MySQL高级学习之MySQL架构与SQL加载顺序
MySQL学习笔记(第一天)
参考文章:
MySQL为什么不用数组、哈希表、二叉树等数据结构作为索引呢
一、 MySQL的逻辑架构
连接层:最上层是一些客户端和连接服务, 包含本地 sock 通信和大多数基于客户端/服务端工具实现的类似于 tcp/ip 的
通信。 主要完成一些类似于连接处理、 授权认证、 及相关的安全方案。 在该层上引入了线程池的概念, 为通过认证
安全接入的客户端提供线程。 同样在该层上可以实现基于 SSL 的安全链接。 服务器也会为安全接入的每个客户端验
证它所具有的操作权限。
服务层:第二层主要完成核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化以及部分内置函数的执行。所有跨存储引擎的功能也在这一层实现,如过程,函数等,在该层,服务器会解析并创建相应的内部解析树,并对其完成相应的优化如确定查询表的顺序,是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还有查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中可以很好的提高系统的性能。
| Management Serveices & Utilities | 系统管理和控制工具 |
|---|---|
| SQL Interface: | SQL 接口。 接受用户的 SQL 命令, 并且返回用户需要查询的结果。 比如 select from 就是调用 SQL Interface |
| Parser | 解析器。 SQL 命令传递到解析器的时候会被解析器验证和解析 |
| Optimizer | 查询优化器。 SQL 语句在查询之前会使用查询优化器对查询进行优化, 比如有 where 条件时, 优化器来决定先投影还是先过滤。 |
| Cache 和 Buffer | 查询缓存。 如果查询缓存有命中的查询结果, 查询语句就可以直接去查询缓存中取 数据。 这个缓存机制是由一系列小缓存组成的。 比如表缓存, 记录缓存, key 缓存, 权限缓存等 |
引擎层:存储引擎层, 存储引擎真正的负责了 MySQL 中数据的存储和提取, 服务器通过 API 与存储引擎进行通信。 不同
的存储引擎具有的功能不同, 这样我们可以根据自己的实际需要进行选取。
存储层:数据存储层, 主要是将数据存储在运行于裸设备的文件系统之上, 并完成与存储引擎的交互。
二、存储引擎
show engines: 查看所有的数据引擎。
show variables like '%storage_engine%' 查看默认的数据库引擎 。
| 对比项 | MyIASM | InnoDB |
|---|---|---|
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,即使操作一条记录也会锁住整个表, 不适合高并发的操作 | 行锁,操作时只锁某一行, 不对其它行有影响, 适合高并发的操作 |
| 缓存 | 只缓存索引, 不缓存真实数据 | 不仅缓存索引还要缓存真实数据, 对内存要求较高, 而且内 存大小对性能有决定性的影响(MySQL8已删除) |
| 关注点 | 读性能 | 并发写、事务、资源 |
| 默认安装 | Y | Y |
| 默认使用 | N | Y |
| 自带系统表使用 | Y | N |
三、SQL加载顺序
手写SQL顺序
select <select_list>
from <table_name>
<join_type> join <join_table> on <join_condition>
where <where_condition>
group by <group_by_list>
having <having_condition>
order by <order_by_condition>
limit <limt_number>
MySQL执行顺序
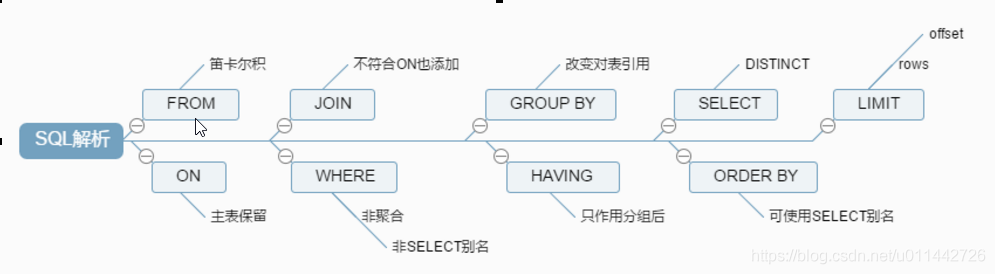
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
-
加载from子句的前两个表计算笛卡尔积,生成虚拟表vt1;
-
筛选关联表符合on表达式的数据,保留主表,生成虚拟表vt2;
-
如果使用的是外连接,执行on的时候,会将主表中不符合on条件的数据也加载进来,做为外部行
-
如果from子句中的表数量大于2,则重复第一步到第三步,直至所有的表都加载完毕,更新vt3;
-
执行where表达式,筛选掉不符合条件的数据生成vt4;
-
执行group by子句。group by 子句执行过后,会对子句组合成唯一值并且对每个唯一值只包含一行,生成vt5,。一旦执行group by,后面的所有步骤只能得到vt5中的列(group by的子句包含的列)和聚合函数。
-
执行聚合函数,生成vt6;
-
执行having表达式,筛选vt6中的数据。having是唯一一个在分组后的条件筛选,生成vt7;
-
从vt7中筛选列,生成vt8;
-
执行distinct,对vt8去重,生成vt9。其实执行过group by后就没必要再去执行distinct,因为分组后,每组只会有一条数据,并且每条数据都不相同。
-
对vt9进行排序,此处返回的不是一个虚拟表,而是一个游标,记录了数据的排序顺序,此处可以使用别名;
-
执行limit语句,将结果返回给客户端
补充:
on和where的区别?
简单地说,当有外关联表时,on主要是针对外关联表进行筛选,主表保留,当没有关联表时,二者作用相同。
例如在左外连时,首先执行on,筛选掉外连表中不符合on表达式的数据,而where的筛选是对主表的筛选。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号