
[逆向]0ctf2015-slimming
slimming是一个64位的ELF文件。由于是逆向题,拿到文件后首先想到用IDA进行静态代码分析,但是发现该程序是静态链接的,其中含有大量的库函数代码,在无法进行符号解析的情况下,对其进行静态代码分析是不太可能的,因此转而进行动态分析。
0x01 初步分析
这个题目的名称slimming字面意思是“减肥”,猜测应该是一个与压缩解压缩有关的题目。运行elf后,构造一些输入,观察输出结果:
root@kali64:/home/ctf/0ctf2015/slimming# python -c 'print "A"*100' > in; ./slimming in out; hd out Done! 00000000 30 6f 70 73 8e 43 54 47 62 31 4f 51 51 32 77 34 |0ops.CTGb1OQQ2w4| 00000010 31 30 61 4e 75 30 7c 49 64 6c 39 4c 4e 65 33 01 |10aNu0|Idl9LNe3.| 00000020 c5 43 |.C| 00000022 root@kali64:/home/ctf/0ctf2015/slimming# echo -n "ABC" > in; ./slimming in out; hd out Done! 00000000 30 6f 70 73 8e 43 e9 46 df 30 |0ops.C.F.0| 0000000a root@kali64:/home/ctf/0ctf2015/slimming# echo -n "BCA" > in; ./slimming in out; hd out Done! 00000000 30 6f 70 73 8d 43 e8 46 dd 30 |0ops.C.F.0| 0000000a root@kali64:/home/ctf/0ctf2015/slimming# echo -n "CAB" > in; ./slimming in out; hd out Done! 00000000 30 6f 70 73 8c 43 ea 46 de 30 |0ops.C.F.0| 0000000a
这些输出印证了我们的想法:
- 当输入含有大量重复内容的字符串时(100个A),输出的长度大幅减小了(即被压缩了)
- 当输入不含有重复内容的字符串时,输出的长度增大了,猜想是对其中的字进行编码导致的
因此我们大致确定slimming是一个实现数据压缩的程序。继续观察上述输出来寻找规律:
- 在所有的输出中,前四个字节是相同的,为”0ops”,很明显,这是压缩文件的magic code。在压缩算法的实现中这很常见,比如zip压缩文件的magic code为“PK”。我们在后续进行解压缩时,略过这4个字节即可。
- 第5个字节是变化的,但第6个字节是固定的,为”C”,猜想该字符代表”Compress”,“压缩“的意思,这应该是出题人向我们传递的线索,也印证了我们此前的想法
- 当输入的内容不可压缩(下称literal)时,呈现出很强的规律性,比如在有效载荷的第1个字节,’A’对应0x8e,’B’对应0x8d, ‘C’对应0x8c,但是在不同的位置相同的literal被编码的内容不同,但大都呈现类似的规律
第三个规律是我们要详细分析的。在简单的压缩算法中,literal应该是不会被编码的,那么这些编码应该是通过某种方式映射而来。不难发现,在相同的位置,literal与编码值异或的结果是相同的,比如:
第一字节(有效载荷,下同):
0x8e ^ ord(‘A’) = 0x8d ^ ord(‘B’) = 0x8c ^ ord(‘C’) = 0xcf
第三字节:
0xe9 ^ ord(‘A’) = 0xe8 ^ ord(‘B’) = 0xe7 ^ ord(‘C’) = 0xab
其他奇数字节呈现相同的规律。因此我们推测,对于literal的编码,应该是literal与确定的值异或而来。那么对于偶数字节,又有什么规律呢?规律也很明显,就是该字节仅与位置有关,与literal无关,貌似也是某个值与与确定的值异或而来,我们假设是0与某个值异或而来。
我们可以构造一段较长的、不含有重复内容的负载来观察一下,原始负载呈现什么规律:
编写如下代码:
def getxorstream(): data = "" for i in xrange(0, 256): data += chr(i) with open("./in", "wb") as fin: fin.write(data) fin.close() os.system("./slimming ./in ./out") with open("./out", "rb") as fout: data = fout.read() fout.close() data = data[4:] origindata = [] for i in xrange(0, len(data), 2): origindata.append(ord(data[i]) ^ (i/2)) origindata.append(ord(data[i+1]) ^ 0) print origindata
运行该函数后,打印信息如下:
root@kali64:/home/ctf/0ctf2015/slimming# ./slim.py Done! [207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0, 207, 67, 171, 70, 156, 48, 178, 80]
结果也呈现出很强的规律性,可以看到,结果是如下数组的循环:
207, 67, 171, 70, 156, 48, 178, 80, 173, 51, 140, 53, 203, 49, 152, 79, 141, 49, 139, 72, 146, 109, 204, 77, 186, 100, 203, 0
因此我们能够得出结论,slimming程序在将压缩结果输出到文件之前,首先会将结果循环地与上述流做异或,后续我们在做解压缩时,也需要先将最终结果与上述流做异或才能得到压缩后的数据。
0x02 压缩算法分析
压缩的核心问题,是将载荷中重复出现的字用较短的编码进行替代,以达到降低载荷长度的目的,接下来我们要确定的问题是对于重复出现的负载,slimming是如何进行编码的。
我们先写一个脚本,将特定负载进行压缩,然后取出压缩后的负载与上述流进行异或,看看实际压缩后的负载是怎样的。脚本如下:
#!/usr/bin/python import os import sys from pwn import * #The stream to xor with when output compressed data xorstream = [0xcf,0x43,0xab,0x46,0x9c,0x30,0xb2,0x50,0xad,0x33,0x8c,0x35,0xcb,0x31,0x98,0x4f,0x8d,0x31,0x8b,0x48,0x92,0x6d,0xcc,0x4d,0xba,0x64,0xcb,0x00] #Get compressed data def compress(s): with open("in", "wb") as fin: fin.write(s.strip('\n')) fin.close() os.system("./slimming in out") with open("out", "rb") as fout: data = fout.read() fout.close() return data[4:] #Undo xor toward compressed data def unxor(s): print ordlist(xor(s, xorstream, cut='left')) def main(): data = compress(sys.argv[1]) unxor(data) if __name__ == "__main__": main()
然后我们执行下列命令:
root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py a Done! [97, 0] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aa Done! [97, 0, 97, 0] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaa Done! [97, 0, 255, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaa Done! [97, 0, 255, 1, 97, 0] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaa Done! [97, 0, 255, 1, 255, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaa Done! [97, 0, 255, 1, 254, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaaa Done! [97, 0, 255, 1, 254, 1, 97, 0] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaaaa Done! [97, 0, 255, 1, 254, 1, 255, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaaaaa Done! [97, 0, 255, 1, 254, 1, 254, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaaaaaa Done! [97, 0, 255, 1, 254, 1, 253, 1] root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py aaaaaaaaaaa Done! [97, 0, 255, 1, 254, 1, 253, 1, 97, 0]
可以发现:
- ‘a’被编码为literal(‘a’) + 0
- ‘aa’被编码为literal(‘a’) + 0 + literal(‘a’) + 0
- ‘aaa’被编码为Literal(‘a’) + 0 + reference(‘aa’) + 1
- ‘aaaa’ 被编码为Literal(‘a’) + 0 + reference(‘aa’) + 1 + literal(‘a’) + 0
- …
通过观察编码情况,可以总结出压缩规律如下:
- 当字长超过(含)2时,会被编码
- 偶数位字节为0或1,当为0时,表示这个是一个literal,当为非0时,表示这是一个reference
- 编码中出现的255,254,253等数字看上去是字的索引,出现新的字时,会产生新的索引,从当前来看,最大索引号是255
slimming应该解析了负载中所有的字(长度超过2的缓冲区,下同),并将每一个字放到字典中,每个字对应着一个索引,索引编号从大到小,最大索引号为255。在压缩过程中,如果遇到了一个已经存在的字,将使用其索引号进行引用。
那么字是如何选取的,负载又是如何压缩的呢?
不断构造负载,观察压缩情况,可以发现压缩过程很简单:
在某个位置,会从该位置向后寻找一个在字典中已经存在的最长的字W(为什么要找最长的字?因为对最长的字进行压缩会产生最大的压缩比),对W根据其索引进行编码,同时在W后取出一个字节P,将W+P作为一个新的字添加到字典中。跳过W到P的位置,继续这个过程。
整个压缩过程和字的产生过程比较简单,也很好理解。写一段python代码模拟这个过程如下:
#emulate the compression process def compress (data): print "To compress %s"%(data) out,dictionary = [],[] i,j = 0,0 while i < len(data): j = i + 1 #Search the longest word already in dictionary from current position while j < len(data) and data[i:j+1] in dictionary: j = j + 1 #Add the new word if j < len(data): dictionary.append(data[i:j+1]) #If we find a word(word's length must be longer than 2) in the dictionary, compress this word with its reference if len(data[i:j]) > 1: out += [0xFF - dictionary.index(data[i:j]), 1] #Else just use literal else: out += [ord(data[i]), 0] i = j return out
对于压缩过程,这里还遗留一个问题。上面提到,最大的索引编号是255,那么如果字的个数超过255,该如何建立索引呢?这是很容易出现的问题,大一点的文件,很容易出现字数超过255的情况。我们可以构造一段负载,让字的个数超过255个,看看是如何编码的,如下:
#!/usr/bin/python import os from pwn import * #The stream to xor with when output compressed data xorstream = [0xcf,0x43,0xab,0x46,0x9c,0x30,0xb2,0x50,0xad,0x33,0x8c,0x35,0xcb,0x31,0x98,0x4f,0x8d,0x31,0x8b,0x48,0x92,0x6d,0xcc,0x4d,0xba,0x64,0xcb,0x00] #Get compressed data def compress(s): with open("in", "wb") as fin: fin.write(s.strip('\n')) fin.close() os.system("./slimming in out") with open("out", "rb") as fout: data = fout.read() fout.close() return data[4:] #Undo xor toward compressed data def unxor(s): print ordlist(xor(s, xorstream, cut='left')) def main(): data = ''.join(chr(x) for x in range(256)) data = compress(data + "AAA") unxor(data) if __name__ == "__main__": main()
负载为”\x00\x01\x02\x03…\x255AAA”,脚本输出如下:
root@kali64:/home/ctf/0ctf2015/slimming# ./s1.py Done! [0, 0, 1, 0, 2, 0, 3, 0, 4, 0, 5, 0, 6, 0, 7, 0, 8, 0, 9, 0, 10, 0, 11, 0, 12, 0, 13, 0, 14, 0, 15, 0, 16, 0, 17, 0, 18, 0, 19, 0, 20, 0, 21, 0, 22, 0, 23, 0, 24, 0, 25, 0, 26, 0, 27, 0, 28, 0, 29, 0, 30, 0, 31, 0, 32, 0, 33, 0, 34, 0, 35, 0, 36, 0, 37, 0, 38, 0, 39, 0, 40, 0, 41, 0, 42, 0, 43, 0, 44, 0, 45, 0, 46, 0, 47, 0, 48, 0, 49, 0, 50, 0, 51, 0, 52, 0, 53, 0, 54, 0, 55, 0, 56, 0, 57, 0, 58, 0, 59, 0, 60, 0, 61, 0, 62, 0, 63, 0, 64, 0, 65, 0, 66, 0, 67, 0, 68, 0, 69, 0, 70, 0, 71, 0, 72, 0, 73, 0, 74, 0, 75, 0, 76, 0, 77, 0, 78, 0, 79, 0, 80, 0, 81, 0, 82, 0, 83, 0, 84, 0, 85, 0, 86, 0, 87, 0, 88, 0, 89, 0, 90, 0, 91, 0, 92, 0, 93, 0, 94, 0, 95, 0, 96, 0, 97, 0, 98, 0, 99, 0, 100, 0, 101, 0, 102, 0, 103, 0, 104, 0, 105, 0, 106, 0, 107, 0, 108, 0, 109, 0, 110, 0, 111, 0, 112, 0, 113, 0, 114, 0, 115, 0, 116, 0, 117, 0, 118, 0, 119, 0, 120, 0, 121, 0, 122, 0, 123, 0, 124, 0, 125, 0, 126, 0, 127, 0, 128, 0, 129, 0, 130, 0, 131, 0, 132, 0, 133, 0, 134, 0, 135, 0, 136, 0, 137, 0, 138, 0, 139, 0, 140, 0, 141, 0, 142, 0, 143, 0, 144, 0, 145, 0, 146, 0, 147, 0, 148, 0, 149, 0, 150, 0, 151, 0, 152, 0, 153, 0, 154, 0, 155, 0, 156, 0, 157, 0, 158, 0, 159, 0, 160, 0, 161, 0, 162, 0, 163, 0, 164, 0, 165, 0, 166, 0, 167, 0, 168, 0, 169, 0, 170, 0, 171, 0, 172, 0, 173, 0, 174, 0, 175, 0, 176, 0, 177, 0, 178, 0, 179, 0, 180, 0, 181, 0, 182, 0, 183, 0, 184, 0, 185, 0, 186, 0, 187, 0, 188, 0, 189, 0, 190, 0, 191, 0, 192, 0, 193, 0, 194, 0, 195, 0, 196, 0, 197, 0, 198, 0, 199, 0, 200, 0, 201, 0, 202, 0, 203, 0, 204, 0, 205, 0, 206, 0, 207, 0, 208, 0, 209, 0, 210, 0, 211, 0, 212, 0, 213, 0, 214, 0, 215, 0, 216, 0, 217, 0, 218, 0, 219, 0, 220, 0, 221, 0, 222, 0, 223, 0, 224, 0, 225, 0, 226, 0, 227, 0, 228, 0, 229, 0, 230, 0, 231, 0, 232, 0, 233, 0, 234, 0, 235, 0, 236, 0, 237, 0, 238, 0, 239, 0, 240, 0, 241, 0, 242, 0, 243, 0, 244, 0, 245, 0, 246, 0, 247, 0, 248, 0, 249, 0, 250, 0, 251, 0, 252, 0, 253, 0, 254, 0, 255, 0, 65, 0, 255, 2]
可以看到,其实对于一个reference来说,编码的第二个字节也是索引的一部分,假设某个reference编码的第一字节为a,第二字节为b,我们可以得出索引的计算方法为:
index = (b - 1) << 8 | (255 – a)
0x03 压缩实例
至此,我们已经分析出了slimming的压缩算法。下面以一个实例说明压缩过程。
假设待压缩内容为“ABABABABAB”,详细压缩过程如下:
Step 1 从开头的A处查找当前字典中最长的字,因为此时字典为空,所以新的字为“AB”,将”AB”放入字典,索引值为255。将A(literal)进行编码,此时编码负载为[65,0]。完成后,跳转到红色的B处:ABABABABAB
Step 2 从红色的B处查找当前字典中最长的字,由于“BA”不在字典中,索引新的字为“BA”,将“BA”放入字典,索引值为254。将B(literal)进行编码,此时编码负载为[65,0,66,0]。完成后,跳转到红色的A处:ABABABABAB
Step 3从红色的A处查找当前字典中最长的字,找到字典中最长的字为“AB”。将“AB”(reference)进行编码,此时编码负载为[65,0,66,0,255,1]。此时新的不在字典中的字为“ABA”,将“ABA”放入字典,索引值为253。完成后跳转到红色的A处:ABABABABAB
Step 4从红色的A处查找当前字典中最长的字,找到字典中最长的字为“ABA”。将“ABA”(reference)进行编码,此时编码负载为[65,0,66,0,255,1,253,1]。此时新的不在字典中的字为“ABAB”,将“ABAB”放入字典,索引值为252。完成后跳转到红色的B处:ABABABABAB
Step 5从红色的B处查找当前字典中最长的字,找到字典中最长的字为“BA”,索引为254。将“BA”(reference)进行编码,此时编码负载为[65,0,66,0,255,1,253,1,254,1]。此时新的不在字典中的字为“BAB”,将“BAB”放入字典,索引值为251。完成后跳转到红色的B处:ABABABABAB
Step 6 此时只剩下B(literal),将其编码,此时编码负载为[65,0,66,0,255,1,253,1,254,1,66,0]
将编码负载与xorstream进行异或后,便可得到最终的输出。
0x04 解压缩
解压缩是压缩过程的逆过程,解压缩过程中,我们可以根据一个字节对的第二个字节来判断解码的是literal还是reference,如果第二个字节为0,说明是literal,如果大于0,说明是reference,根据索引值从字典中取出相应的字即可。
可能存在的问题是,当指定索引值的字在字典中不存在怎么办?此时,这个字必然是将要添加到字典中的字。
从压缩的角度看,如下图:
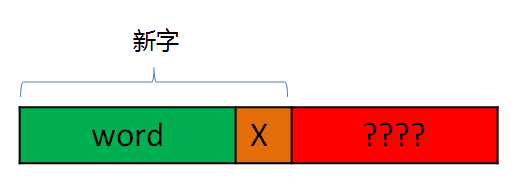
当压缩到word时,下一个需要加入字典的新字为word+X,即绿色加上橙色的部分。
但是从解压的角度看,如下图:
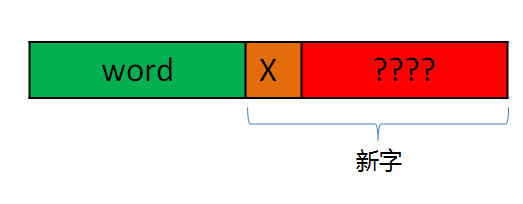
当解压到word时,下一个需要解压的字为X+????,即橙色加上红色的部分。这说明,新的字首尾两个字节是相同的,且等于word的第一个字节,即:
新字 = word + word[0]
至此,我们可以写出解压脚本了,如下:
#!/usr/bin/python import sys from pwn import * xorstream = [0xcf,0x43,0xab,0x46,0x9c,0x30,0xb2,0x50,0xad,0x33,0x8c,0x35,0xcb,0x31,0x98,0x4f,0x8d,0x31,0x8b,0x48,0x92,0x6d,0xcc,0x4d,0xba,0x64,0xcb,0x00] def decompress (data): out,dictionary = [],[] pword = None for i in xrange(0, len(data), 2): pair0 = ord(data[i]) pair1 = ord(data[i+1]) #It is literal if pair1 == 0: word = chr(pair0) else: idx = (0xFF - pair0) | (pair1 - 1) << 8 if idx == len(dictionary): word = pword + pword[0] else: word = dictionary[idx] if pword: dictionary.append(pword + word[0]) pword = word out += word return out def main(): fin = open(sys.argv[1], "rb") data = fin.read() fin.close() unmasked = xor(data[4:], xorstream, cut='left') decompressed = decompress (unmasked) fout = open(sys.argv[2], "wb") fout.write(''.join(decompressed)) fout.close() if __name__ == "__main__": main ()
运行该脚本,对slimming_data进行加压缩,将输出保存到名称为“decompressed”的文件中:
root@kali64:/home/ctf/0ctf2015/slimming# ./slim.py ./slimming_data decompressed root@kali64:/home/ctf/0ctf2015/slimming# file decompressed decompressed: ELF 32-bit LSB executable, Intel 80386, version 1 (SYSV), statically linked, stripped root@kali64:/home/ctf/0ctf2015/slimming# chmod +x decompressed root@kali64:/home/ctf/0ctf2015/slimming# ./decompressed sdfsfdsfsf No.No..No...
解压缩出的内容为一个ELF文件,执行后会接收用户输入,之后提示错误。用IDA分析这个释放出来的ELF文件,发现非常简单,这个ELF会接收用户输入,并与一个特定的字符串比较,这个字符串即为flag:
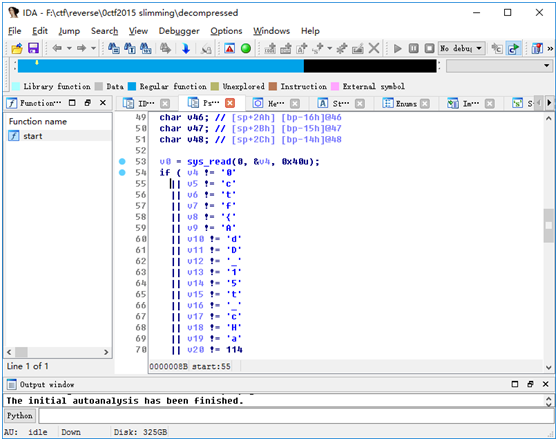
至此,任务完成,非常有意思的一道题目。

