【Jmeter学习】JMeter关联:JMeter正则表达式提取器与JSON提取器
JMeter使用正则表达式和JSON提取器实现关联
- 前言
- 1 关联的释义与示例
- 2 常用正则表达式详解
- 3 正则表达式提取器
-
- 3.1 参数详解
- 3.2 使用示例
- 4 JSON提取器
-
- 4.1 参数详解
- 4.2 使用示例
- 5 疑难杂症
-
- 5.1 提取多个值
- 5.2 多个值合并
- 5.3 左右边界不好确定
- 5.4 多个匹配结果
- 5.5 其他特殊用法
前言
本文主要内容是:使用使用正则表达式提取器和JSON提取器实现关联。
下文中会多次使用到
BeanShell Sampler和Debug Sampler,前者其实是起到一个mock server的作用,返回自定义的响应结果,后者能够输出JMeter的变量情况。
关于JMeter的使用,花费大量精力写了JMeter的一系列文章,有图有案例,一方面总结起来作为备忘,一方面希望能给初学者一些帮助。觉得有所帮助的朋友,请点个赞,对于疏漏之处也欢迎指教。
- JMeter逻辑控制器:https://blog.csdn.net/mu_wind/article/details/91879280
- JMeter配置元件:https://blog.csdn.net/mu_wind/article/details/92796646
- JMeter操作Mysql数据库: https://blog.csdn.net/mu_wind/article/details/93312052
- BeanShell Sampler与BeanShell断言:https://blog.csdn.net/mu_wind/article/details/93506974
- JMeter Linux下执行测试:https://blog.csdn.net/mu_wind/article/details/95733081
- JMeter自定义日志与日志分析:https://blog.csdn.net/mu_wind/article/details/95752633
1 关联的释义与示例
关联在接口测试中是一个非常重要的概念,它的意思是在两个或多个接口间建立逻辑上的依赖与联系。
关联的使用场景往往要满足以下条件:
- A接口响应结果中的数据被后续的接口所引用
- A接口响应结果中被后续接口引用的数据是动态变化且无法提前预知的
例如,登录接口-下订单接口这样2个接口组成的流程,就是非常典型的关联案例。
首先,登录接口返回包含用户身份认证信息的token,后续的下订单接口需要附带上这个token才能被服务器识别身份。
Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
要想实现这个场景,我们需要这么做:
- 在登录接口响应结果中将
token提取出来并保存在变量中,这里可以使用【正则表达式提取器】和【JSON提取器】。 - 在后续接口中引用已经保存好的
token,一般通过【HTTP信息头管理器】
形成的脚本如下。
1、登录接口的响应结果:
{
"code" : 200,
"msg" : "SUCCESS",
"data" : {
"accessToken" : "PJqx4566Ggf10qJv6firYAFS408p0us",
"info" : {
"id" : 10000,
"level" : 0,
"twiceGoogleAuth" : false,
"twiceMobileAuth" : true,
"twiceEmailAuth" : false,
"tradePwdAlways" : false,
"tradePwdHours" : false,
"lastLoginDate" : null,
"lastLoginAddress" : null,
"depositFlag" : true,
"loginCount" : 0,
"emailRegister" : false,
"nation" : 211,
"webLoginCount" : 0
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
2、从登录接口响应结果中提取token的值,并保存到名称为myToken的变量中: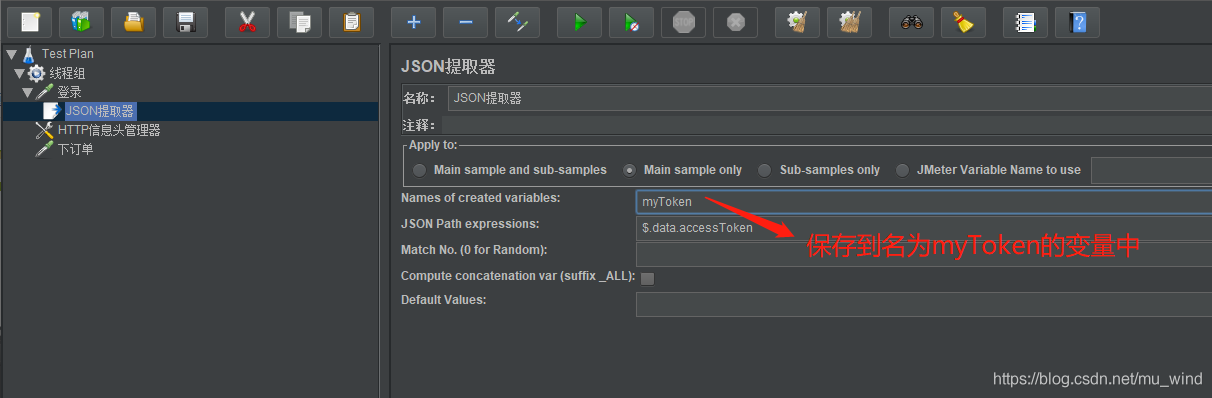
3、引用前面保存的token值(前面保存变量为什么,这里就引用什么)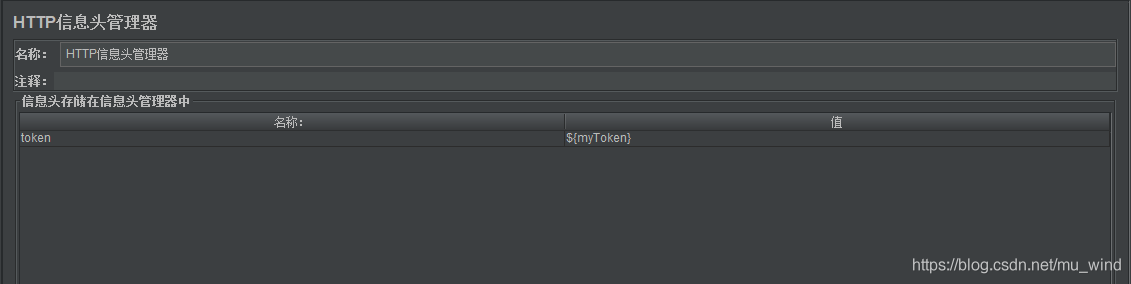
4、后续接口中,成功引用了到了myToken的值: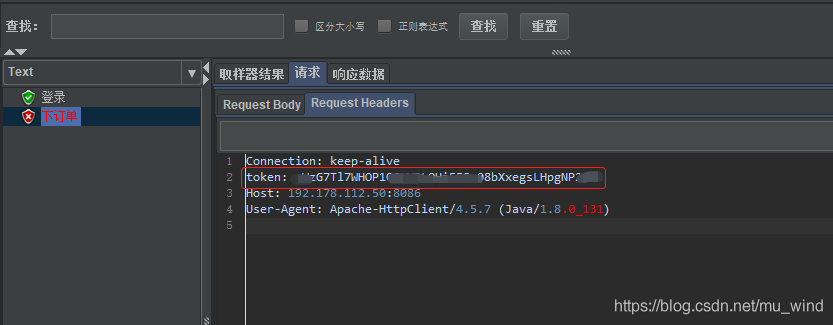
接下来,我们以 WeatherWS 这个网站的两个接口为示例,使用【正则表达式提取器】完成一个关联实现。
接下来的测试场景是这样的:
- 请求
getRegionProvince接口,得到包含各个省份code的列表,并在这个列表里提取北京的code - 将北京的
code作为getSupportCityDataSet接口theRegionCode参数的参数值,请求接口得到北京下辖的行政区域列表。
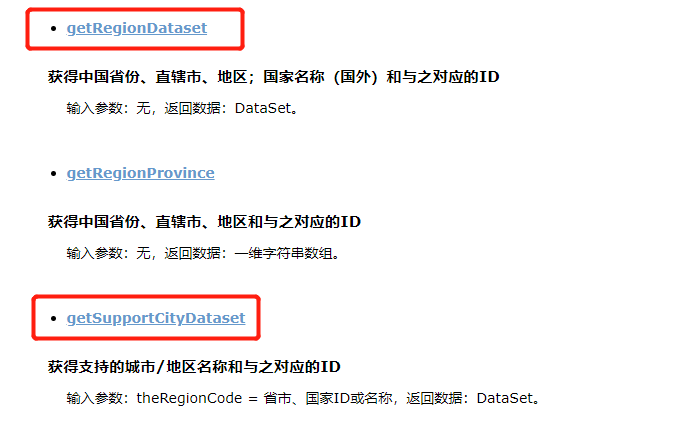
getRegionProvince的接口说明如下:
GET /WebServices/WeatherWS.asmx/getRegionDataset? HTTP/1.1
Host: ws.webxml.com.cn
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: length
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<schema xmlns="http://www.w3.org/2001/XMLSchema">schema</schema>xml</DataSet>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
getSupportCityDataSet的接口说明如下:
GET /WebServices/WeatherWS.asmx/getSupportCityDataset?theRegionCode=string HTTP/1.1
Host: ws.webxml.com.cn
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: length
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<schema xmlns="http://www.w3.org/2001/XMLSchema">schema</schema>xml</DataSet>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
根据上面的接口说明,先建立下面的脚本: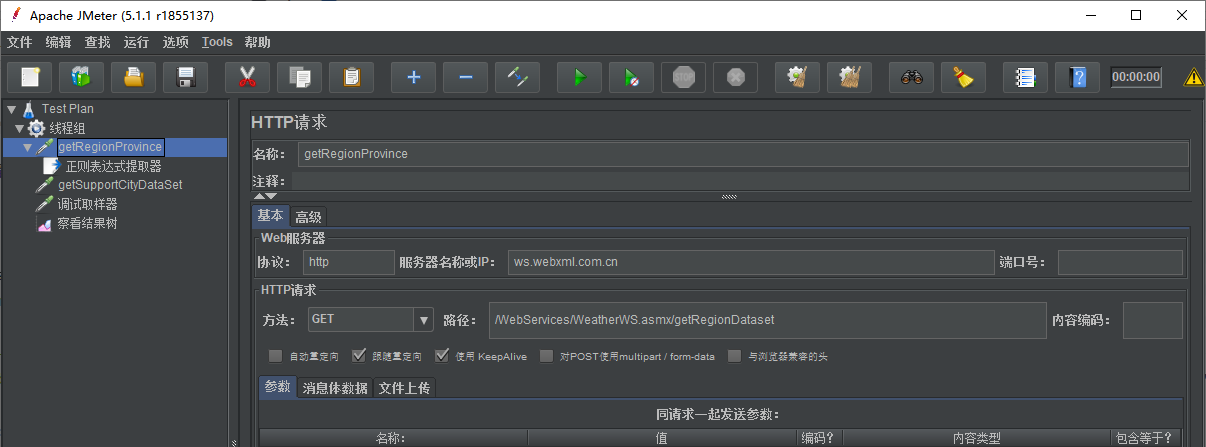
整体的脚本结构如上图所示,下面依次看每个组件的内容和作用。
1、【HTTP请求】getRegionProvince: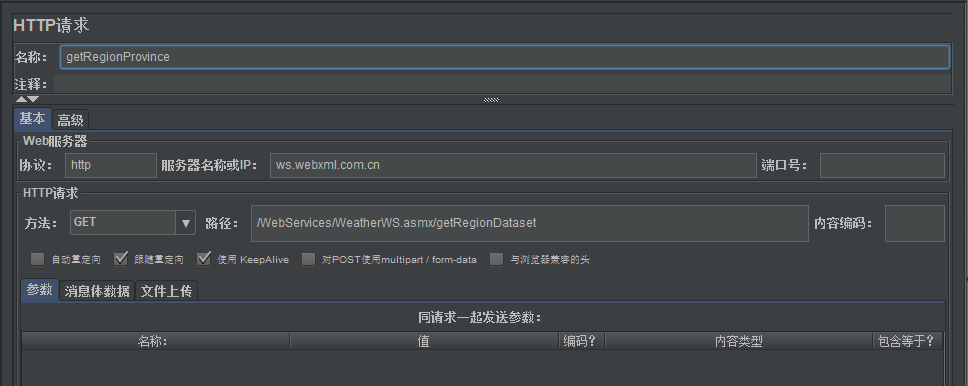
- IP:ws.webxml.com.cn
- 路径:/WebServices/WeatherWS.asmx/getRegionDataset
- 作用:获得中国省份、直辖市、地区;国家名称(国外)和与之对应的ID
- 相应结果(为节省篇幅,删除了大量无关数据):
<?xml version="1.0" encoding="utf-8"?>
<DataSet xmlns="http://WebXml.com.cn/">
<xs:schema id="getRegion" xmlns="" xmlns:xs="http://www.w3.org/2001/XMLSchema" xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
</xs:schema>
<diffgr:diffgram xmlns:msdata="urn:schemas-microsoft-com:xml-msdata" xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<getRegion xmlns="">
<Province diffgr:id="Province5" msdata:rowOrder="4">
<RegionID>3117</RegionID>
<RegionName>河北</RegionName>
</Province>
<Province diffgr:id="Province29" msdata:rowOrder="28" diffgr:hasChanges="inserted">
<RegionID>311101</RegionID>
<RegionName>北京</RegionName>
</Province>
<Country diffgr:id="Country1" msdata:rowOrder="0">
<RegionID>3320</RegionID>
<RegionName>阿尔及利亚</RegionName>
</Country>
</getRegion>
</diffgr:diffgram>
</DataSet>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
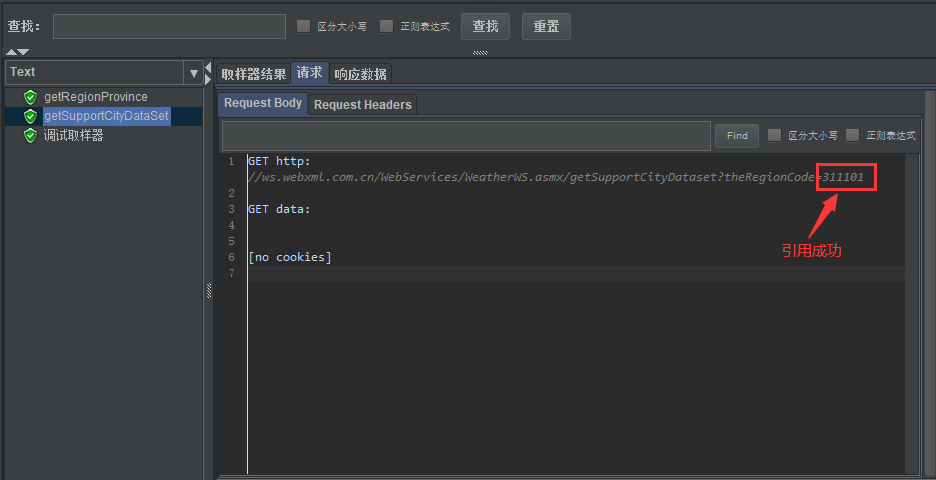
观察相应结果,北京的RegionID是311101,但如何将它提取出来并保存到变量中呢?这就要用到【正则表达式提取器】了。在HTTP请求getRegionDataset上添加【后置处理器】-【正则表达式提取器】。
2、【正则表达式提取器】:
- 引用名称:code,后面引用该值时,将使用
${code}的固定写法。 - 正则表达式:
<RegionID>(.+?)</RegionID>\r\n\ <RegionName>北京</RegionName>,注意中间的8个空格,不能多一个也不能少一个。 - 模板:
$1$,表示取第一列,下文【正则表达式提取器】会有详细解释。 - 匹配数字:1,表示取第一行,下文【正则表达式提取器】会有详细解释。
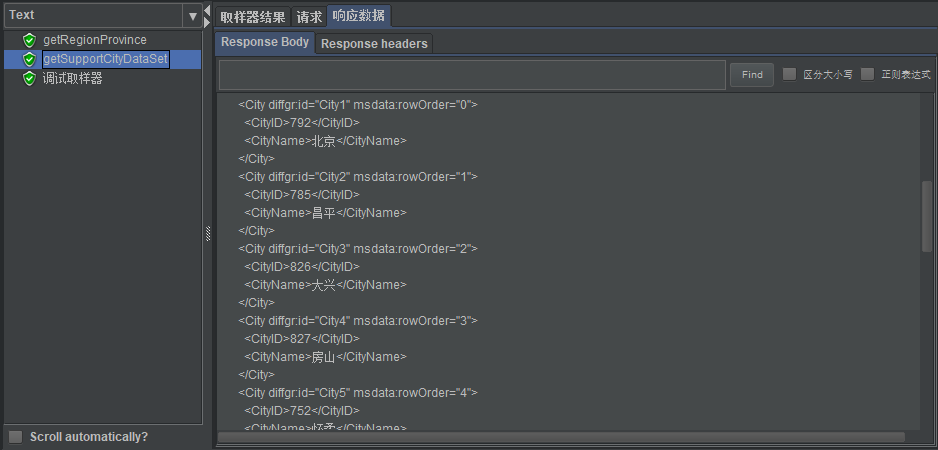
3、【HTTP请求】getSupportCityDataSet:
- IP:ws.webxml.com.cn
- 路径:/WebServices/WeatherWS.asmx/getSupportCityDataset?theRegionCode=${code}
- 作用:获得支持的城市/地区名称和与之对应的ID
- 相应结果:
![在这里插入图片描述]()
![在这里插入图片描述]()
2 常用正则表达式详解
正则表达式描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式是相对繁琐抽象的,理解和记忆难度较高,因此这里对JMeter中能用到的正则表达式语法(主要是限定符)进行一下讲解。
据我个人经验,(.+?)这个表达式基本就够用了,何况正则表达式提取远不如JSON提取器使用频率高,所以这一节大可以略过,直接看第三节。
| 字 符 | 描 述 |
|---|---|
| . | 匹配除换行符 \n 之外的任何单字符 |
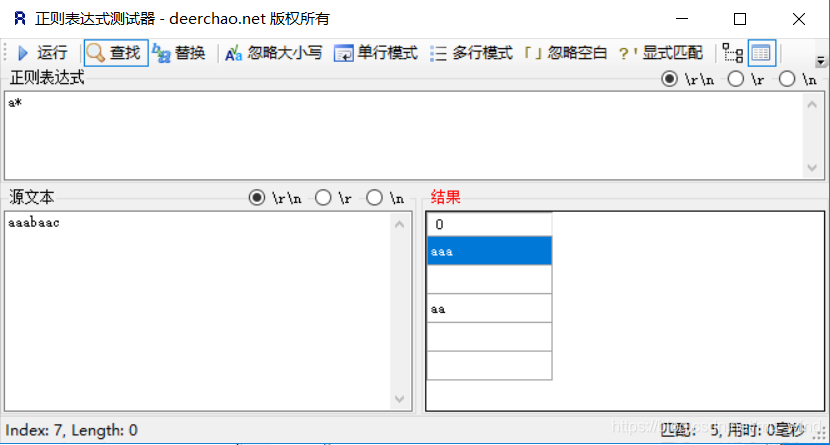
| * | 贪婪,匹配前面的子表达式零次或多次,等价于{0,} |
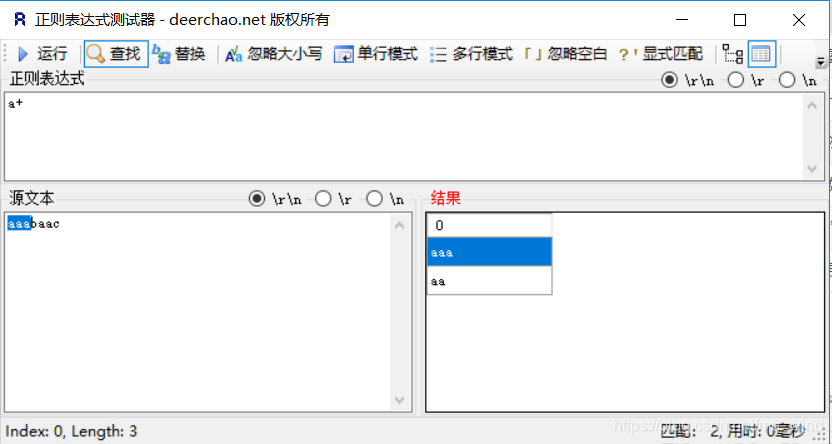
| + | 占有,匹配前面的子表达式一次或多次,等价于{1,} |
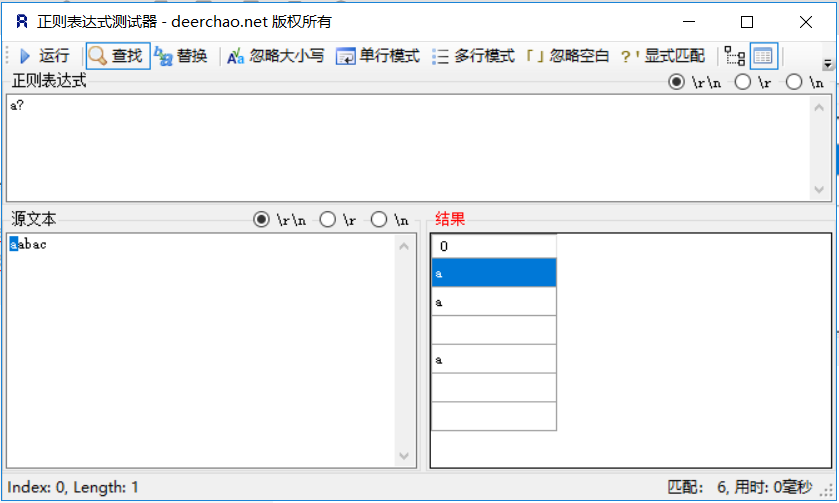
| ? | 懒惰,匹配前面的子表达式零次或一次 ,等价于 {0,1} |
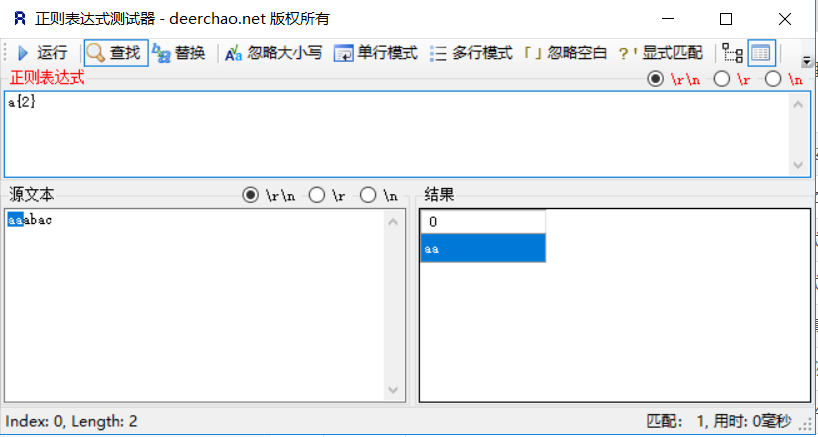
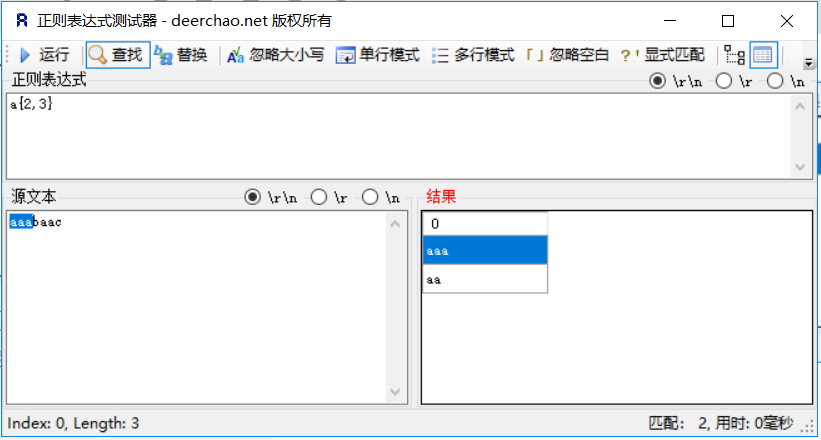
| {n} | n 是一个非负整数。匹配确定的 n 次。例如a{3}匹配“aaaaa”,能匹配到“aaa” |
| {n,m} | 重复n到m次,例如正则 “a{3,4}” 将a重复匹配3次或者4次 |
| *? | 重复任意次,但尽可能少重复,如 “acbacb” 正则 “a.*?b” 只会取到第一个"acb" |
| +? | 重复1次或更多次,但尽可能少重复,与上面一样,不同的是至少重复一次 |
| ?? | 重复0次或1次,但尽可能少重复,如 “aaacb” 正则 “a.??b” 只会取到最后的三个字符"acb" |
| {n,m}? | 重复n到m次,但尽可能少重复,如 “aaaaaaaa” 正则 “a{0,m}” 因为最少是0次所以取到结果为空 |
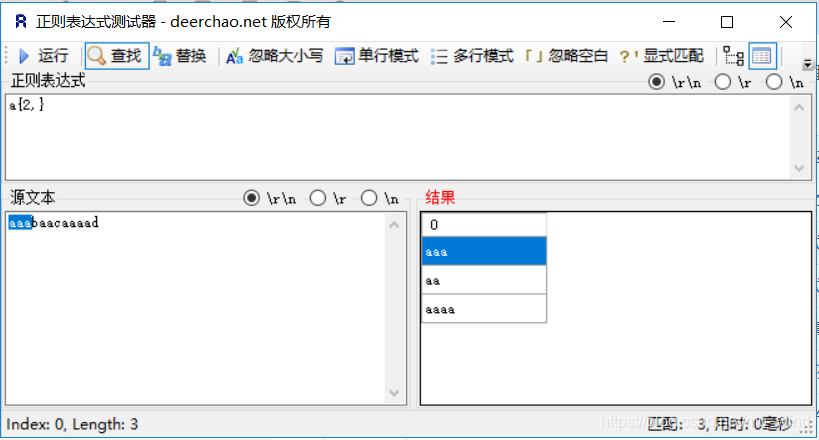
| {n,}? | 重复n次以上,但尽可能少重复,如 “aaaaaaa” 正则 “a{1,}” 最少是1次所以取到结果为 “a” |
部分表达式使用【正则表达式测试器】实测结果如下:
*:0次或多次,因为0个也被能匹配,所以b、c和末尾被匹配成空![在这里插入图片描述]()
+:一个或多个,因为至少要匹配一个,不会有空字符串![在这里插入图片描述]()
?:0个或一个,同*一样,没有a的被匹配成空字符串![在这里插入图片描述]()
a{n}:![在这里插入图片描述]()
a{n,m}:![在这里插入图片描述]()
a{n,}:![在这里插入图片描述]()
3 正则表达式提取器
正则表达式提取器一般在取样器上创建,它的作用是在取样器(包括HTTP请求和BeanShell Sampler及其他取样器)的结果中按照一定的规则提取特定的值,并保存到内存中的某一个字段上,正则表达式所在的取样器之后的组件,都能通过引用方式(格式:${XXX})使用该值。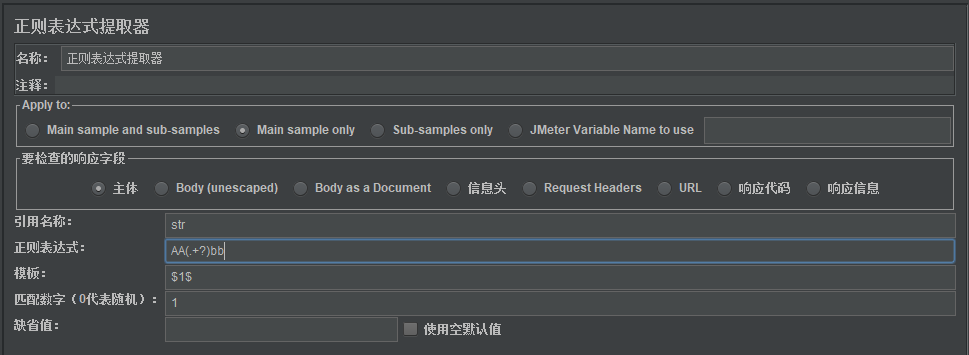
3.1 参数详解
| 名称 | 描述 | 必须 |
|---|---|---|
| 名称 | 脚本中显示的这个元件的描述性名称 | 是 |
| Apply to | Main sample only:仅适用于主样本,默认用这个就可以了 | 是 |
| Field to check | 要检查的响应字段,即在取样器响应内容的哪个区域进行匹配 | 是 |
| Name of created variable | 引用名称,即匹配到的变量存储的名称,一般会有[refname]_g(匹配数量)、[refname]_g0 (整体)、[refname]_gn(某个具体匹配值)等多个变量, | 是 |
| Regular Expression | 正则表达式,用于分析响应数据的正则表达式,除非使用$0$组,否则必须至少包含一组括号 | 是 |
| Template | 模板,如果在正则表达式中有多列结果,则可以是$2$$3$等等,表示解析到的第几个值给title,如:$1$表示解析到的第1个值 | 是 |
| Match No. (0 for Random) | 匹配数字,取第几行,0代表随机取值,-1代表全部取值,1、2、3等表示多行返回值取第几个值。 | 是 |
| Default Value | 缺省值,如果表达式没有取得到值,就使用这个默认值 | 是 |
| Use empty default value | 勾选此项后,如果未提取到值,则给变量赋予空字符串,而不是null | 是 |
3.2 使用示例
先看这么一个场景,假如响应内容ccBBmmAABBAAddBBAA,想在该响应内容中提取AAddBB并存储到参数test中,该如何处理?
首先,观察待匹配字符串的左右边界分别是BB和AA,那么正则表达式应写成BB(.+?)AA,在【正则表达式测试器】中测试一下: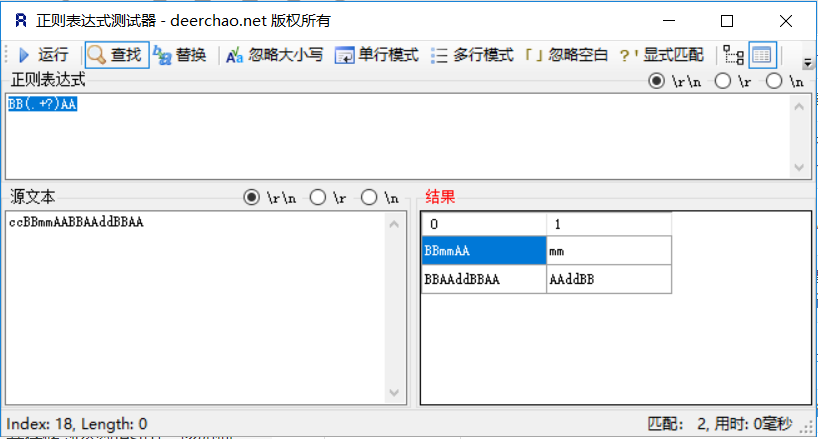
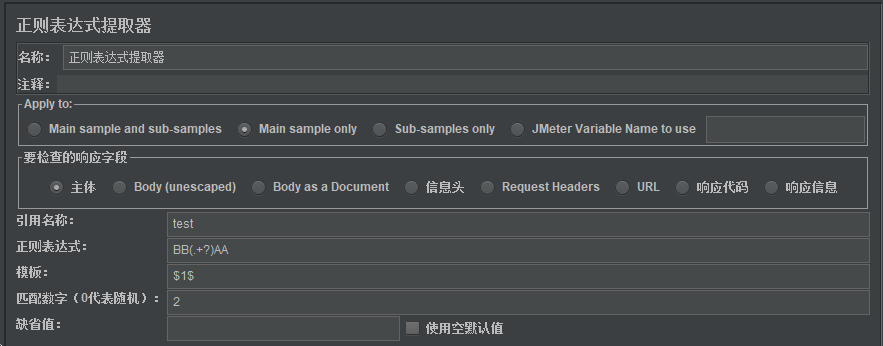
可以看到,第1列(列从0开始计数)第二行是我们想要的结果,因此【正则表达式提取器】中按下图填写: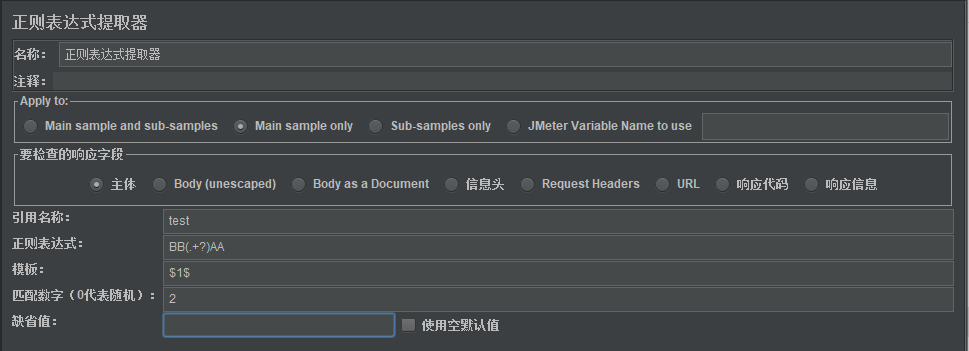
接下来,我们使用【BeanShell Sampler】模拟服务,来测试一下: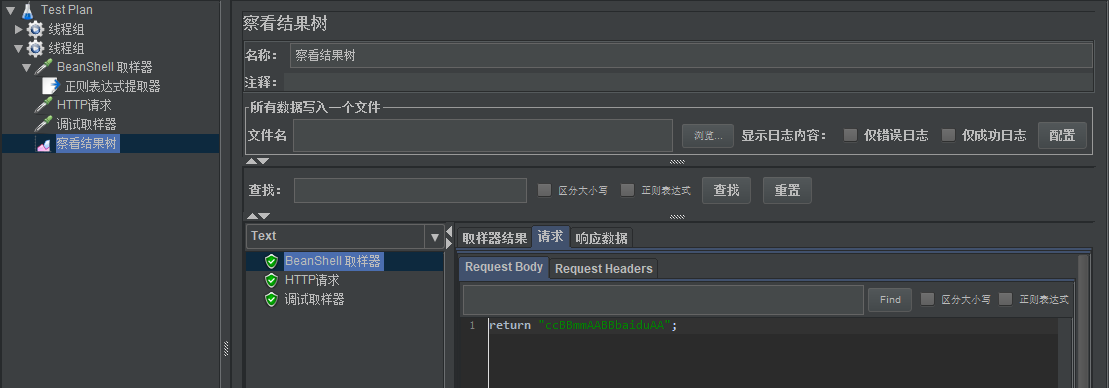
HTTP请求IP中引用正则表达式提取器提取到的test: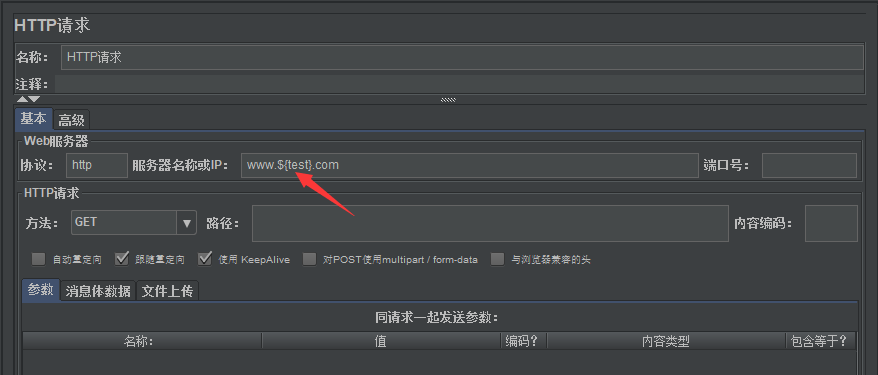
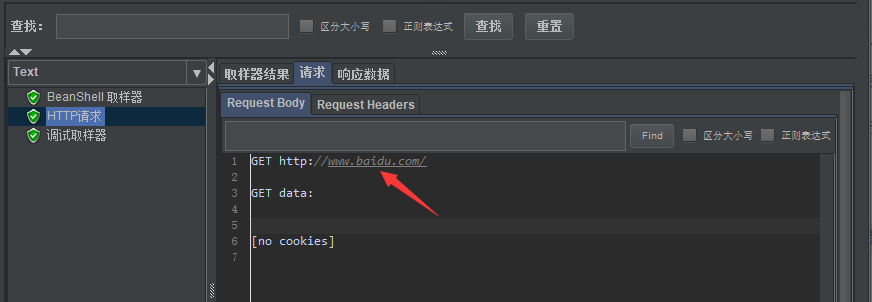
4 JSON提取器
在【后置处理器】中,有一个【JSON提取器】,与【正则表达式提取器】有类似的作用,不同的是,前者专为处理JSON型的响应结果而生。
4.1 参数详解
| 名称 | 描述 | 必须 |
|---|---|---|
| Name | 名称,脚本中显示的这个元件的描述性名称 | 是 |
| Names of chreated variables | 匹配到的数据存储的变量名称,后续可以使用${variable name}引用它 |
是 |
| JSON Path Expressions | JSON路径表达式 | 是 |
| Default Values | 默认值,如果JSON 路径表达式未能匹配到值,将使用该默认值 | 是 |
| Match No. (0 for Random) | 如果匹配到多个结果,选择使用哪个。0代表随机,-1代表全部,x代表第x个 | 是 |
| Compute concatenation var | 勾选此项后,如果匹配到多个结果,JMeter会使用","将他们连接起来,存储在的变量中 | 是 |
4.2 使用示例
接下来,我们看一个示例:
假如接口返回下面的JSON数据,我们想在其中提取“周芷若”到“name”参数中。
{
"status":200,
"data":[{"id":101,"name":"张无忌"},{"id":102,"name":"周芷若"}]
}
- 1
- 2
- 3
- 4
首先,构造脚本结果如下图,【BeanShell Sampler】作为mock server返回上面的数据:
return "{\"status\":200,\"data\":[{\"id\":101,\"name\":\"张无忌\"},{\"id\":102,\"name\":\"周芷若\"}]}";
- 1
在【BeanShell Sampler】下面添加【后置处理器】–【JSON Extractor】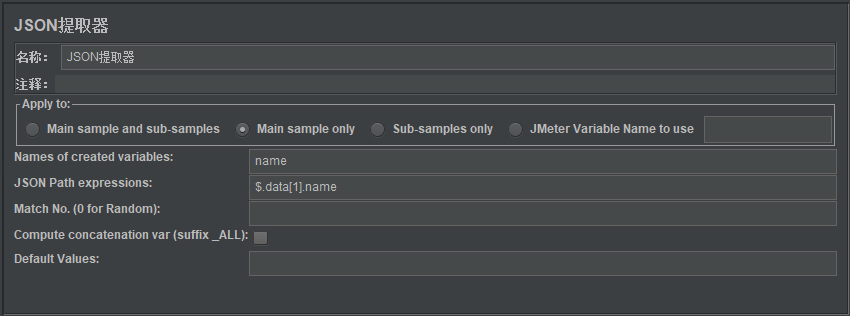
这里解释一下【JSON Path expression】的写法,
- . 首先
$.这部分是固定写法 data表示在JSON串以"data"为key获取value,也就是"[{\"id\":101,\"name\":\"张无忌\"},{\"id\":102,\"name\":\"周芷若\"}]"。data所对应的值是一个JSONArray(JSON数组)格式,里面有两个JSONObject(JSON对象),第二个JSONObject是我们需要的,因此再按索引值"1"去获取,写作data[1],写到这里,我们得到了{\"id\":102,\"name\":\"周芷若\"}这个JSONObject,接下来再根据name这个key去获取相应的值,就得到"周芷若"了。
运行脚本,查看结果树中的【Debug Sampler】的响应数据:
后来在自己开发接口自动化框架的过程中,借鉴JMeter的这个功能,做了一个工具类,在响应结果是JSON串的接口中提取数据十分方便。
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* @author guozhengMu
* @version 1.0
* @date 2018/12/20 13:07
* @description 根据自定义的字符串解析提取json中的特定内容
* @modify
*/
public class JsonPathExpression {
public static void main(String[] args) {
String str = "{\"data\" : {\"deth\" : {\"bids\" : [[\"3.637\", \"360000\"]],\"asks\" : [[\"4.273\", \"662\"],[[{\"a\":[1,2]}]]]}}}";
// String result = jsonPathExpression("{\"status\" : 200,\"employees\" : [{\"firstName\" : \"Bill\",\"lastName\" : \"Gates\"}, {\"firstName\" : \"George\",\"lastName\" : \"Bush\"}]}", "$.employees[1].firstName");
String result = jsonPathExpression(str, "$.data.deth.asks[1].[0].[0].a[1]");
System.out.println(result);
}
/**
* 根据路径表达式解析JSON
*
* @param jsonString 待处理的字符串
* @param matcher 路径表达式
* @return
*/
public static String jsonPathExpression(String jsonString, String matcher) {
String[] jsons = matcher.split("\\.");
JSONObject object = JSON.parseObject(jsonString);
JSONArray array = new JSONArray();
String result = "";
int index;
for (int i = 1; i < jsons.length; i++) {
if (jsons[i].contains("[")) {
// 解析数字
index = getIndex(jsons[i]);
if (i == jsons.length - 1) { // 最后一层
// 特殊情况处理
if (jsons[i].length() <= 3) {
// []必然是从array中取值
result = array.getString(index);
} else {
array = object.getJSONArray(jsons[i].split("\\[")[0]);
result = array.getString(index);
}
} else { // 不是最后一层
if (jsons[i].length() <= 3) {
try {
array = array.getJSONArray(index);
} catch (Exception e) {
object = array.getJSONObject(index);
}
} else {
// 不知道下一层是array还是object
try {
array = object.getJSONArray(jsons[i].split("\\[")[0])