
转:浅谈高性能数据库集群: 分库分表
https://www.toutiao.com/i6573966496777634312/
本文主要介绍高性能数据库集群分库分表相关理论,基本架构,涉及的复杂度问题以及常见解决方案。
分库分表概述
基本思想:
把一个数据库切分成多个部分放到不同的数据库服务器(server)上,从而缓解单一数据库的性能问题。
单台数据库的瓶颈:
- 数据量太大,读写性能下降,即使有索引,索引变的很大,性能同样下降;
- 数据文件变的很大,数据库的备份和恢复需要消耗很长时间;
- 数据文件越大,极端情况下丢失数据的风险越高;
读写分离分散数据库读写操作压力,分库分表分散存储压力
适用场景
分库分表是在确定没有其他优化空间之后,才采取的方案;
优化顺序:
- 硬件优化;
- 数据库调优,例如增加索引,优化慢查询;
- 引入缓存,减少数据库压力;
- 程序与数据库表优化、重构;
- 读写分离或分库分表;
类似读写分离,分库分表也是确定没有其他优化空间之后才采取的优化方案。那如果业务真的发展很快岂不是很快要进行分库分表了?那为何不一开始就设计好呢?
按照架构设计的“三原则”(简单原则,合适原则,演化原则),简单分析一下:
首先,这里的“如果”事实上发生的概率比较低,做10个业务有一个业务能活下去就很不错了,更何况快速发展,和中彩票的概率差不多。如果我们每个业务上来就按照淘宝、微信的规模去做架构设计,不但会累死自己,还会害死业务。
其次,如果业务真的发展很快,后面进行分库分表也不迟。因为业务发展好,相应的资源投入就会加大,可以投入更多的人和更多的钱,那业务分库带来的代码和业务复杂问题就可以通过加人来解决,成本问题也可以通过增加资金来解决。
业务分库
业务分库的基本思想:
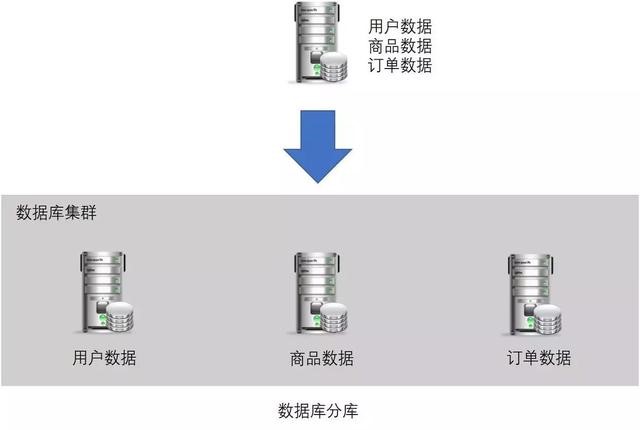
按照业务模块将数据将数据分散到不同的数据库服务器。
分库带来的问题:
1、join操作
问题:数据库分散在不同的数据库中,无法做join查询。
解决:通过业务代码进行join查询,然后结果合并。
2、事务
问题:表分散在不同的数据库中,无法通过事务统一修改。
解决:通过业务代码实现。
3、成本
服务器成本、开发成本。
业务分库示意图:
业务分表
业务分表的基本思想:
将单表切分成多个不同的表。
业务分表的拆分方式:
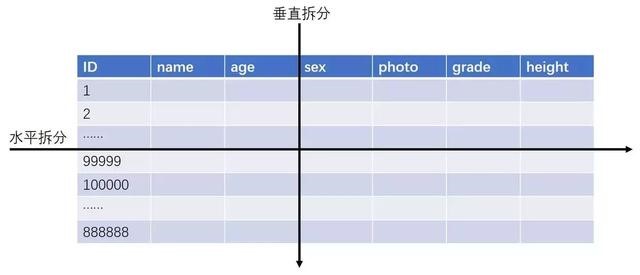
1、垂直拆分:基于列字段进行拆分,拆分后的表结构不一样。
2、水平拆分:基于数据记录进行拆分,拆分后的表结构一样。
业务分表示意图:
带来的问题
1、垂直分表:
增加表操作的次数
2、水平分表
路由问题:
某条数据具体属于哪个切分得到子表,需要增加路由算法进行计算,这个算法会导致一定的复杂性。
解决方案:
1、范围路由
选取有序的数据作为路由条件,不同分段分散到不同的数据表中。
优点:可以随着数据的增加平滑地扩充新的表。
缺点:可能存在数据分布不均匀。
2、Hash路由
选择某个列(或者几个列的组合)的值进行Hash运算,然后根据运算结果分散到不同的数据库表中。
优点:表数据分布比较均匀。
缺点:初始表数量不好选取,扩充新的表数据需要重新分布。
3、配置路由
使用独立的表(或者配置文件等)记录路由配置信息。
优点:使用起来简单灵活,扩充表时只需要迁移指定的数据,然后修改路由表。
缺点:路由表本身太多影响系统整体性能。
数据库操作问题
1、join操作
问题:数据分散在不同的数据库中,无法做join查询。
解决:通过业务代码join查询,然后结果合并。
2、count操作
问题:数据分散在不同的数据库中,无法做count()操作。
解决:
(1)count相加
在业务代码或者数据库中间件对每个表进行count操作,然后将结果相加。
优点:实现简单。
缺点:性能较低。
(2)记录数表
新建一张表,保存数据记录的数量,每次插入和删除子表数据成功后,都更新记录数表。
优点:性能较好。
缺点:实现复杂。
3、order by操作
问题:数据分散在不同的数据库中,无法做order by操作。
解决:业务代码实现或者中间件查询每个子表中的数据,然后汇总进行排序。
实现方法
实现方法:
- 程序代码封装;
- 中间件封装;
类似读写分离,具体实现也是“程序代码封装”和“中间件封装”,但具体实现复杂一些,因为还有要判断SQL中具体操作的表,具体操作(例如count、order by、group by等),根据具体操作做不同的处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号