
【Kafka入门】Kafka入门第一篇:基础概念篇
Kafka简介
Kafka是一个消息系统服务框架,它以提交日志的形式存储消息,并且消息的存储是分布式的,为了提供并行性和容错保障,消息的存储是分区冗余形式存在的。
Kafka的架构
Kafka中包含以下几种专业术语:
1. topic:Kafka中以topic的形式来保存不同类别的消息
2. producer:Kafka中发布消息的称为producer
3. consumer:Kafka中订阅topic的进程称为consumer
4. broker:Kafka运行在由一个或多个服务(器)组成的集群上,每一个服务(器)称为一个broker。
具体的架构如下:
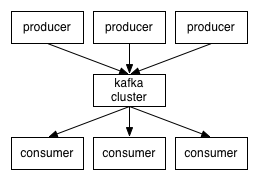
从架构图可以看出,producers通过网络将消息发布到Kafka上,然后消息以分区冗余的topic形式存储在分布式的Kafka服务集群上,最后consumers订阅不同的topic消息进行消费。其中客户端和服务器间是通过TCP协议进行通信。
topic(话题)
topic是已经发布的消息的一个分类名称,Kafka以分区(partition)日志的形式存储topic,也就是说,每个topic会被分成不同的partition,不同partition的关系如下:
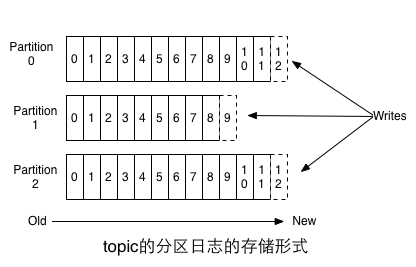
每个分区都是有序的不可变的消息序列,这些消息序列以追加形式写到提交日志上去。我们可以看到,在每个分区内,每条消息都被分配了一个下标号(offset),这些有序的下标号用以在不同partiton中唯一确定消息的位置。
消息在Kafka上的存储时间是可配置的,在配置时间范围内,消息是可以随时被消费,但是从消息发布时间开始计算,一旦配置的时间过了,为了腾出更多的空间,消息将会被丢弃。
consumer是如何知道自己要消费的消息在那个位置呢?由于每个消息被赋予了在partition中的唯一下标,所以在每个consumer上只需要维护的消息在日志中的下标位置即可。consumer可以通过控制下标来读取不同的消息。consumer的这种轻量设计方便了consumer的扩展,某个consumer的去留不会影响集群。
将日志分区的目的可以归纳如下:
1. 日志分区可以避免太大的日志无法存储的问题,单个服务器上的容量有限。
2. 以日志存储的topic这样可以拥有任意多的分区,从而不会对topic的大小有限制。
3. 日志分区存储对后期的并行消费和消息的容错有很大的帮助。
topic的分布式存储和分布式的服务请求
日志的分区被分布式存储到不同的server上,当然,为了容错,每个partition可以配置一个冗余的份数。对于每一个partition,多份冗余的partition所在的server中只能有一个为leader,其他的都是follower。在读写操作中,都由partition的leader去接受读写请求,而其他的follower被动的去复制leader来保证消息的一致性。这样在以后如果partition的leader的服务如果挂了,这些follower可以被选举为leader继续提供读写服务。集群中的每个server都同时承担着leader和follower的角色,所以在处理请求的负载上也相对均衡。
producer(消息生产者)
producer将消息发布到它指定的topic中,并负责决定发布到topic的哪个分区。通常由round-robin的形式或者通过一些分区函数(基于消息中的一些key)来保证负载均衡。就像hadoop中的shuffle类似,所以第二种方式用的相对较多。
consumer(消息消费者)
传统的消息发布模式有两种:队列模式和订阅发布模式。队列模式中,consumer池中的consumer从server从读取消息,每条消息被一个consumer读取。订阅发布模式中每条消息被广播到所有的consumer。而Kafka综合了这两者,提供了一种consumer group(消费组)的概念。
有了消费组的概念,每个consumer可以将自己标记为所属的组,这样,Kafka将会将消息传输到订阅组的一个consumer实例(可以是一个consumer进程或者一台跑有consumer服务的机器)上,注意,这里不是将消息传给订阅组的所有consumer实例。
在这种消费组的概念下,如果每个消费组只有一个consumer实例,那和传统的订阅发布模式一样,如果所有的consumer都在一个组内,则和传统的队列模式一样。
更常见的是,每个topic都有若干数量的consumer组,每个组都是一个逻辑上的“订阅者”,为了容错和更好的稳定性,每个组由若干consumer组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个consumer。消息订阅组和Kafka集群的关系如下图:
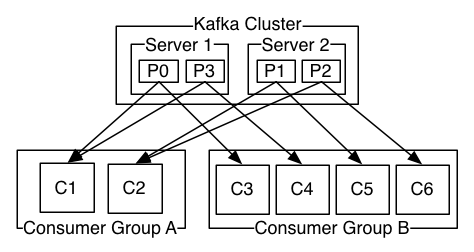
相比传统的消息系统,Kafka在消息有序性上的保障性更强。传统的消息系统在有序性和并发性上不能做到很好的互补兼容,传统的消息系统没有分区的概念,消息在队列中有序存储,但是在多个consumer消费消息时,虽然消息是顺序分发的,但是由于消息的异步传输,最后并不能保证有序性(不理解这句话),然而,如果只让一个consumer去消费消息,又失去了并发性。但是Kafka通过分区的概念解决了这个难题,在Kafka中,每个分区只可以被分发到一个消费组中的一个consumer,这样保证了消息消费的有序性,由于一个topic有多个分区,所以并发性上也有保证。注意:在一个消费组中的consumer数量不能超过分区的数量(不理解为什么?)。
还有一个要注意的,Kafka的有序性是指单个partition内的,并不是全局的有序性,但是这已经能满足多数应用的需求,如果要保证全局有序,则只能拥有一个partition。
Kafka消息系统的几点保障
1. producer往指定topic的一个partition写消息时,消息被提交到partition中的顺序和producer发送的顺序严格一致。
2. consumer实例看到的消息的顺序和其在partition中存储的顺序一致。
3. 对于冗余数为N的topic,在不影响消息丢失的情况下,系统最多可以容忍N-1个服务失败。
转载请注明:http://www.cnblogs.com/gslyyq/
