分布式并行计算MapReduce
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
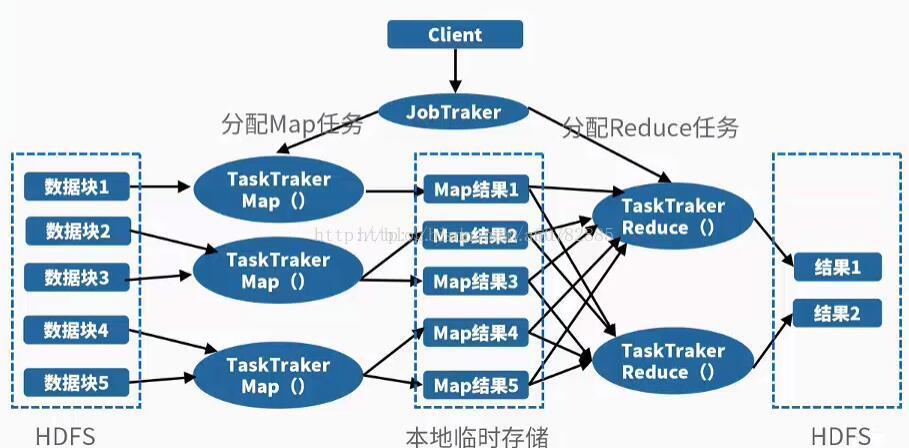
也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是<key,value>的形式。HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
首先我们需要先知道几个小概念:
1.job 2.task 3.jobTracker 4.taskTracker
job:在Hadoop内部,用Job来表示运行的MapReduce程序所需要用到的所有jar文件和类的集合,>这些文件最终都被整合到一个jar文件中,将此jar文件提交给JobTraker,MapReduce程序就会执行。
task:job会分成多个task。分为MapTask和ReduceTask。
jobTracker:管理节点。将job分解为多个map任务和reduce任务。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过
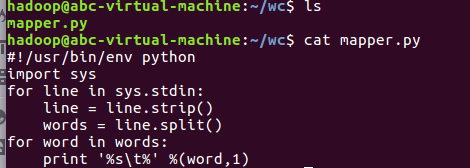
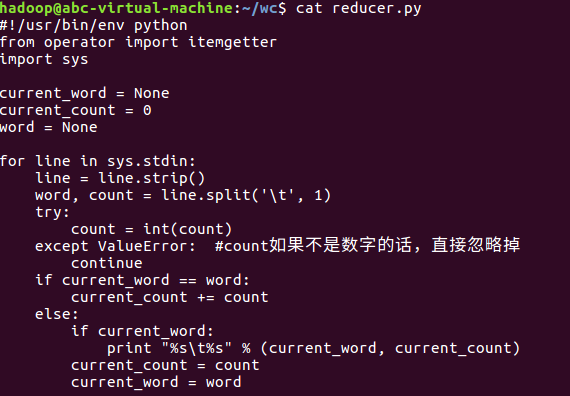
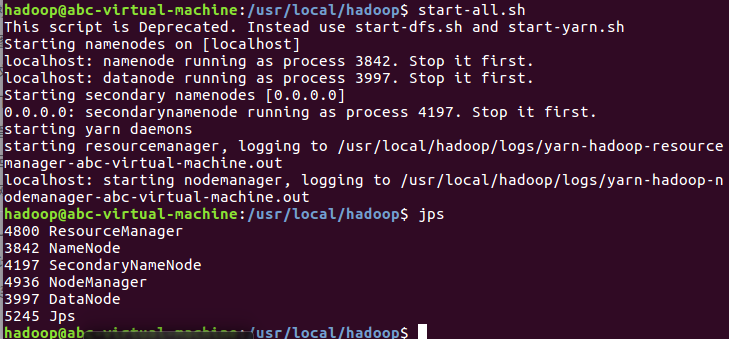
3)启动Hadoop:HDFS, JobTracker, TaskTracker
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
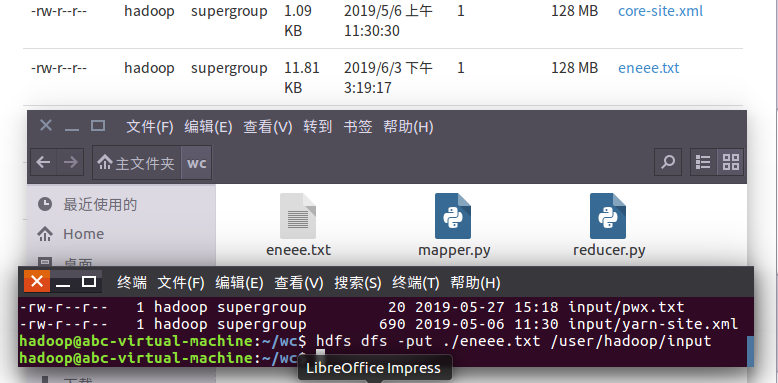
5)streaming的jar文件的路径写入环境变量,让环境变量生效

6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh

7)source run.sh来执行mapreduce
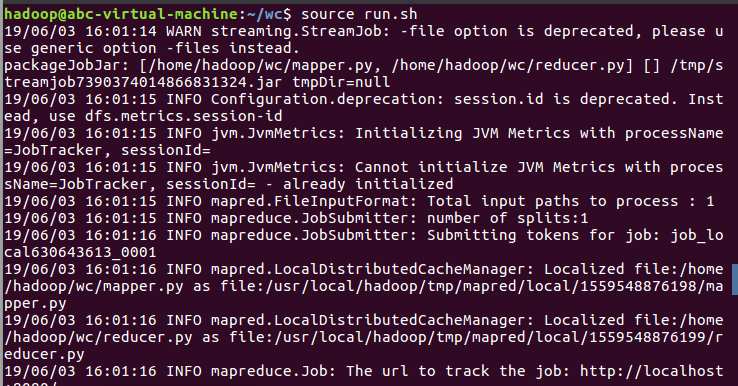
8)查看运行结果

每位同学准备不一样的大一点英文文本文件,每个步骤截图交上博客上。
上述步骤测试通过之后,可以尝试对文本做处理之后再统计次数,如标点符号、停用词等。
有能力的同学尝试对之前爬虫爬取的文本,在Hadoop上做中文词频统计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号