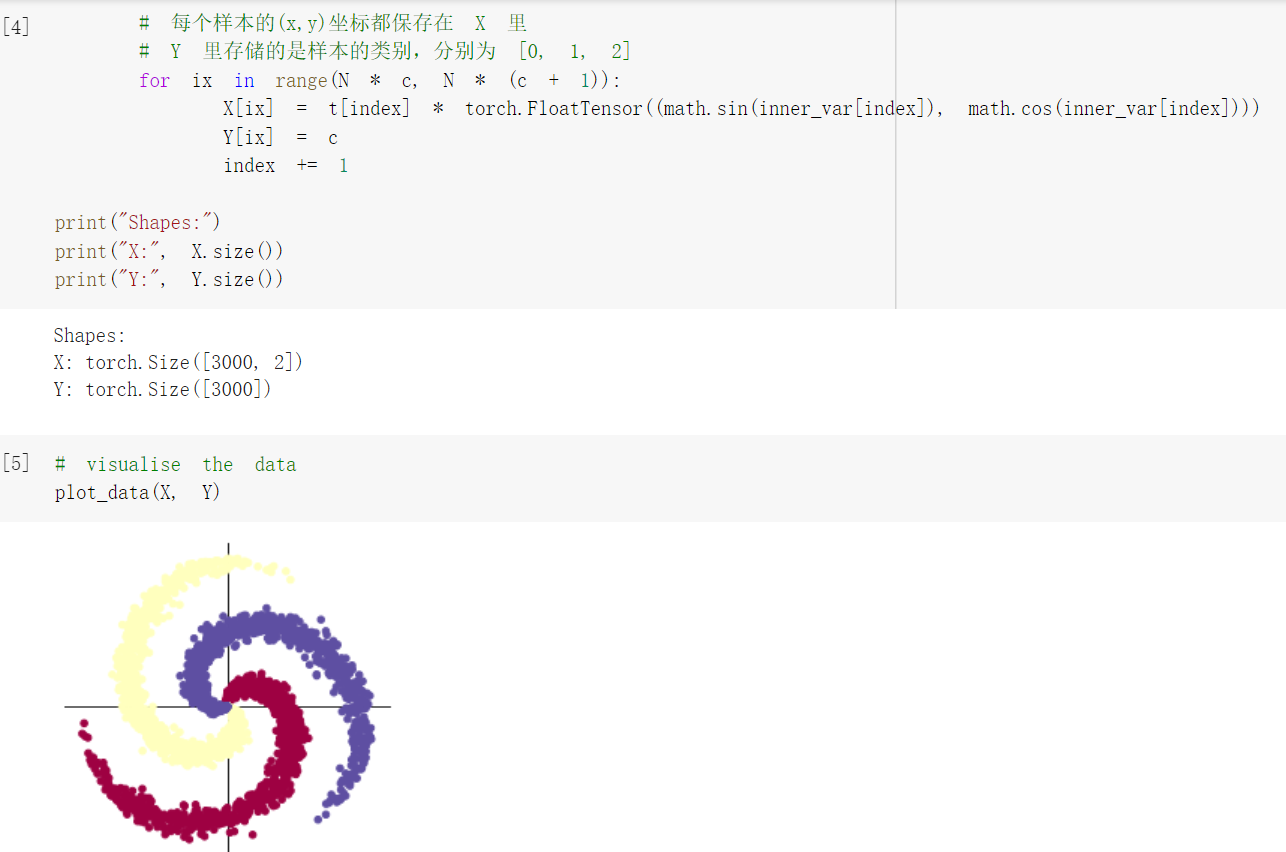
| 初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 N x C 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N x C 行。每个样本的特征维度是2,所以是 2列。 结合代码看看 3000个样本的特征是如何初始化的。 |
 |
 |
| 1.构建线性模型分类 |
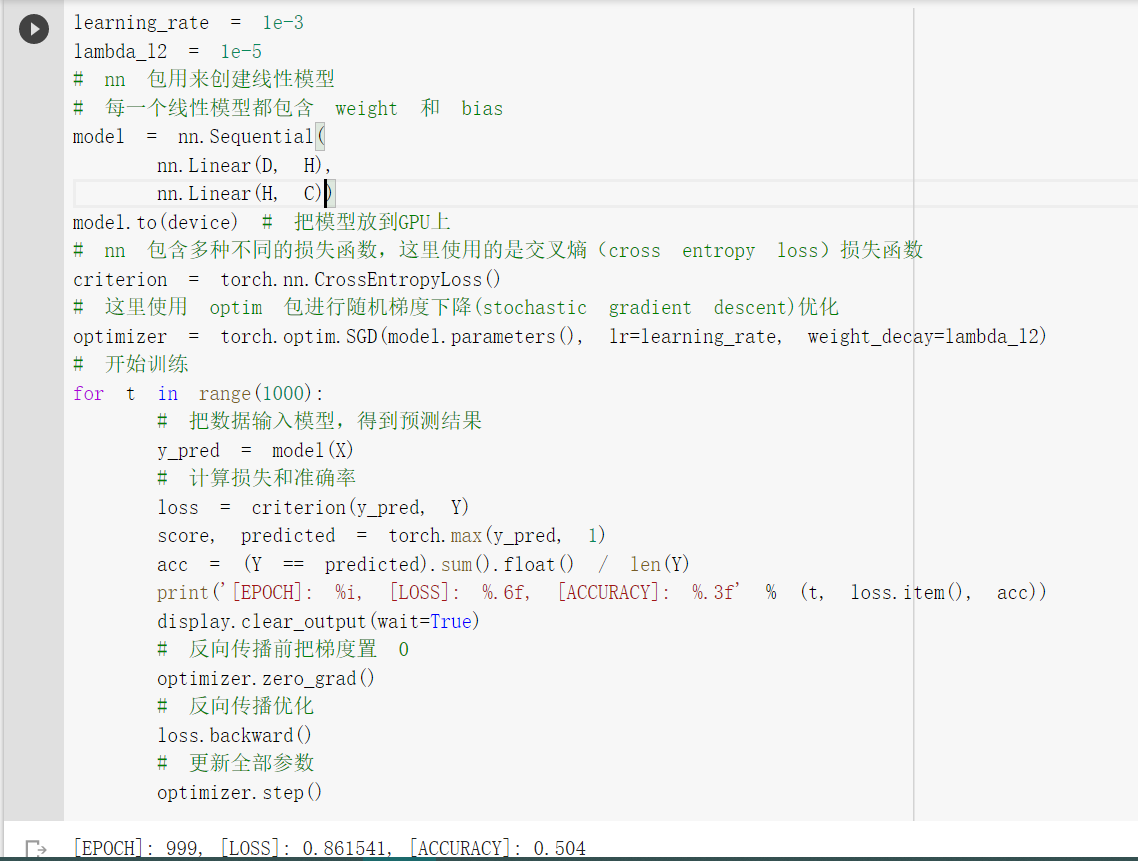 |
| 使用 print(y_pred.shape) 可以看到模型的预测结果,为[3000, 3]的矩阵。每个样本的预测结果为3个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别 score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即X方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。 此外,大家可以看到,每一次反向传播前,都要把梯度清零,这个在知乎上有一个回答,大佬们可以参考:https://www.zhihu.com/question/303070254 |
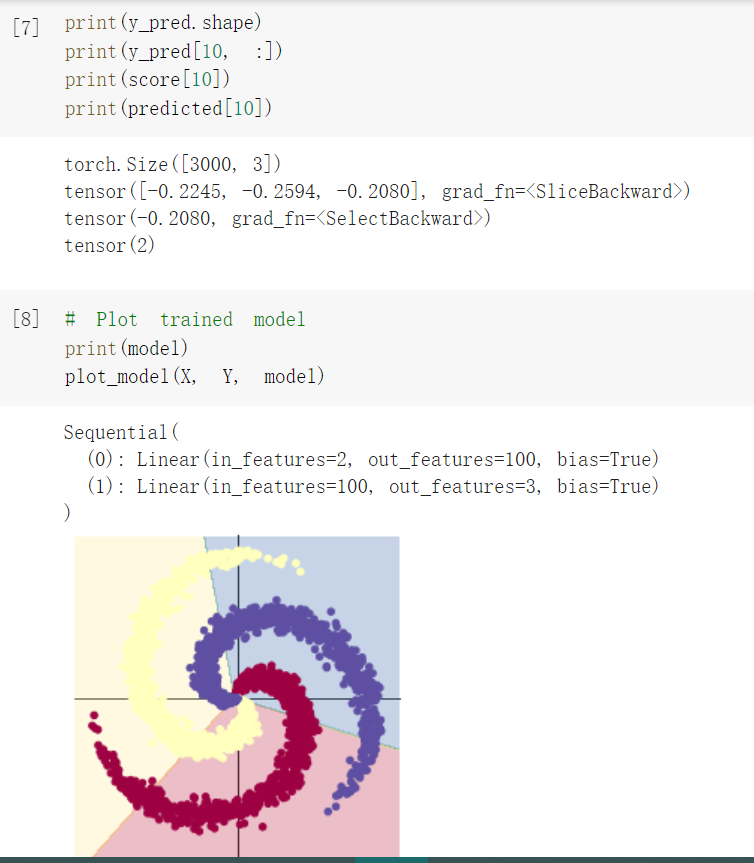 |
| 上面使用 print(model) 把模型输出,可以看到有两层: 第一层输入为 2(因为特征维度为主2),输出为 100; 第二层输入为 100 (上一层的输出),输出为 3(类别数) 从上面图示可以看出,线性模型的准确率最高只能达到 50% 左右,对于这样复杂的一个数据分布,线性模型难以实现准确分类。 |
| 2. 构建两层神经网络分类 |
 |
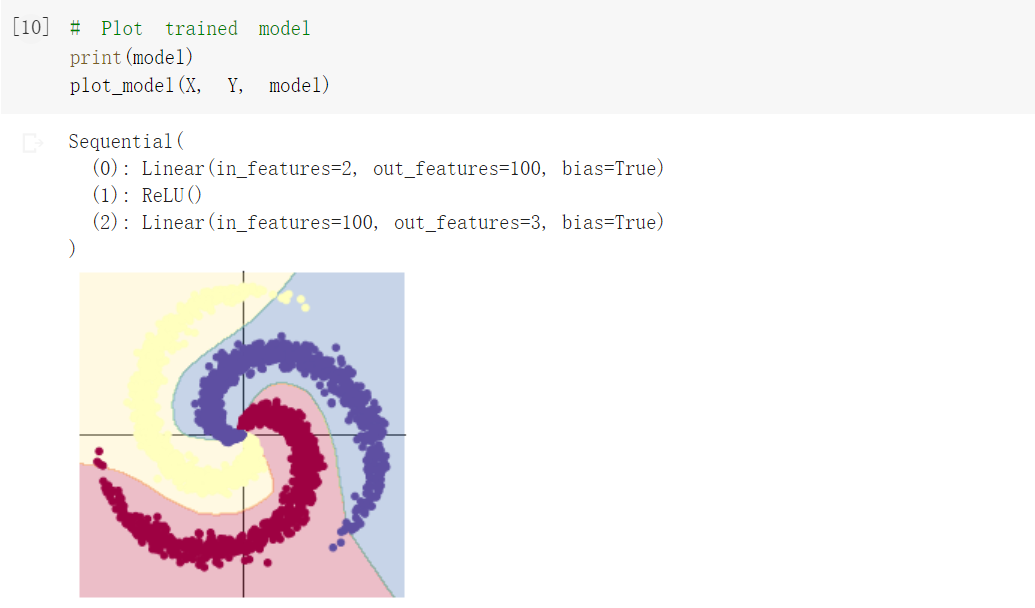 |
| 在两层神经网络里加入 ReLU 激活函数以后,分类的准确率得到了显著提高。 |
心得:上一个基础练习还好,这个 螺旋数据分类就有点难以理解,待我重新学习下https://atcold.github.io/pytorch-Deep-Learning/zh/week02/02-3/(人工神经网络(ANNs))再战,额感觉还是对于这个有些迷茫,后续会继续学习,更新中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号