【Python学习】进程和线程
一、什么是线程(thread)
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个线程指的是进程中一个单一顺序的控制流,一个进程中可以包含多个线程,每条线程并行执行不同的任务。下面,我们来举一个例子来说明线程的工作模式:
- 假设你正在读一本书,你现在想休息一下,但是你想在回来继续阅读的时候从刚刚停止阅读的地方继续读。实现这一点的一种方法是记下页码、行号和字号。阅读一本书的执行环境是这三个数字。
- 如果你有一个室友,她也在用同样的方法阅读这本书,她可以在你不用的时候拿起书,从她停下来的地方继续读。然后你可以把它拿回去,从你标记停下的地方继续阅读。
线程以相同的方式工作。CPU给你的错觉是它在同一时间做多个计算。它通过在每次计算上花费一点时间来实现这一点。它可以这样做,因为它对每个计算都有一个执行上下文。就像您可以与朋友共享一本书一样,许多任务也可以共享一个CPU。当然,真正地同时执行多线程需要多核CPU才可能实现。
多线程多用于处理IO密集型任务频繁写入读出,cpu负责调度,消耗的是磁盘空间。
二、什么是进程(process)
程序的执行实例称为进程。对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。进程是很多资源的集合。
每个进程提供执行程序所需的资源。进程具有虚拟地址空间、可执行代码、对系统对象的打开句柄、安全上下文、进程惟一标识符、环境变量、优先级类、最小和最大工作集大小,以及至少一个执行线程。每个进程都是从一个线程(通常称为主线程)开始的,但是可以从它的任何线程中创建其他线程。大部分进程都不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
多进程多用于CPU密集型任务,例如:排序、计算,都是消耗CPU的。
三、进程与线程的区别
- 线程是操作系统能够进行运算调度的最小单位,而进程是一组与计算相关的资源。一个进程可以包含一个或多个线程。
- 地址空间和其它资源(如打开文件):进程间相互独立,同一进程下的各线程间共享。某进程内的线程在其它进程不可见。
- 通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
- 创建线程比进程开销小(开一个进程,里面就有空间了,而线程在进程里面,就没必要在开一个空间了)
四、全局解释器锁GIL(Global Interpreter Lock)
我们想运行的速度快一点的话,就得使用多线程或者多进程。在Python里面,多线程被很多人诟病,为什么呢,因为Python的解释器(CPython)使用了一个叫GIL的全局解释器锁,它不能利用多核CPU,只能运行在一个CPU上面,但是你在运行程序的时候,看起来好像还是在一起运行的,是因为操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样,这个叫做上下文切换。
在CPython中,由于全局解释器锁,在同一时刻只能有一个线程进入解释器,只能有一个线程执行Python代码(即使某些面向性能的库可能会克服这个限制)。如果希望应用程序更好地利用多核计算机的计算资源,建议使用多进程。但是,如果您希望同时运行多个I/O密集型的任务,线程仍然是一个合适的选择。
五、threading模块
1、直接调用
Python中的多线程使用threading模块,运行多线程使用threading.Thread(target=方法,args=(参数,)),如下:

1 import threading,time
2 def run(): # 定义每个线程需要运行的函数
3 time.sleep(3)
4 print('呵呵呵')
5
6 # 串行
7 for i in range(5): # 串行,需要运行15秒
8 run()
9
10 # 多线程:
11 for j in range(5): # 并行:运行3秒
12 t = threading.Thread(target=run) # 实例化了一个线程
13 t.start()
2、使用类继承式调用
自己写一个类继承 threading.Thread类,在子类中重写 run()方法,如下:
1 import threading,time
2
3 class MyThread(threading.Thread):
4 def __init__(self, num):
5 threading.Thread.__init__(self)
6 self.num = num
7
8 def run(self): # 定义每个线程要运行的函数
9 print("running on number:%s" % self.num)
10 time.sleep(3)
11
12 if __name__ == '__main__':
13 t1 = MyThread(1)
14 t2 = MyThread(2)
15 t1.start()
16 t2.start()
threading模块的常用方法
1 # threading 模块提供的常用方法: 2 # threading.currentThread(): 返回当前的线程变量。 3 # threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 4 # threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。 5 # 除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法: 6 # run(): 用以表示线程活动的方法。 7 # start():启动线程活动。 8 # join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。 9 # isAlive(): 返回线程是否活动的。 10 # getName(): 返回线程名。 11 # setName(): 设置线程名。
3、多线程运行速度测试
下面再举一个例子来对比单线程和多线程的运行速度:
1 import requests,time,threading
2 # 定义需要下载的网页字典
3 urls = {
4 'besttest':'http://www.besttest.cn',
5 'niuniu':'http://www.nnzhp.cn',
6 'dsx':'http://www.imdsx.cn',
7 'cc':'http://www.cc-na.cn',
8 'alin':'http://www.limlhome.cn'
9 }
10 # 下载网页并保存成html文件
11 # 子线程运行的函数,如果里面有返回值的话,是不能获取到的
12 # 只能在函数外面定义一个list或者字典来存每次处理的结果
13 data = {}
14 def down_html(file_name,url):
15 start_time = time.time()
16 res = requests.get(url).content # content就是返回的二进制文件内容
17 open(file_name+'.html','wb').write(res)
18 end_time = time.time()
19 run_time = end_time - start_time
20 data[url] = run_time
21
22 # 串行
23 start_time = time.time() # 记录开始执行时间
24 for k,v in urls.items():
25 down_html(k,v)
26 end_time = time.time() # 记录执行结束时间
27 run_time = end_time - start_time
28 print(data)
29 print('串行下载总共花了%s秒'%run_time)
30
31 # 并行
32 start_time = time.time()
33 for k,v in urls.items():
34 t = threading.Thread(target=down_html,args=(k,v)) # 多线程的函数如果传参的话,必须得用args
35 t.start()
36 end_time = time.time()
37 run_time = end_time-start_time
38 print(data)
39 print('并行下载总共花了%s秒'%run_time)
串行运行结果:

并行运行结果:

从以上运行结果可以看出,并行下载的时间远短于串行。但是仔细观察会发现:并行运行时,打印出运行时间后,程序并没有结束运行,而是等待了一段时间后才结束运行。实际上并行运行时,打印的是主线程运行的时间,主线程只是负责调起5个子线程去执行下载网页内容,调起子线程以后主线程就运行完成了,所以执行时间才特别短,主线程结束后子线程并没有结束。所以0.015s这个时间是主线程运行的时间,而不是并行下载的时间。如果想看到并行下载的时间,就需要引入线程等待。
4、线程等待(t.join())
1 import requests,time,threading
2 # 定义需要下载的网页字典
3 urls = {
4 'besttest':'http://www.besttest.cn',
5 'niuniu':'http://www.nnzhp.cn',
6 'dsx':'http://www.imdsx.cn',
7 'cc':'http://www.cc-na.cn',
8 'alin':'http://www.limlhome.cn'
9 }
10 # 下载网页并保存成html文件
11 # 子线程运行的函数,如果里面有返回值的话,是不能获取到的
12 # 只能在函数外面定义一个list或者字典来存每次处理的结果
13 data = {}
14 def down_html(file_name,url):
15 start_time = time.time()
16 res = requests.get(url).content # content就是返回的二进制文件内容
17 open(file_name+'.html','wb').write(res)
18 end_time = time.time()
19 run_time = end_time - start_time
20 data[url] = run_time
21
22 # 串行
23 start_time = time.time() # 记录开始执行时间
24 for k,v in urls.items():
25 down_html(k,v)
26 end_time = time.time() # 记录执行结束时间
27 run_time = end_time - start_time
28 print(data)
29 print('串行下载总共花了%s秒'%run_time)
30
31 # 多线程
32 start_time = time.time()
33 threads = [] # 存放启动的5个子线程
34 for k,v in urls.items():
35 # 多线程的函数如果传参的话,必须得用args
36 t = threading.Thread(target=down_html,args=(k,v))
37 t.start()
38 threads.append(t)
39 for t in threads: # 主线程循环等待5个子线程执行结束
40 t.join() # 循环等待
41 print(data) # 通过函数前面定义的data字典获取每个线程执行的时间
42 end_time = time.time()
43 run_time = end_time - start_time
44 print('并行下载总共花了%s秒'%run_time)
多线程运行结果:

从执行结果来看,总运行时间只是稍稍大于最大的下载网页的时间(主线程调起子线程也需要一点时间),符合多线程的目的。有了线程等待,主线程就会等到子线程全部执行结束后再结束,这样统计出的才是真正的并行下载时间。
看到这里,我们还需要回答一个问题:为什么Python的多线程不能利用多核CPU,但是在写代码的时候,多线程的确在并发,而且还比单线程快
电脑cpu有几核,那么只能同时运行几个线程。但是python的多线程,只能利用一个cpu的核心。因为Python的解释器使用了GIL的一个叫全局解释器锁,它不能利用多核CPU,只能运行在一个cpu上面,但是运行程序的时候,看起来好像还是在一起运行的,是因为操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。这个叫做上下文切换。
Python只有一个GIL,运行python时,就要拿到这个锁才能执行,在遇到I/O 操作时会释放这把锁。如果是纯计算的程序,没有 I/O 操作,解释器会每隔100次操作就释放这把锁,让别的线程有机会 执行(这个次数可以通sys.setcheckinterval来调整)同一时间只会有一个获得GIL线程在跑,其他线程都处于等待状态。
1、如果是CPU密集型代码(循环、计算等),由于计算工作量多和大,计算很快就会达到100,然后触发GIL的释放与在竞争,多个线程来回切换损耗资源,所以在多线程遇到CPU密集型代码时,单线程会比较快;
2、如果是I\O密集型代码(文件处理、网络爬虫),开启多线程实际上是并发(不是并行),IO操作会进行IO等待,线程A等待时,自动切换到线程B,这样就提升了效率。
5、守护线程(setDaemon(True))
所谓守护线程的意思就是:只要主线程结束,那么子线程立即结束,不管子线程有没有运行完成。
1 import threading
2 def run():
3 time.sleep(3)
4 print('哈哈哈')
5
6 for i in range(50):
7 t = threading.Thread(target=run)
8 t.setDaemon(True) # 把子线程设置成为守护线程
9 t.start()
10 print('Done,运行完成')
11 time.sleep(3)
6、同步锁
多个线程同时修改一个数据的时候,可能会把数据覆盖,所以需要加线程锁(threading.lock())。我们先来看看下面两段代码
代码一:
1 import threading
2
3 def addNum():
4 global num #在每个线程中都获取这个全局变量
5 num-=1
6
7 num = 100 #设定一个全局变量
8 thread_list = []
9 for i in range(100):
10 t = threading.Thread(target=addNum)
11 t.start()
12 thread_list.append(t)
13
14 for t in thread_list: #等待所有线程执行完毕
15 t.join()
16
17 print('final num:', num ) # 运行结果为0
代码二:
1 import threading,time
2
3 def addNum():
4 global num #在每个线程中都获取这个全局变量
5
6 temp=num
7 # print('--get num:',num )
8 time.sleep(0.1)
9 num =temp-1 #对此公共变量进行减1操作
10
11 num = 100 #设定一个共享变量
12 thread_list = []
13 for i in range(100):
14 t = threading.Thread(target=addNum)
15 t.start()
16 thread_list.append(t)
17
18 for t in thread_list: #等待所有线程执行完毕
19 t.join()
20
21 print('final num:', num ) # 运行结果是99
从逻辑上看,以上两端代码是一样的,只不过第二段代码的实现过程是将num赋值给一个中间变量temp,由这个中间变量完成计算然后再把结果赋值给回num。同时,在这个过程中加了一个等待时间0.1s。为什么执行结果却不一样呢?就是因为这个0.1s的等待时间,第一个线程拿到的num值是100,在它准备计算前有一个等待时间0.1s,所以CPU切换到了第二个线程,它拿到的num的值还是100(因为第一个线程并未完成计算,num值未变).......,直到CPU切换第100个线程,它拿到的num的值还是100,100个线程每一个都没有执行完就进行了切换。等待这0.1s的时间过去以后,所有的线程一个个开始计算,最后的结果都是99。
那为什么第一段代码没有问题呢?因为CPU的计算太快了,CPU还没来得及切换计算已经完成了。

那我们如何来解决这个问题呢?可能大家想到了可以用join让所有的线程编程串行的,这样就不存在同时修改数据的可能了。但是,这样的话任务内的所有代码都是串行执行的,而我们现在只想让修改共享数据这部分串行执行,而其他部分还是并行执行。
这时,我们就可以通过同步锁来解决这种问题,代码如下:
1 import threading,time
2
3 def addNum():
4 global num #在每个线程中都获取这个全局变量
5 lock.acquire() # 加锁
6 temp=num
7 print('--get num:',num )
8 time.sleep(0.1)
9 num =temp-1 #对此公共变量进行减1操作
10 lock.release() # 解锁
11
12 lock = threading.Lock() # 实例化一把锁
13 num = 100 #设定一个共享变量
14 thread_list = []
15 for i in range(100):
16 t = threading.Thread(target=addNum)
17 t.start()
18 thread_list.append(t)
19
20 for t in thread_list: #等待所有线程执行完毕
21 t.join()
22
23 print('final num:', num ) # 运行结果是0
问题解决了,但是我们还有个疑问,这个同步锁和全局解释器锁(GIL)有什么关系呢?
- Python的线程在GIL的控制之下,线程之间,对整个Python解释器,对Python提供的C API的访问都是互斥的,这可以看作是Python内核级的互斥机制。但是这种互斥是我们不能控制的,我们还需要另外一种可控的互斥机制——用户级互斥。内核级通过互斥保护了内核的共享资源,同样,用户级互斥保护了用户程序中的共享资源。
- GIL 的作用是:对于一个解释器,只能有一个线程在执行bytecode。所以每时每刻只有一条bytecode在被一个线程执行。GIL保证了bytecode 这层面上是线程是安全的。但是如果有个操作比如 x += 1,这个操作需要多个bytecodes操作,在执行这个操作的多条bytecodes期间的时候可能中途就切换线程了,这样就出现了数据竞争的情况了。
- 那我的同步锁也是保证同一时刻只有一个线程被执行,是不是没有GIL也可以?是的,那要GIL有什么用?好像真的是没用!!
7、死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所以这两个线程在无外力作用下将一直等待下去。我们来看下面这段代码:
1 import threading,time 2 3 class myThread(threading.Thread): 4 def doA(self): 5 lockA.acquire() 6 print(self.name,"gotlockA",time.ctime()) 7 time.sleep(3) 8 lockB.acquire() 9 print(self.name,"gotlockB",time.ctime()) 10 lockB.release() 11 lockA.release() 12 13 def doB(self): 14 lockB.acquire() 15 print(self.name,"gotlockB",time.ctime()) 16 time.sleep(2) 17 lockA.acquire() 18 print(self.name,"gotlockA",time.ctime()) 19 lockA.release() 20 lockB.release() 21 def run(self): 22 self.doA() 23 self.doB() 24 if __name__=="__main__": 25 26 lockA=threading.Lock() 27 lockB=threading.Lock() 28 threads=[] 29 for i in range(5): 30 threads.append(myThread()) 31 for t in threads: 32 t.start() 33 for t in threads: 34 t.join()
执行结果如下:

第一个线程执行完doA,再执行doB时,拿到了lockB,再想拿lockA时,发现lockA已经被第二个线程拿到了,第一个线程拿不到lockA了。同样,第二个线程拿到了lockA,再想拿lockB时,发现此时lockB还在第一个线程手里没有释放,所以第二个线程同样也拿不到lockB。这样就造成了一个现象:第一个线程在等待第二个线程释放lockA,第二个线程在等第一个线程释放lockB,这样一直等下去造成了死锁。解决的办法就是使用递归锁,如下:
1 import threading,time 2 3 class myThread(threading.Thread): 4 def doA(self): 5 lock.acquire() 6 print(self.name,"gotlockA",time.ctime()) 7 time.sleep(3) 8 lock.acquire() 9 print(self.name,"gotlockB",time.ctime()) 10 lock.release() 11 lock.release() 12 13 def doB(self): 14 lock.acquire() 15 print(self.name,"gotlockB",time.ctime()) 16 time.sleep(2) 17 lock.acquire() 18 print(self.name,"gotlockA",time.ctime()) 19 lock.release() 20 lock.release() 21 def run(self): 22 self.doA() 23 self.doB() 24 if __name__=="__main__": 25 26 lock = threading.RLock() # 递归锁 27 threads=[] 28 for i in range(5): 29 threads.append(myThread()) 30 for t in threads: 31 t.start() 32 for t in threads: 33 t.join()
递归锁就是将lockA=threading.Lock()和lockB=threading.Lock()改为了lock = threading.RLock(),运行结果如下:
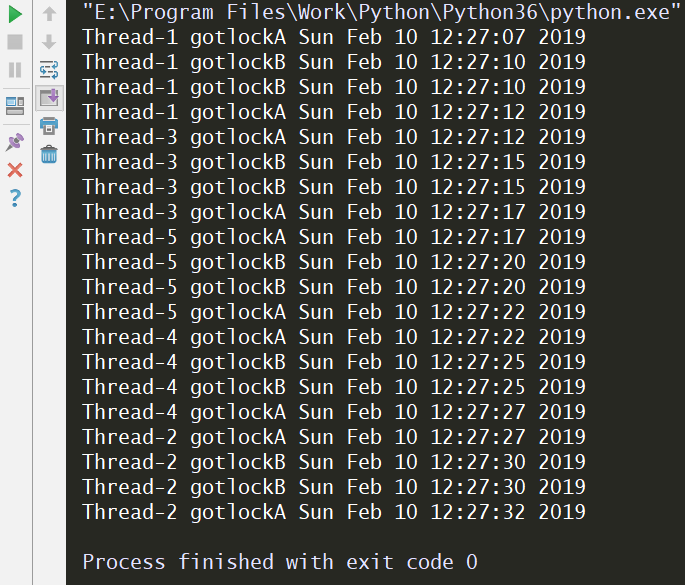
8、信号量
- 信号量是用来控制线程并发数的,BoundedSemaphore或Semaphore管理一个内置的计数器,每当调用acquire()时减1,调用release()时加1;
- 计数器不能小于0,当计数器为0时,acquire()将阻塞线程至同步锁定状态,直到其他线程调用release()。(类似于停车位的概念);
- BoundedSemaphore与Semaphore的唯一区别在于前者将在调用release()时检查计数器的值是否超过了计数器的初始值,如果超过了将抛出一个异常;
- 信号量实质上也是一把锁;
实例:
1 import threading,time 2 class myThread(threading.Thread): 3 def run(self): 4 if semaphore.acquire(): 5 print(self.name) 6 time.sleep(1) 7 semaphore.release() 8 9 if __name__=="__main__": 10 semaphore=threading.BoundedSemaphore(5) 11 thrs=[] 12 for i in range(100): 13 thrs.append(myThread()) 14 for t in thrs: 15 t.start()
9、条件变量同步(Condition)
- 有一类线程需要满足条件之后才能够继续执行,Python提供了threading.Condition 对象用于条件变量线程的支持,它除了能提供RLock()或Lock()的方法外,还提供了 wait()、notify()、notifyAll()方法;
- lock_con=threading.Condition([Lock/Rlock]):参数填写创建锁的类型,不是必填项,不传参数默认创建的是Rlock锁;
- wait():条件不满足时调用,线程会释放锁并进入等待阻塞;
- notify():条件创造后调用,通知等待池激活一个线程;
- notifyAll():条件创造后调用,通知等待池激活所有线程
实例:
import threading,time
from random import randint
class Producer(threading.Thread):
def run(self):
global L
while True:
val=randint(0,100)
print('生产者',self.name,":Append"+str(val),L)
if lock_con.acquire():
L.append(val)
lock_con.notify()
lock_con.release()
time.sleep(3)
class Consumer(threading.Thread):
def run(self):
global L
while True:
lock_con.acquire()
if len(L)==0:
lock_con.wait()
print('消费者',self.name,":Delete"+str(L[0]),L)
del L[0]
lock_con.release()
time.sleep(1)
if __name__=="__main__":
L=[]
lock_con=threading.Condition()
threads=[]
for i in range(5):
threads.append(Producer())
threads.append(Consumer())
for t in threads:
t.start()
for t in threads:
t.join()
10、同步条件(Event)
- 同步条件和条件变量同步差不多意思,只是少了锁功能,因为同步条件设计于不访问共享资源的条件环境;
- event=threading.Event():条件环境对象,初始值 为False;
实例:
1 import threading,time
2 class Boss(threading.Thread):
3 def run(self):
4 print("BOSS:今晚大家都要加班到22:00。")
5 event.isSet() or event.set()
6 time.sleep(3)
7 print("BOSS:<22:00>可以下班了。")
8 event.isSet() or event.set()
9
10 class Worker(threading.Thread):
11 def run(self):
12 event.wait()
13 print("Worker:哎……命苦啊!")
14 time.sleep(1)
15 event.clear()
16 event.wait()
17 print("Worker:Oh,Yeah!!")
18
19 if __name__=="__main__":
20 event=threading.Event()
21 threads=[]
22 for i in range(5):
23 threads.append(Worker())
24 threads.append(Boss())
25 for t in threads:
26 t.start()
27 for t in threads:
28 t.join()
11、线程队列(queue)
- queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
- 当信息必须在多个线程之间安全地交换时,队列在线程编程中特别有用;
queue队列类的方法:
1 # 创建一个“队列”对象 2 import queue 3 q = queue.Queue(maxsize = 10) 4 # queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。 5 6 # 将一个值放入队列中 7 q.put(10) 8 # 调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为:1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0,put方法将引发Full异常。 9 10 # 将一个值从队列中取出 11 q.get() 12 # 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。 13 14 # Python Queue模块有三种队列及构造函数: 15 queue.Queue(maxsize=10) # Python Queue模块的FIFO队列先进先出。 16 queue.LifoQueue(maxsize=10) # LIFO类似于堆,即先进后出。 17 queue.PriorityQueue(maxsize=10) # 还有一种是优先级队列级别越低越先出来。 18 19 # 此包中的常用方法(q = queue.Queue()): 20 # q.qsize() 返回队列的大小 21 # q.empty() 如果队列为空,返回True,反之False 22 # q.full() 如果队列满了,返回True,反之False 23 # q.full 与 maxsize 大小对应 24 # q.get([block[, timeout]]) 获取队列,timeout等待时间 25 # q.get_nowait() 相当q.get(False) 26 # 非阻塞 q.put(item) 写入队列,timeout等待时间 27 # q.put_nowait(item) 相当q.put(item, False) 28 # q.task_done() 在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号 29 # q.join() 实际上意味着等到队列为空,再执行别的操作
实例:
1 import threading,queue
2 from time import sleep
3 from random import randint
4 class Production(threading.Thread):
5 def run(self):
6 while True:
7 r=randint(0,100)
8 q.put(r)
9 print("生产出来%s号包子"%r)
10 sleep(1)
11 class Proces(threading.Thread):
12 def run(self):
13 while True:
14 re=q.get()
15 print("吃掉%s号包子"%re)
16 if __name__=="__main__":
17 q=queue.Queue(10)
18 threads=[Production(),Production(),Production(),Proces()]
19 for t in threads:
20 t.start()
21 for t in threads:
22 t.join()
六、multiprocessing模块
1、直接调用
Python中的多进程使用multiprocessing模块,运行多进程使用multiprocessing.Process(target=方法,args=(参数,)),如下:
实例一
1 import multiprocessing,time
2
3 def f(name):
4 time.sleep(1)
5 print('Hello!!',name,time.ctime())
6
7 if __name__ == '__main__':
8 p_list = []
9 for i in range(3):
10 p = multiprocessing.Process(target=f,args=('Porcess',))
11 p_list.append(p)
12 p.start()
13 for i in p_list:
14 i.join()
15
16 print('end')
实例二:一个简单的多进程,multiprocessing.Process(target=run,args=(6,))
1 import multiprocessing,threading
2 def my():
3 print('哈哈哈')
4
5 def run(num):
6 for i in range(num):
7 t = threading.Thread(target=my)
8 t.start()
9 # 总共启动5个进程,每个进程下面启动6个线程,函数my()执行30次
10 if __name__ == '__main__':
11 process = []
12 for i in range(5):
13 # args只有一个参数一定后面要加逗号
14 p = multiprocessing.Process(target=run,args=(6,)) # 启动一个进程
15 p.start()
16 process.append(p)
17 [p.join() for p in process] # 与线程用法一致
2、类式调用(与多进程类似)
实例
自己写一个类继承 multiprocessing.Process类,在子类中重写 run()方法,如下:
1 class MyProcess(multiprocessing.Process):
2 def __init__(self):
3 super(MyProcess, self).__init__()
4 # self.name = name
5
6 def run(self):
7 time.sleep(1)
8 print('Hello!!',self.name,time.ctime())
9
10 if __name__ == '__main__':
11 p_list = []
12 for i in range(3):
13 p = MyProcess()
14 p.start()
15 p_list.append(p)
16 for p in p_list:
17 p.join()
18 print('end')
3、Process类
(1)构造方法:def __init__(self, group=None, target=None, name=None, args=(), kwargs={})
- group: 线程组,目前还没有实现,库引用中提示必须是None;
- target: 要执行的方法;
- name: 进程名;
- args/kwargs: 要传入方法的参数;
(2)实例方法
- is_alive():返回进程是否在运行;
- terminate():不管任务是否完成,立即停止工作进程;
- join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数);
- start():进程准备就绪,等待CPU调度;
- run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法;
(3)属性
- daemon:和线程的setDeamon功能一样;
- exitcode(进程在运行时为None、如果为–N,表示被信号N结束);
- name:进程名;
- pid:进程号;
4、进程间通信
不同进程间的数据是不共享的,要想实现多个进程间的数据交换可以用以下方法:
(1)Queues
使用方法跟threading里的queue类似,如下:
1 from multiprocessing import Process,Queue
2
3 def f(q,i):
4 q.put([42,i,'hello'])
5 print('subprocess q_id:',id(q))
6
7 if __name__ == '__main__':
8 q = Queue()
9 p_list=[]
10 print('main q_id:',id(q))
11 for i in range(3):
12 p = Process(target=f, args=(q,i))
13 p_list.append(p)
14 p.start()
15 print(q.get())
16 print(q.get())
17 print(q.get())
18 for p in p_list:
19 p.join()
(2)Pipes
Pipes函数的作用是:返回由管道连接的一对连接对象,管道默认情况下是双工的(双向的)
1 from multiprocessing import Process,Pipe
2
3 def f(child_conn):
4 child_conn.send('子进程')
5 child_conn.send([42, None, 'hello'])
6 print(child_conn.recv()) # 子进程接收父进程发送的信息,打印'数组'
7 child_conn.close()
8
9 if __name__ == '__main__':
10 parent_conn,child_conn = Pipe()
11 p = Process(target=f, args=(child_conn,))
12 p.start()
13 # 父进程接收子进程发送的信息
14 print(parent_conn.recv()) # 打印 '子进程'
15 print(parent_conn.recv()) # 打印 '[42, None, 'hello']'
16 parent_conn.send('数组') # 父进程给子进程发送信息
17 p.join()
Pipe方法返回的两个连接对象表示管道的两端。每个连接对象都有send()和recv()方法。请注意,如果两个进程(或线程)试图同时从管道的同一端读取或写入数据,则管道中的数据可能会损坏。当然,在同一时间使用管道的不同端不会有流程损坏的风险。
(3)Managers
Managers()返回的manager对象控制一个服务器进程,该进程保存Python对象,并允许其他进程使用代理操作它们。
1 from multiprocessing import Process,Manager 2 3 def f(dic,lis,n): 4 dic[n] = '1' 5 dic['2'] = 2 6 dic[0.25] = None 7 lis.append(n) 8 # print(lis) 9 10 if __name__ == '__main__': 11 # with Manager() as manager: 12 manager = Manager() 13 dic = manager.dict() 14 lis = manager.list(range(5)) 15 p_list = [] 16 for i in range(10): 17 p = Process(target=f, args=(dic,lis,i)) 18 p.start() 19 p_list.append(p) 20 for res in p_list: 21 res.join() 22 23 print(dic) 24 print(lis)
Manager()返回的管理器将支持类型list、dict、Namespace、Lock、RLock、Semaphore、BoundedSemaphore、Condition、Event、Barrier、Queue、Value和Array。
5、进程锁
1 from multiprocessing import Process,Lock
2
3 def f(l,i):
4 l.acquire()
5 print('hello world',i)
6 l.release()
7
8 if __name__ == '__main__':
9 lock = Lock()
10 p_list = []
11 for num in range(10):
12 p = Process(target=f, args=(lock,num))
13 p.start()
14 p_list.append(p)
15 for p in p_list:
16 p.join()
17 print('end')
6、进程池
在程序实际处理问题过程中,忙时会有成千上万的任务需要被执行,闲时可能只有零星任务。那么在成千上万个任务需要被执行的时候,我们就需要去创建成千上万个进程么?第一,创建进程需要消耗时间,销毁进程也需要消耗时间。第二,即便开启了成千上万的进程,因为CPU核心数有限,操作系统也不能让他们同时执行,这样反而会影响程序的效率。因此我们不能无限制的根据任务开启或者结束进程。那么我们要怎么做呢?
在这里,要给大家介绍一个进程池的概念。定义一个池子,在里面放上固定数量的进程,有需求来了,就拿一个池中的进程来处理任务,等到处理完毕,进程并不关闭,而是将进程再放回进程池中继续等待任务。如果有很多任务需要执行,池中的进程数量不够,任务就要等待之前的进程执行任务完毕归来,拿到空闲进程才能继续执行。也就是说,池中进程的数量是固定的,那么同一时间最多有固定数量的进程在运行。这样不会增加操作系统的调度难度,还节省了开关进程的时间,也一定程度上能够实现并发效果。
Python中的进程池使用multiprocessing模块的Pool类,主要方法如下:
1 apply(func [,args [,kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 2 '''需要注意的是:此操作并不会在所有的池工作进程中并执行func函数。如果要通过不同参数并发地执行func函数,必须从不同线程调用p.apply()函数或者使用apply_async()''' 3 4 apply_async(func [,args [,kwargs]]):在一个池工作进程中执行func(*args,**kwargs),然后返回结果。 5 '''此方法的结果是AsyncResult类的实例,callback是可调用对象,接收输入参数。当func的结果变为可用时,将回调函数传递给callback。callback禁止执行任何阻塞操作,否则将接收其他异步操作中的结果。''' 6 7 close():关闭进程池,防止进一步操作。如果所有操作持续挂起,它们将在工作进程终止前完成 8 9 join():等待所有工作进程退出。此方法只能在close()或teminate()之后调用
(1)进程池和多进程效率对比
1 import time,multiprocessing 2 def func(i): 3 i += 1 4 5 if __name__ == '__main__': 6 # 进程池 7 p = multiprocessing.Pool(5) 8 start = time.time() 9 p.map(func,range(100)) # 使用map函数循环调用func函数 10 p.close() # 不允许再向进程池中添加任务 11 p.join() 12 print(time.time()-start) # 0.21729111671447754 13 # 多进程 14 start = time.time() 15 p_list = [] 16 for i in range(100): 17 # 多进程调用func函数 18 p = multiprocessing.Process(target=func,args=(i,)) 19 p.start() 20 p_list.append(p) 21 for p in p_list: 22 p.join() 23 print(time.time()-start) # 3.7114222049713135
可以看到使用进程池只用了0.21秒,而使用多进程则使用了3.7秒之多,这是因为进程池只用了5个进程,而多进程则使用了100个进程。多进程调度100个进程比进程池中调度5个进程更耗时且更耗资源。
(2)进程池的同步/异步调用
同步:串行
1 import multiprocessing,os,time
2 def func(i):
3 print('%s run'%os.getpid())
4 time.sleep(1)
5 i += 1
6
7 if __name__ == '__main__':
8 # 进程池
9 p = multiprocessing.Pool(5)
10 for i in range(20):
11 p.apply(func,args=(i,)) # 同步提交,串行执行
异步:并行
1 import time,multiprocessing
2 def func(i):
3 time.sleep(1)
4 i += 1
5 print(i)
6
7 if __name__ == '__main__':
8 # 进程池
9 p = multiprocessing.Pool(5)
10 for i in range(20):
11 p.apply_async(func, args=(i,)) # 异步提交,并行执行
12 p.close() # 不允许再向进程池中添加任务,close()必须在join()前面
13 # 使用异步提交的任务,必须添加join()
14 p.join() # 等待子进程结束再往下执行,否则主进程结束了子进程还没执行完
15 print('end')
(3)接收进程池调用函数的返回结果
方法一:
1 import time,multiprocessing
2
3 def func(i):
4 time.sleep(1)
5 i += 1
6 return i
7
8 if __name__ == '__main__':
9 # 进程池
10 p = multiprocessing.Pool(5)
11 res_l = []
12 for i in range(20):
13 res = p.apply_async(func,args=(i,)) # 异步提交
14 # print(res.get()) # 阻塞,等待任务结果
15 res_l.append(res) # 返回结果之后,将结果放入列表,归还进程,之后再执行新的任务
16 # 需要注意的是,进程池中的三个进程不会同时开启或者同时结束,而是执行完一个就释放一个进程,这个进程就去接收新的任务
17 p.close() # 不允许再向进程池中添加任务,close()必须在join()前面
18 p.join() # 等待子进程结束再往下执行,必须添加join(),否则主进程结束了子进程还没执行完
19 for i in res_l:
20 print(i.get()) # 使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get
21 print('end')
方法二:
1 from multiprocessing import Process,Pool
2 import time
3
4 def Foo(i):
5 time.sleep(2)
6 return i + 100
7
8 def Bar(arg): # 回调函数是在主进程中完成的,直接接收子进程中函数的返回值,不能传另外的参数
9 print('----->exec done:',arg)
10
11 if __name__ == '__main__':
12 pool = Pool(5) # 允许进程池里同时放入5个进程
13 for i in range(10):
14 pool.apply_async(func=Foo, args=(i,),callback=Bar) # 并行执行,Bar函数接收Foo函数的返回结果,callback回调执行者为主进程
15 pool.close()
16 pool.join() # 进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭
17 print('end')
(4)爬虫实例
1 import multiprocessing,requests
2
3 def get_url(url):
4 res = requests.get(url)
5 return {'url':url,
6 'status_code':res.status_code,
7 'content':res.text}
8
9 def parser(dic):
10 print(dic['url'],dic['status_code'],len(dic['content']))
11
12
13 if __name__ == '__main__':
14 url_list = ['http://www.baidu.com',
15 'http://www.hao123.com',
16 'http://www.163.com',
17 'http://www.csdn.com']
18 p = multiprocessing.Pool(4)
19 res_l = []
20 for url in url_list:
21 p.apply_async(get_url,args=(url,),callback=parser)
22 p.close()
23 p.join()
24 print('END!!')
七、多线程、多进程总结
1、多线程:
多用于IO密集型行为(上传/下载)
2、多进程
多用于CPU密集型任务(计算/排序)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号