MySQL高级学习之索引
索引
什么是索引?
MySQL 官方对索引的定义为: 索引(Index) 是帮助 MySQL 高效获取数据的数据结构。 可以得到索引的本质:索引是数据结构。 可以简单理解为排好序的快速查找数据结构。 在数据之外, 数据库系统还维护着满足特定查找算法的数据结构, 这些数据结构以某种方式引用(指向) 数据,这样就可以在这些数据结构上实现高级查找算法。 这种数据结构, 就是索引。 下图就是一种可能的索引方式示例:
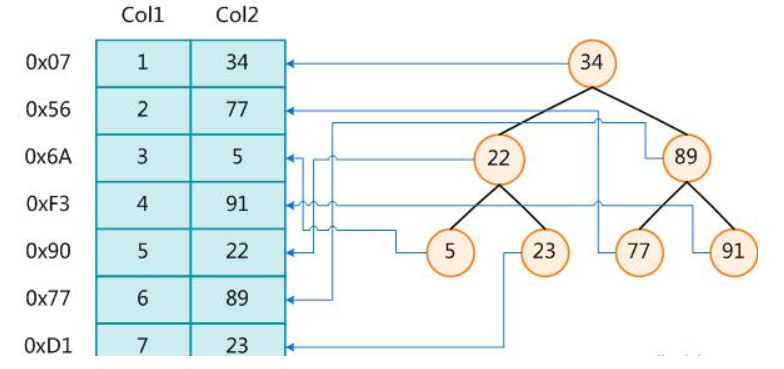
左边是数据表, 一共有两列七条记录, 最左边的是数据记录的物理地址。 为了加快 Col2 的查找, 可以维护一个右边所示的二叉查找树, 每个节点分别包含索引键值和一个指向对应数据记录物理地址的指 针, 这样就可以运用二叉查找在一定的复杂度内获取到相应数据, 从而快速的检索出符合条件的记录。一般来说索引本身也很大, 不可能全部存储在内存中, 因此索引往往以索引文件的形式存储的磁盘上。
优缺点
优点:
- 提高数据检索的效率,降低数据库的IO成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗
缺点:
- 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE,因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
- 实际上索引也是一张表,该表保存了主键与索引字段,并指向了实体表的记录,所以索引列也是要占用空间的。
索引分类
-
单值索引:一个索引只包含单个列,一个表可以有多个单列索引
-
唯一索引:索引列的值必须唯一,但允许有空值
-
主键索引:设定为主键后会自动建立索引,InnoDB为聚簇索引
-
复合索引:即一个索引包含多个列
-
全文索引: 通过建立
倒排索引,可以极大的提升检索效率,解决判断字段是否包含的问题. 例如: 有title字段,需要查询所有包含 "政府"的记录. 需要 like "%政府%"方式查询,查询速度慢,当查询包含"政府" OR "中国"的需要是,sql难以简单满足.全文索引就可以实现这个功能.倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
建索引语句:
CREATE INDEX idx_customer_name ON customer(customer_name); # 单值索引
CREATE UNIQUE INDEX idx_customer_no ON customer(customer_no); # 唯一索引
ALTER TABLE customer add PRIMARY KEY customer(customer_no); # 单独创建主键索引
ALTER TABLE customer drop PRIMARY KEY ; # 删除主键索引 主键索引一般随着建表语句而设置
CREATE INDEX idx_no_name ON customer(customer_no,customer_name);# 复合索引
create fulltext index content_tag_fulltext on fulltext_test(content,tag); # 全文索引
alter table fulltext_test add fulltext index content_tag_fulltext(content,tag);#全文索引
索引的创建时机
适合创建索引的情况
- 主键自动创建唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系应该建立索引
- 单键/组合索引的选择问题,组合索引性价比更好
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
不适合创建索引的情况
- 表记录太少
- 频繁更新的字段或表
- where条件里用不到的字段不用建索引
- 过滤性不好的不适合建立索引
B-Tree与B+Tree
笔者认为自己目前水平有限,没有完全理解,所以找了两篇不错的博客,后续有时间的话会更新。

