python接口自动化4-常用取token值方法
前言
在接口测试中我们经常是需要一个登陆token,或者获取其他用到的参数来关联下一个接口用到的参数。这里介绍一些本人常用的方法。
一、简介
不过在哪里我们也是能实现自动化api测试的,我们都知道token一般都会在这几个地方:
1.返回参数的token;
2.返回头部信息中;
3.上一个页面中;
二、取 token 常用方法
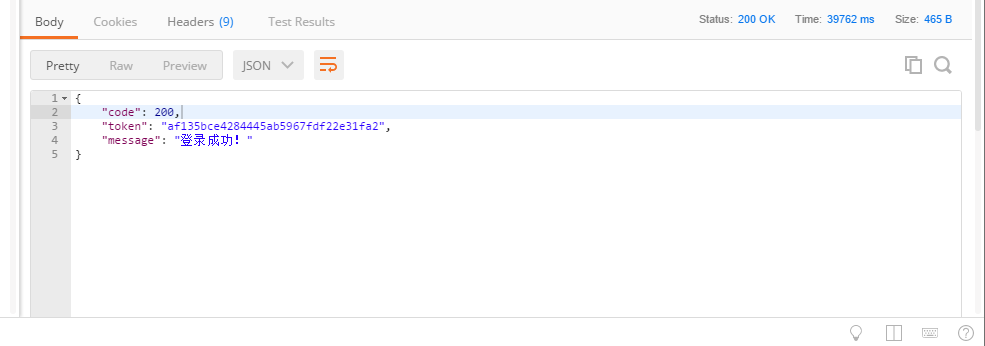
1.在返回参数中,如json:
R_json = { "code": 200, "message": "登录成功", "token": "ef135bce4284s45ab5967fdf22e81fa2" } print(R_json["token"])
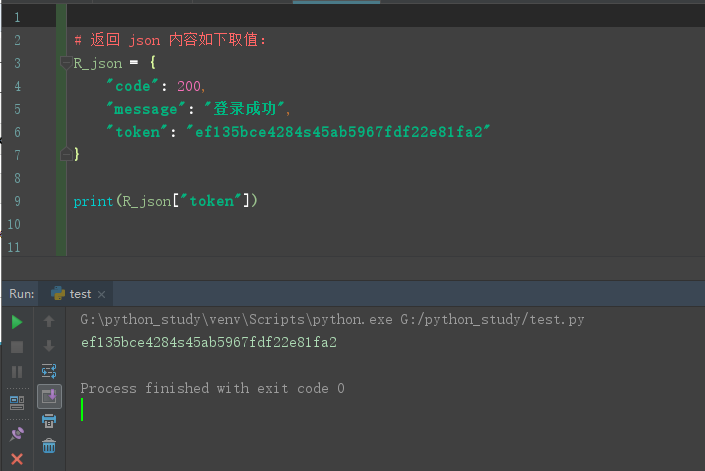
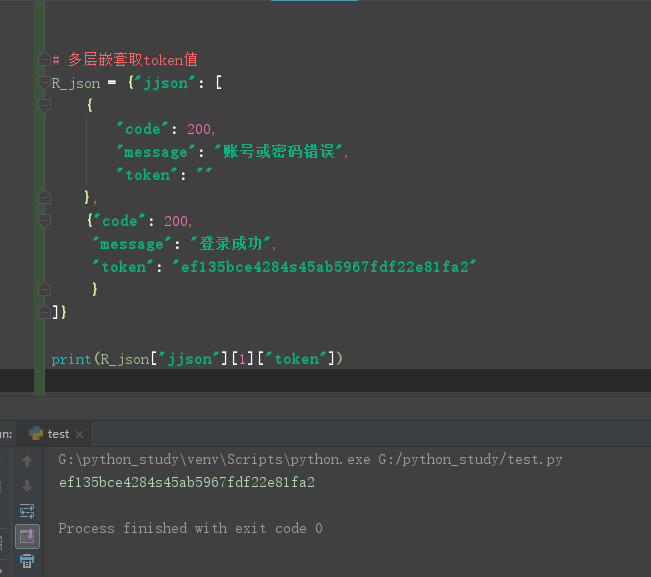
2.在返回参数中还有,json嵌套list、json:

# 多层嵌套取token值 R_json = {"jjson": [ { "code": 200, "message": "账号或密码错误", "token": "" }, {"code": 200, "message": "登录成功", "token": "ef135bce4284s45ab5967fdf22e81fa2" } ]} print(R_json["jjson"][1]["token"])
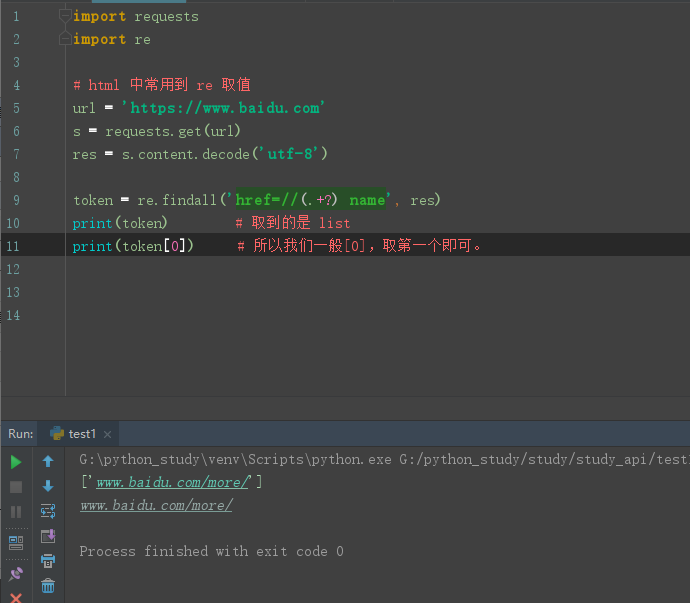
3.在返回参数中,是html或者是raw文本显示的我们可以通过正则取到值:
常用的正则有以下三种:
①取中间:xxx(.+?)xxx
②取后面:xxx(.+?)$
③取前面:^(.+?)xxx
import requests import re # html 中常用到 re 取值 url = 'https://www.baidu.com' s = requests.get(url) res = s.content.decode('utf-8') token = re.findall('href=//(.+?) name', res) # 取中间 print(token) # 取到的是 list print(token[0]) # 所以我们一般[0],取第一个即可。
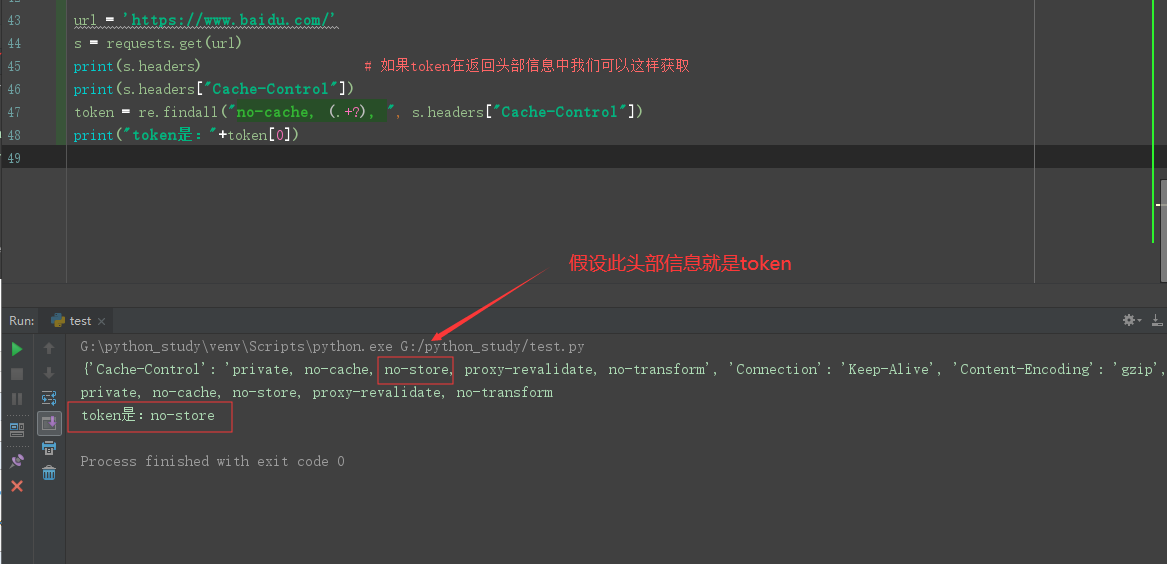
4.在响应头部中
url = 'https://www.baidu.com/' s = requests.get(url) print(s.headers) # 如果token在返回头部信息中我们可以这样获取 print(s.headers["Cache-Control"]) token = re.findall("no-cache, (.+?), ", s.headers["Cache-Control"]) print("token是:"+token[0])
看到了此,是不是觉得re正则还是很实用的呢?赶紧去随便请求个接口拿到一个你想要的值吧!!!
欢迎来QQ交流群:482713805
分类:
0-python-apiAuto
标签:
python-apiAuto


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人