kaldi学习 - egs/yesno —— 数据准备(二)
参考文档:http://www.cnblogs.com/welen/p/7485151.html
写在前面,本文虽然对大多数脚本进行了解释,但只是初学者的理解,如果你认为读起来不知所云,建议从 kaldi 官方文档 读起,两边配合理解,可以解决很多看起来好像很难理解的东西。(官方文档地址: http://www.kaldi-asr.org/doc/data_prep.html )
今天为止,/rgs/yesno/ 实例的数据准备阶段的脚本终于基本看完了,你我很忙,“知识不慌张”。学习总是一件很有成就感的事情。再次提醒,当你阅读中文文档和博客感到抓狂的时候,不防看看 kaldi 官方文档,可能需要一些时间去学会怎样寻找自己需要的东西,但是学习不就是一个从无到有的过程吗,向来如此。
run.sh 是整个实例的顶层调用脚本,可以看到清晰的处理脉络。上一篇(http://www.cnblogs.com/gstblog/p/8933797.html)当中,主要是对脚本的prepare_data进行了学习,包含了脚本文件中涉及到的其他脚本文件,今天继续往下学习
local/prepare_dict.sh
utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang
路径: kaldi-trunk/egs/yesno/s5
运行: ./run.sh
目前代码:
#!/bin/bash train_cmd="utils/run.pl" decode_cmd="utils/run.pl" if [ ! -d waves_yesno ]; then wget http://www.openslr.org/resources/1/waves_yesno.tar.gz || exit 1; # was: # wget http://sourceforge.net/projects/kaldi/files/waves_yesno.tar.gz || exit 1; tar -xvzf waves_yesno.tar.gz || exit 1; fi train_yesno=train_yesno test_base_name=test_yesno rm -rf data exp mfcc # Data preparation local/prepare_data.sh waves_yesno local/prepare_dict.sh utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang local/prepare_lm.sh
1. local/prepare_dict.sh
prepare_dict 用于数据准备阶段的字典准备,创建了 data/local/dict 目录,并创建了里面必要的文件。字典主要是为了罗列出 单词和发音的对应关系,方便后面训练模型和测试数据使用,里面的文件各司其职,有的负责对应单词和发音,有的负责存储非语言学发音(静音,噪声,笑声等,但是这个例子里面只有 SIL(silence))。
data/local/dict 里面的文件包括:

其中,各个文件解释如下
lexicon.txt: 发音字典文件,里面内容形式是 <word> - <utterance>, 左边一列是单词,右边一列是对应的发音 。这里发音用 Y , N ,SIL 表示

lexiconp.txt: 也是发音字典文件,只不过它添加了对应的发音概率。在这里为了方便处理,这里其实把所有的发音概率都设为了1,而不是左右的概率加起来等于1。第二列就是概率。

其他的文件则专门分别记录的单词的发音,静音,非静音等等信息
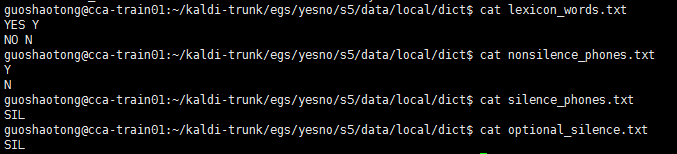
prepare_dict.sh 代码如下:
#!/bin/bash #==== # create directory saving dict files #==== mkdir -p data/local/dict #==== # copy some files form input # SIL means silence # lexicon.txt, 完整的词位-发音对 # lexiconp.txt, 完整的词位-发音概率-发音 # lexicon_words.txt, 单词-发音对 # silence_phones.txt, 非语言学发音(静音,噪音,笑声等) # nonsilence_phones.txt, 语言学发音 # optional_silence.txt , 备选非语言发音 #==== #==== # grep: 查找指令 ,-v选项表示反向查找, # 第三行代码意思是,查找phones.txt的内容, 凡是不含 SIL 的行,会被重定向输出 ( > )到 nonsilence_phones.txt #==== cp input/lexicon_nosil.txt data/local/dict/lexicon_words.txt cp input/lexicon.txt data/local/dict/lexicon.txt cat input/phones.txt | grep -v SIL > data/local/dict/nonsilence_phones.txt echo "SIL" > data/local/dict/silence_phones.txt echo "SIL" > data/local/dict/optional_silence.txt echo "Dictionary preparation succeeded"
2. utils/prepare_lang.sh --position-dependent-phones false data/local/dict "<SIL>" data/local/lang data/lang
上面是一条带有命令行参数的指令,--position-dependent-phones 是命令选项,这里赋值为false,后面四项是prepare_lang.sh 的四个参数。参数解释如下:
utils/prepare_lang.sh <input_dir> <oov> <temperary_dir> <output_dir>
oov: 数据集之外的单词,会映射到这里;
<temperary_dir>:仅仅就是一个临时文件,不需要过多关注;
<output_dir>: 这个目录是真正的数据的输出目录
命令选项 --position-dependent-phones 与词位信息有关,默认值是 true,这时候会使用词位信息 _B _E _I _S ,表示开始,结束,词中,单个词。
具体的可以在 yesno/s5/utils/prepare_lang.sh中找到。还有一些其它选项也在这个文件里面。
在这个例子当中,预料信息很少,全部都是孤立词,所以把这个选项设为false。
在上一条指令 ./local/prepare_dict 中,我们搞定了一些词典信息,但是kaldi处理数据需要专门的数据结构 fst(Finite Satte Transducers,有穷状态转换器),具体可以参考网上资料,以及官方文档。而这一条指令,就是创建 /dict/lang 目录,保存这些信息。
3. /data/lang 里面有什么
刚刚说了 prepare_lang.sh 创建了 /data/lang 目录,完成了从普通数据结构(人能够读懂的数据结构)到特定格式(fst格式)的转换,那么这个目录里到底有什么?这些文件有什么内容呢?所谓的特定的格式是什么样的?分析一下。
3.1 有什么?
看一下里面打底有哪些文件,还有一个phone目录,也一并展示
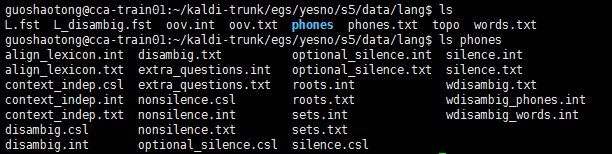
3.2 是什么内容
先看看 /dict/lang 下面的几个文件
3.2.1 phone.txt 和 words.txt
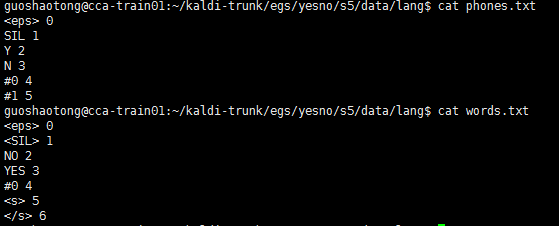
这两个文件分别存储了 音素与整数的映射,单词与整数的映射,从这里就可以看出 数据准备阶段一开始数据结构与FST格式的不同。
3.2.2 L.fst
这是一个 fst 格式的发音词典,输入是音素,而输出是词。
3.2.3 L_disambig.fst
这也是一个 fst 格式的发音词典,只是在这个文件当中,添加了消除歧义的符号,比如#1,#2,以及自循环符号 #0。
3.2.4 oov.txt
这个文件里面存储了一些符号,所有ooV词(词表之外的词,out of vocabulary)都会被映射为这个符号。
3.2.5 topo
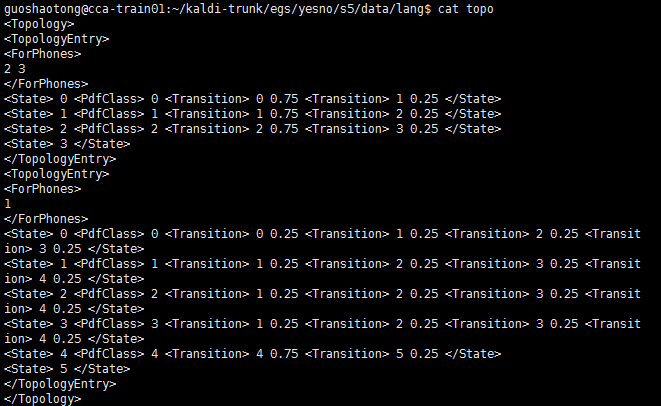
这个文件里面存储了我们后将要用到的 HMM 模型的拓扑模型,可以看到有两部分,第一部分 <ForPhones></ForPhones> 之间的数字是 2,3 ,是发音的编号指的是 YES, NO ,这个可以从 phones.txt 找到,自然 下面一部分 的数字 1 指的是SIL。 YES,NO 公有3种状态,SIL有五种状态,它们各自状态之间的转移以及转移概率则是每一行<Transition> state probability 指定。
3.2.6 phones/*
phones 目录下的文件很明显有一个特点,每一个文件都有3个,但是他们的后缀名都不一样,同名不同后缀的文件,其实有着完全一样的内容,只是他们各自存储信息的格式是不同的。这里用 nonsilence.* 举例子

这里,context_indep.* 存储了上下文无关的信息。nonsilence.* silence.* optional_silence.*存储了音素信息。extra_question.*存储的是一些额外的信息,主要是和音调和重音之类的信息有关。disambig.* 则存储了一些消除歧义使用的符号,在前面已经见过,比如#0, #1等等。roots.# 可以提供建立上下文决策树的信息。set.* 包含了一系列的因素集,一般是将同一个音素(有时候会包含词位信息 _B _E)存储在同一行,聚类使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号