
语音合成 - 什么是语音合成?
2. PSOLA算法
3. 基于HMM的参数合成
4. 未来有哪些趋势?
(本系列时常补充和纠错)
1.1 什么是语音合成?
语音识别是最近几年很火的一个词,也是一个应用到生活中各种方面的一个技术。比如说经常使用的语音输入,微信的语音转文字,科大讯飞的语音翻译,手机的语音助手,智能音箱。这些东西都使用了语音识别技术,通俗来说,语音识别技术,就是用户输入一段语音,系统负责将语音转换成文字。
语音合成则是一个相反的过程,语音合成要求用户输入一段文字,系统负责将文字转换成一段流畅自然的语音。其实,语音合成在生活中的应用也是随处可见,只是我们有时候会将其忽略。比如车辆的报站系统,手机语音助手的语音回答,电子书的自动朗读等等。总之,生活中我们遇到的大多数让机器发出声音的场景,都使用的语音合成技术。
1.2 语音合成是怎么做到的?
这里以其中一种典型的方法(拼接方法)做一个介绍。
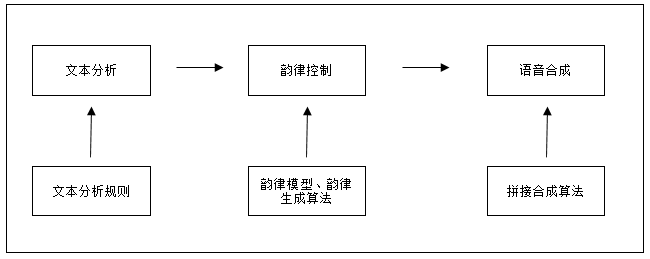
图 1 : 拼接合成示意图
在统计合成出现之前,语音合成技术大多是使用拼接合成。图中上面三个框图是拼接合成的三个步骤,下面三个框图是三个步骤使用的技术。
文本分析的目的是找出文本中的停顿和重音等。语音合成的输入是一段文本,人类可以很快速的判断出一段文本哪里需要停顿,哪里需要重音,但是机器不知道。因此需要使用文本分析规则进行文本分析,让机器知道文本中的重音和停顿,也让机器知道文本中那些汉字组成一个词,那些汉字组成了一句话。下一步就需要依据文本从语音库挑选出适合的语音波形。这里需要介绍一下语音库,语音库中存储的是一个个音节的发音,而这些音节的发音全部来自对自然语音的切分,切分后对这些发音进行标注(包括发音记号、清浊音切分等等),有时候为了得到更加理想的合成效果,语音库中会存储同一发音记号对应的多个不同韵律的发音(比如不同音调、不同情感)。
韵律控制则是为了实现对合成语音中的韵律调整。理想中的合成语音,是有着丰富韵律的,比如有的要重音,有的要低沉,而不是像机器人一样呆板而平稳的发音。这里的韵律控制主要是修改单个语音波形的时长和音调,以达到韵律控制的目的。使用的主要算法是基音同步叠加(PSOLA)算法。
韵律调整好之后,下一步就是要把这些波形拼接起来,使之成为连续语音。这里需要注意的问题是,波形的拼接处,那面出现波形的突变:形成音量或者静音段和有声段的突然转变,出现“咔哒咔哒”的噪声,影响合成效果。因此这里需要使用平滑算法,减少这些现象的影响。

