史上最全的Collection集合总结
1、什么是集合,集合与数组的区别
Java集合类存放于 java.util 包中,是一个用来存放对象的容器。
注意:
①、集合只能存放对象。比如你存一个 int 型数据 1放入集合中,其实它是自动转换成 Integer 类后存入的,Java中每一种基本类型都有对应的引用类型。
②、集合存放的是多个对象的引用,对象本身还是放在堆内存中。
③、集合可以存放不同类型,不限数量的数据类型。
集合和数组的区别?
①、数组是静态的,数组一旦创建就无法改变其容量;集合是可以动态扩展容量。
②、数组存放的类型只能是一种(基本类型/引用类型),集合存放的类型可以不同的(不加泛型时添加的是Object类型,基本类型自动转为引用类型)
③、数组是java语言中内置的数据类型,是线性排列的,执行效率或类型检查,都是最快的。
④、数组创建时就声明了类型,而集合不用。
2、集合继承关系图
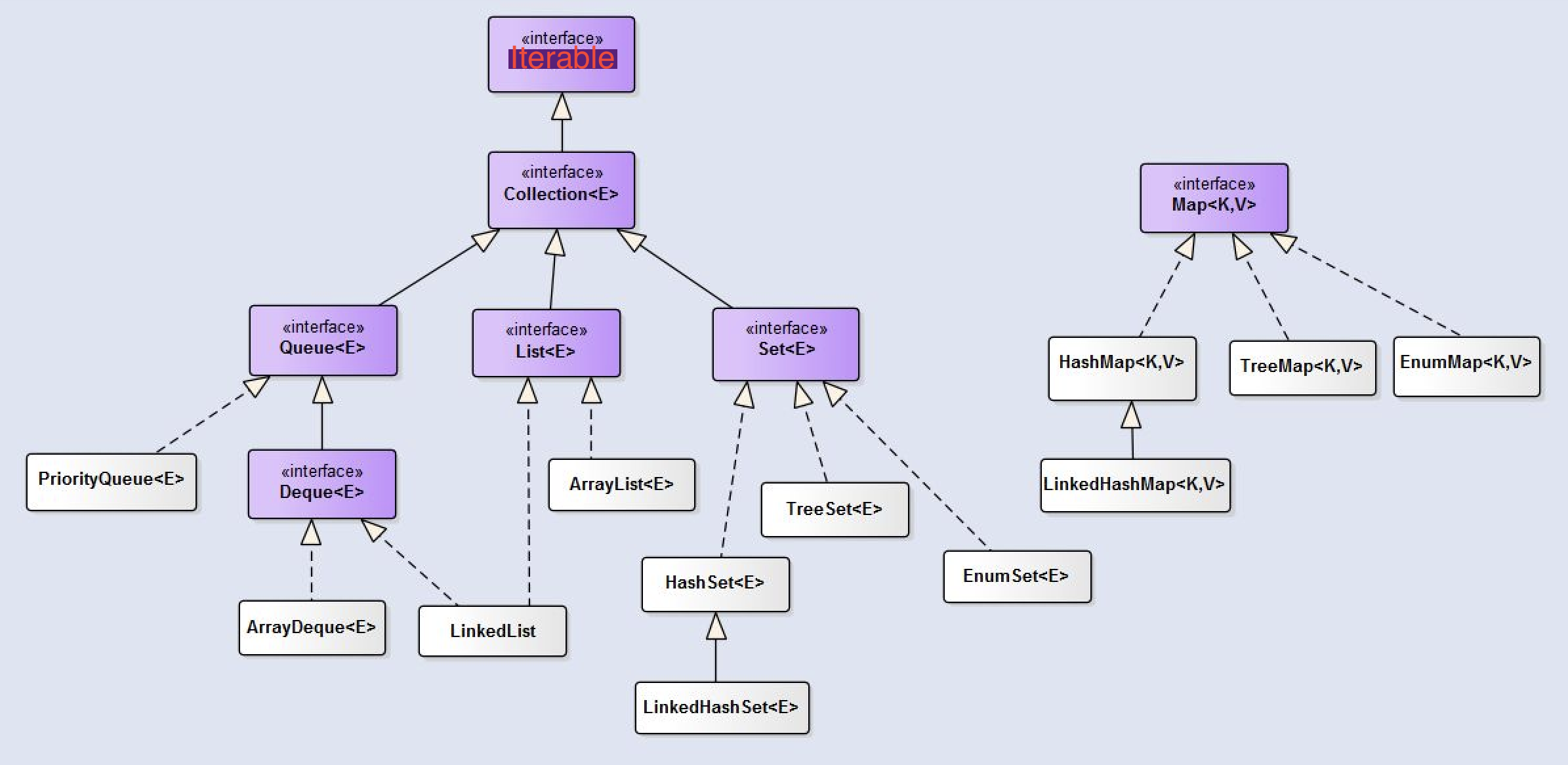
3、map和collection的区别
本来两者是没有联系的。
1、 区别:
Collection : 单列集合。
Map : 双列集合,键和值一一映射,针对键有效,跟值无关。
2、 间接联系:
HashSet 集合的add()方法依赖于Map接口的子实现类HashMap集合的put()方法。
TreeSet 集合的add()方法依赖于Map接口的子实现类TreeMap 集合的put()方法。
4、Iterable 和 Iterator 的区别
1、两者都是接口,Iterable位于java.lang包下,Iterator位于java.util包下,两者之间的关系是Iterable接口提供了一个获取Iterator接口实例的方法。
2、Iterator是迭代器,如果一个对象拥有迭代器,那么就可以将对象中的所有元素和内容遍历出来,所以所有实现了Iterable接口的所有类都拥有迭代器Iterator。
3、Iterable接口是Java集合框架的顶级接口(不包括 map 系列的集合,Map接口 是 map 系列集合的顶层接口),实现此接口使集合对象可以通过迭代器遍历自身元素。Collection 接口 继承 Iterable接口。
5、foreach遍历、for循环和Iterable的渊源
- for 循环遍历集合 以及反编译后的代码
-
ArrayList<Integer> a1 = new ArrayList<Integer>(16); /*0-5*/ for (int i = 0; i < 6; i++) { a1.add(i); } for (int i = 0; i < 6; i++) { System.out.println(i); } /*************反编译后的代码**********************/ ArrayList<Integer> a1 = new ArrayList(16); int i; for(i = 0; i < 6; ++i) { a1.add(i); } for(i = 0; i < 6; ++i) { System.out.println(i); } - foreach遍历集合以及反编译后的代码
-
ArrayList<Integer> a1 = new ArrayList<Integer>(16); /*0-5*/ for (int i = 0; i < 6; i++) { a1.add(i); } // foreach循环 for(Integer i : a1){ System.out.println(i); } /***************反编译后的代码*******************/ ArrayList<Integer> a1 = new ArrayList(16); for(int i = 0; i < 6; ++i) { a1.add(i); } // 反编译之后发现是调用了集合的Iterator来实现的 Iterator var4 = a1.iterator(); while(var4.hasNext()) { Integer i = (Integer)var4.next(); System.out.println(i); } - foreach遍历数组以及反编译后的代码
-
String[] str = {"a", "b", "c", "d"}; for (String s : str) { System.out.println(s); } /***************反编译后的代码**********************/ String[] str = new String[]{"a", "b", "c", "d"}; String[] var2 = str; int var3 = str.length; for(int var4 = 0; var4 < var3; ++var4) { String s = var2[var4]; System.out.println(s); }从上面几个例子可以知道:
1、foreach循环底层调用的是iterator这个说法是错的,应该针对性的讲。对于数组,foreach底层的实现是简单的for循环,而对于集合,底层的实现则是通过Iterator来实现的
2、只有实现了Itearable接口的类才能使用foreach遍历也是错的。对于数组,它是java.lang.Object的直接子类,同时实现了java.lang.Cloneable和java.io.Serializable接口,所以它并没有实现Iterator接口,所以数组可以使用foreach循环,底层实现则是for循环。
6、Iterable源码分析
在jdk1.8以前的版本只有一个Iterator<T>方法,Java1.8接口加入了新特性,打破了Java以前对接口的定义。
public interface Iterable<T> {
// 返回T元素类型的迭代器
Iterator<T> iterator();
// 对Iterable的每个元素执行给定操作,直到处理完所有元素或操作引发异常。
// 除非实现类另有指定,否则操作按迭代顺序执行(如果指定了迭代顺序)
// Consumer 四大函数接口,不在本章叙述范围内 后续会有文章专门讲解java8函数编程
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
// 可分割的迭代器,是1.8推出的用于并行遍历元素而设计的一个迭代器
// 官方文档说明默认的实现分割的能力比较差,推荐覆盖默认实现。
// 可以跟上面的Iterator功能区分;一个是顺序遍历,一个是并行遍历
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
}
7、Iterator源码分析
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while(this.hasNext()) {
action.accept(this.next());
}
}
}
1、迭代器Iterator 的方法:
boolean hasNext():判断容器内是否还有可供访问的元素
Object next():返回迭代的下一个元素返回值是 Object,需要强制转换成自己需要的类型。
void remove():删除迭代器刚越过的元素。
void forEachRemaining(): 对集合中剩余的元素进行操作,直到元素完毕或者抛出异常。
//创建一个元素类型为Integer的集合
Collection<Integer> collection = new HashSet<>();
for (int i=0;i<10 ;i++ ){
collection.add(i);
}
//获取该集合的迭代器
Iterator<Integer> iterator= collection.iterator();
int i=0;
while(iterator.hasNext())
{
System.out.print(iterator.next());
i++;
if (i==5)
{
break;
}
}
System.out.println("--------------");
//调用forEachRemaining()方法遍历集合元素
iterator.forEachRemaining(ele -> System.out.print(ele));
}
}
这时输出:
01234
--------------
56789
可以看到,当我们第一次用迭代器遍历时,只让它遍历五次就跳出循环,那么就还剩下五个元素,再调用forEachRemaining()方法,就可以看到输出后五个元素了。
2、深度分析ArrayList 的Iterator 实现。
首先,由源码知道hasNext()方法和next()方法会在Iterator接口的实现类中实现。那么,当我们调用ArrayLIst.iterator()时,我们调用的是该类中的:
public Iterator<E> iterator() {
return new Itr();
}
进一步发现Itr是ArrayList中的一个内部类
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
public E next() {
...
}
public void remove() {
...
}
@Override
public void forEachRemaining(Consumer<? super E> consumer) {
...
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
首先我们看一下它的几个成员变量:
cursor:表示下一个要访问的元素的索引,从next()方法的具体实现就可看出
lastRet:表示上一个访问的元素的索引
expectedModCount:表示对ArrayList修改次数的期望值,它的初始值为modCount。
modCount是AbstractList类中的一个成员变量
protected transient int modCount = 0;
该值表示对List的修改次数,查看ArrayList的add()和remove()方法就可以发现,每次调用add()方法或者remove()方法就会对modCount进行加1操作。
当我们这样调用时:
Iterator it = ArrayList.iterator();
实际上是将ArrayList的内部类对象赋给了it,然后我们看类Itr中定义这样的一个变量:
int expectedModCount = modCount
为expectedModCount赋初值为modCount,这个成员变量是ArrayList继承于AbstractList的,而AbstractList定义了一个成员变量modCount
protected transient int modCount = 0;
然后我们调用it的方法其实就是在调用类Itr的中的hasNext() 、next()等方法。
hasNext()方法
public boolean hasNext() {
return cursor != size;
}
hasNext的判断条件为cursor!=size,就是当前迭代的位置不是数组的最大容量值就返回true。
next()方法
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
首先调用checkForComodification()方法判断是否并发修改,然后使用cursor光标返回elementData中序号为cursor的对象,同时cursor+1
cursor的初始值是0,lastRet的初始值是-1,cursor始终等于lastRet+1
remove()方法
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public static void main(String[] args){
List<String> list = new ArrayList<String>();
list.add("a");
Iterator iterator = list.iterator();
while(iterator.hasNext()){
String str = (String) iterator.next();
list.remove(str);
}
}
//Exception in thread "main" java.util.ConcurrentModificationException
从报错信息来看,抛出的是并发修改类型(ConcurrentModificationException),发生在调用Itr类的next()方法时
为什么会抛出这样的异常呢?
我们看到这个集合里面只有一个元素,当iterator调用第一个next()方法时,首先进行checkForComodification()判断,这个时候expectedModCount肯定是与modCount相等的,因为构造函数里面刚刚完成赋值;然后调用了ArrayList的remove方法,这时modCount+1,而expectedModCount仍为原值,
再次调用hasNext方法时,由于cursor为1,ArrayList.size为0,所以返回值仍为true,再次进入循环,而此时第二次调用next()方法时,在checkForComodification()时就会抛出异常
而当我们换成调用iterator的remove()方法时,程序并不会报错,因为此时根本不会进入第二次循环,而且this.expectedModCount = ArrayList.this.modCount;使两者保持同步,也为以后的方法调用扫除了隐患
类似这样的并发修改异常还有:
public static void main(String[] args){
List<String> list = new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
Iterator iterator = list.iterator();
while(iterator.hasNext()){
String str = (String) iterator.next();
if(str.equals("d")){
list.remove(str);
}else{
System.out.println(str);
}
}
}
//a
//b
//c
这样的程序不会报错,因为当remove("d")时,cursor=4,而删除d后,size=4,从而跳出循环,e也不会输出了
同样的,将list.remove(str);换成iterator.remove();后,程序正常执行,输出结果为 a b c e,这样才是正确的结果。
4、在单线程环境下的解决ConcurrentModificationException异常,删除元素的话只需要使用迭代器中的remove()方法即可。( iterator.remove(); )
5、在多线程环境下的解决ConcurrentModificationException异常
public class Test {
static ArrayList<Integer> list = new ArrayList<Integer>();
public static void main(String[] args) {
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
Thread thread1 = new Thread(){
public void run() {
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()){
Integer integer = iterator.next();
System.out.println(integer);
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
};
};
Thread thread2 = new Thread(){
public void run() {
Iterator<Integer> iterator = list.iterator();
while(iterator.hasNext()){
Integer integer = iterator.next();
if(integer==2)
iterator.remove();
}
};
};
thread1.start();
thread2.start();
}
}
//程序报错,出现ConcurrentModificationException异常
有人说ArrayList是非线程安全的容器,换成Vector就没问题了,实际上换成Vector还是会出现这种错误。
原因在于,虽然Vector的方法采用了synchronized进行了同步,但是实际上通过Iterator访问的情况下,每个线程里面返回的是不同的iterator,也即是说expectedModCount是每个线程私有。假若此时有2个线程,线程1在进行遍历,线程2在进行修改,那么很有可能导致线程2修改后导致Vector中的modCount自增了,线程2的expectedModCount也自增了,但是线程1的expectedModCount没有自增,此时线程1遍历时就会出现expectedModCount不等于modCount的情况了。
因此一般有2种解决办法:
1)在使用iterator迭代的时候使用synchronized或者Lock进行同步;
2)使用并发容器CopyOnWriteArrayList代替ArrayList和Vector。
8、ListIterator与Iterator的区别
1、Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List。
2、Iterator对集合只能是前向遍历,ListIterator既可以前向也可以后向。
3、ListIterator实现了Iterator接口(public interface ListIterator<E> extends Iterator<E> ),并包含其他的功能,比如:增加元素,替换元素,获取前一个和后一个元素的索引。
ListIterator相对Iterator增加了如下3个方法:
boolean hasPrevious():返回该迭代器关联的集合是否还有上一个元素。
Object previous():返回该迭代器的上一个元素。
void add():在指定位置插入一个元素。
9、ArrayList和LinkedList的关系和区别
1、底层数据结构不同:ArrayList:底层是Object数组 源码:transient Object[] elementData;
LinkeList : 底层是双向链表, 有前向指针first 源码:transient Node<E> first; 后向指针last 源码:transient Node<E> last;
2、ArrayList支持随机访问而LinkedList不支持。
ArrayList源码中它实现了一个RandomAccess接口,然而这个接口是个空接口,实现这个空接口的意义就是标记这个类具有一个随机访问的特性。
最根本原因是ArrayList是根据数组下标去访问里面的数据。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
3、查询、插入和删除的效率不同。
ArrayList:采用的是数组来实现的,插入和删除受到元素位置的影响,会产生移位。
LinkeList:采用的是链表来存储数据,所有不会受到元素位置的影响,直接改变指向即可。
ArrayList执行频繁的查找效率比LinkedList高,LinkedList执行频繁的插入和删除效率比Arraylist高。
4、占用的内存不一样。
ArrayList: ArrayLIst会预留一定的空间,数组实际空间大小比大于存储的空间大小。
LinkeList:Linkedlist则不会预留空间,而是有元素添加才会去申请这个元素所对应的内存空间。
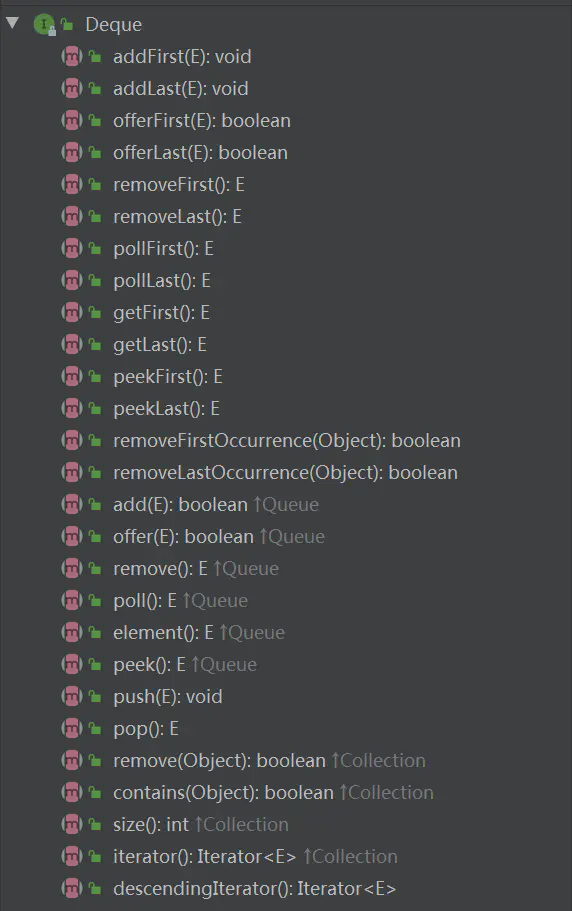
10、Queue [kju:] 和 Deque ['dek]的区别
结构:Queue和Deque都是接口,Deque接口继承Queue接口,Queue有一个直接子类PriorityQueue,而Deque中直接子类有两个:LinkedList以及ArrayDeque。
1、Queue是FIFO的单端队列,Deque是双端队列,可以在首尾插入或删除元素。
2、由于双端队列的定义,Deque可以作为栈或者队列使用,而Queue只能作为队列或者依赖于子类的实现作为堆使用。
3、Queue接口中的方法可以分为两类,一类是抛出异常的,一类是不抛出异常的,每类都有三个操作,分别是队尾添加、队首删除并获取和队首获取,如下所示:

// 向队尾添加,成功返回true, 如果超出容量限制,抛出异常 boolean add(E e); // 向队尾添加,成功返回true, 如果超出容量限制,返回false boolean offer(E e); // 删除并获取队首元素,成功返回true,如果队列为空,抛出异常 E remove(); // 删除并获取队首元素,成功返回true,如果队列为空,返回false E poll(); // 获取队首元素,成功返回true,如果队列为空,抛出异常 E element(); // 获取队首元素,成功返回true,如果队列为空,返回false E peek();
4、Deque除了继承了Queue的接口,又对每种方法额外添加了first与last方法用以实现操作双端队列。
11、ArrayList类实现原理及源码分析
ArrayList是基于数组实现的,是一个动态数组,其容量(容量:指的是存储列表元素的数组的大小)能自动增长。默认初始容量为10。随着ArrayList中元素的增加,它的容量也会不断的自动增长。在每次添加新的元素时,ArrayList都会检查是否需要进行扩容操作,扩容操作带来数据向新数组的重新拷贝,所以如果我们知道具体业务数据量,在构造ArrayList时可以给ArrayList指定一个初始容量,这样就会减少扩容时数据的拷贝问题。当然在添加大量元素前,应用程序也可以使用ensureCapacity操作来增加ArrayList实例的容量,这可以减少递增式再分配的数量。
注意,ArrayList实现不是同步的。ArrayList不是线程安全的,只能用在单线程环境下,多线程环境下可以考虑用Collections.synchronizedList(List l)函数返回一个线程安全的ArrayList类,也可以使用concurrent并发包下的CopyOnWriteArrayList类。
ArrayList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了RandomAccess接口,支持快速随机访问,实际上就是通过下标序号进行快速访问,实现了Cloneable接口,能被克隆。
List list = Collections.synchronizedList(new ArrayList(...));
CopyOnWriteArrayList list = new CopyOnWriteArrayList();
——ArrayList 线程不安全,查询速度快
——Vector 线程安全,但速度慢,已被ArrayList替代
——LinkedList 链表结果,增删速度快
package ArrayList类的常用方法;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
public class Test {
public static void main(String[] args) {
/*构造方法: 1. ArrayList() 构造一个初始容量为10的空列表,这是最常用的构造方法
2. ArrayList(Collection<? extends E> c)
构造一个包含指定 collection 的元素的列表,这些元素是按照该collection的迭代器返回它们的顺序排列的
3. ArrayList(int initialCapacity) 构造一个具有指定初始容量的空列表。
*/
/*//1. 增: 4个方法:
// 1.1 add(E e):将指定的元素添加到此列表的尾部。
// 1.2 add(int index, E element):将指定的元素插入此列表中的指定位置。
// 1.3 addAll(Collection<? extends E> c):按照指定 collection的迭代器所返回的元素顺序,
// 将该 collection中的所有元素添加到此列表的尾部。
// 1.4 addAll(int index, Collection<? extends E> c):从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。
*/
//案例:
ArrayList list = new ArrayList();
list.add(5);
list.add(2);
list.add(2, '你');//将置顶元素添加到指定位置(插入算法)
System.out.println(list); //[5, 2, 你]
ArrayList list2 = new ArrayList();
list2.add("13");
list2.add("14");
list2.add("呀");
list.addAll(list2);
System.out.println(list); //[5, 2, 你, 13, 14, 呀]
list.addAll(2, list2);
System.out.println(list); //[5, 2, 13, 14, 呀, 你, 13, 14, 呀]
list.set(5, "你好呀");
System.out.println(list); //[5, 2, 13, 14, 呀, 你好呀, 13, 14, 呀]
/* 2. 删: 4个方法:
// 2.1 clear() 移除此列表中的所有元素。
// 2.2 remove(int index):移除此列表中指定位置上的元素。
// 2.3 remove(Object o):移除此列表中首次出现的指定元素(如果存在)。
// 2.4 removeAll():移除此 collection 中那些也包含在指定 collection 中的所有元素
*/
// 案例:
list.remove(2);
list.remove("14");
System.out.println(list); // [5, 2, 呀, 你好呀, 13, 14, 呀]
list.removeAll(list2);
System.out.println(list); //[5, 2, 你好呀]
list.clear();
System.out.println(list); //[]
/*3. 改:
3.1 set(int index, E element):用指定的元素替代此列表中指定位置上的元素。
3.2 ensureCapacity(int minCapacity) 增加此 ArrayList 实例的容量,手动扩容
3.3 trimToSize() 将此 ArrayList 实例的容量调整为列表的当前大小 .
比如最开始容器大小为100,后来发现容器只添加了5个,就可以使用该方法,调整为只有5个元素的容器
*/ //案例:
ArrayList list3 = new ArrayList(50);
list3.add("你好");
list3.add("我好");
list3.add("大家好");
list3.set(2, "enen");
System.out.println(list3); //[你好, 我好, enen]
list3.ensureCapacity(40);
System.out.println(list3.size()); //3
list3.trimToSize();
/*4. 查:
4.1 size() 返回此列表中的元素数。
4.2 get(int index) 返回此列表中指定位置上的元素
4.3 indexOf(Object o) 返回此列表中首次出现的指定元素的索引,或如果此列表不包含元素,则返回 -1
4.4 lastIndexOf(Object o) 返回此列表中最后一次出现的指定元素的索引,或如果此列表不包含索引,则返回 -1。
*/
System.out.println(list3.get(1)); //我好
System.out.println(list3.indexOf("我好")); //1
/*5. 其他方法
*/ System.out.println(list.isEmpty()); //true
System.out.println(list3.contains("我好")); //true
// Object[] toArray() 按适当顺序(从第一个到最后一个元素)返回包含此列表中所有元素的数组
System.out.println(Arrays.toString(list3.toArray())); //[你好, 我好, enen]
}
}
12、LinkedList类实现原理及源码分析
LinkedList 和 ArrayList 一样,都实现了 List 接口,但其内部的数据结构有本质的不同。LinkedList 是基于链表实现的(通过名字也能区分开来),所以它的插入和删除操作比 ArrayList 更加高效。但也是由于其为基于链表的,所以随机访问的效率要比 ArrayList 差。
首先我们先看LinkedList的定义:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
transient int size = 0;
transient Node<E> first;
transient Node<E> last;
...
}
-
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
-
LinkedList 实现 List 接口,能对它进行列表操作。
-
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
-
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
-
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
从上述代码可以看出,LinkedList中有size,first以及last全局变量,其作用分别是:
-
size -- 存放当前链表有多少个节点。
-
first -- 指向链表的第一个节点的引用
-
last -- 指向链表的最后一个节点的引用
其中,Node是内部类,内容如下:
private static class Node<E> {
E item;//节点值
Node<E> next;//后继节点
Node<E> prev;//前驱节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
从上述代码可以看出,一个节点除了包含元素内容之外,同时包含前一个节点和后一个节点的引用~, 各个节点通过指定前一个节点和后一个节点,最终形成了一个链表~

LinkedList源码分析:
1、构造方法
//1、空构造方法:
public LinkedList() {
}
//2、用已有的集合创建链表的构造方法:
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
2、add相关方法
①、add(E e) 方法:将元素添加到链表尾部
public boolean add(E e) {
linkLast(e);//这里就只调用了这一个方法
return true;
}
/**
* 链接使e作为最后一个元素。
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;//新建节点
if (l == null)
first = newNode;
else
l.next = newNode;//指向后继元素也就是指向下一个元素
size++;
modCount++;
}
②、add(int index,E e):在指定位置添加元素
public void add(int index, E element) {
checkPositionIndex(index); //检查索引是否处于[0-size]之间
if (index == size)//添加在链表尾部
linkLast(element);
else//添加在链表中间
//linkBefore方法需要给定两个参数,一个插入节点的值,一个指定的node,所以我们又调用了Node(index)去找到index对应的node
linkBefore(element, node(index));
}
③、addAll(Collection c ):将集合插入到链表尾部
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
④、addAll(int index, Collection c): 将集合从指定位置开始插入
public boolean addAll(int index, Collection<? extends E> c) {
//1:检查index范围是否在size之内
checkPositionIndex(index);
//2:toArray()方法把集合的数据存到对象数组中
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
//3:得到插入位置的前驱节点和后继节点
Node<E> pred, succ;
//如果插入位置为尾部,前驱节点为last,后继节点为null
if (index == size) {
succ = null;
pred = last;
}
//否则,调用node()方法得到后继节点,再得到前驱节点
else {
succ = node(index);
pred = succ.prev;
}
// 4:遍历数据将数据插入
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
//创建新节点
Node<E> newNode = new Node<>(pred, e, null);
//如果插入位置在链表头部
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
//如果插入位置在尾部,重置last节点
if (succ == null) {
last = pred;
}
//否则,将插入的链表与先前链表连接起来
else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
}
上面可以看出addAll方法通常包括下面四个步骤:
- 检查index范围是否在size之内
- toArray()方法把集合的数据存到对象数组中
- 得到插入位置的前驱和后继节点
- 遍历数据,将数据插入到指定位置
⑤、addFirst(E e): 将元素添加到链表头部
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);//新建节点,以头节点为后继节点
first = newNode;
//如果链表为空,last节点也指向该节点
if (f == null)
last = newNode;
//否则,将头节点的前驱指针指向新节点,也就是指向前一个元素
else
f.prev = newNode;
size++;
modCount++;
}
⑥、addLast(E e): 将元素添加到链表尾部,与 add(E e) 方法一样
public void addLast(E e) {
linkLast(e);
}
3、根据位置取数据的方法
①、get(int index): 根据指定索引返回数据
public E get(int index) {
//检查index范围是否在size之内
checkElementIndex(index);
//调用Node(index)去找到index对应的node然后返回它的值
return node(index).item;
}
②、获取头节点(index=0)数据方法
public E getFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
}
public E element() {
return getFirst();
}
public E peek() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
public E peekFirst() {
final Node<E> f = first;
return (f == null) ? null : f.item;
}
区别: getFirst(),element(),peek(),peekFirst() 这四个获取头结点方法的区别在于对链表为空时的处理,是抛出异常还是返回null,其中getFirst() 和element() 方法将会在链表为空时,抛出异常
element()方法的内部就是使用getFirst()实现的。它们会在链表为空时,抛出NoSuchElementException
③、获取尾节点(index=-1)数据方法:
public E getLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
}
public E peekLast() {
final Node<E> l = last;
return (l == null) ? null : l.item;
}
两者区别: getLast() 方法在链表为空时,会抛出NoSuchElementException,而peekLast() 则不会,只是会返回 null。
4、根据对象得到索引的方法
①、int indexOf(Object o): 从头遍历找
public int indexOf(Object o) {
int index = 0;
if (o == null) {
//从头遍历
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
//从头遍历
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
②、int lastIndexOf(Object o): 从尾遍历找
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
//从尾遍历
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
//从尾遍历
for (Node<E> x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
}
5、检查链表是否包含某对象的方法
contains(Object o): 检查对象o是否存在于链表中
public boolean contains(Object o) {
return indexOf(o) != -1;
}
6、删除方法
remove() ,removeFirst(),pop(): 删除头节点
public E pop() {
return removeFirst();
}
public E remove() {
return removeFirst();
}
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
removeLast(),pollLast(): 删除尾节点
public E removeLast() {
final Node<E> l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
}
public E pollLast() {
final Node<E> l = last;
return (l == null) ? null : unlinkLast(l);
}
区别: removeLast()在链表为空时将抛出NoSuchElementException,而pollLast()方法返回null。
remove(Object o): 删除指定元素
public boolean remove(Object o) {
//如果删除对象为null
if (o == null) {
//从头开始遍历
for (Node<E> x = first; x != null; x = x.next) {
//找到元素
if (x.item == null) {
//从链表中移除找到的元素
unlink(x);
return true;
}
}
} else {
//从头开始遍历
for (Node<E> x = first; x != null; x = x.next) {
//找到元素
if (o.equals(x.item)) {
//从链表中移除找到的元素
unlink(x);
return true;
}
}
}
return false;
}
当删除指定对象时,只需调用remove(Object o)即可,不过该方法一次只会删除一个匹配的对象,如果删除了匹配对象,返回true,否则false。
unlink(Node x) 方法:
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;//得到后继节点
final Node<E> prev = x.prev;//得到前驱节点
//删除前驱指针
if (prev == null) {
first = next;//如果删除的节点是头节点,令头节点指向该节点的后继节点
} else {
prev.next = next;//将前驱节点的后继节点指向后继节点
x.prev = null;
}
//删除后继指针
if (next == null) {
last = prev;//如果删除的节点是尾节点,令尾节点指向该节点的前驱节点
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
remove(int index):删除指定位置的元素
public E remove(int index) {
//检查index范围
checkElementIndex(index);
//将节点删除
return unlink(node(index));
}
LinkedList类常用方法测试
ackage list;
import java.util.Iterator;
import java.util.LinkedList;
public class LinkedListDemo {
public static void main(String[] srgs) {
//创建存放int类型的linkedList
LinkedList<Integer> linkedList = new LinkedList<>();
/************************** linkedList的基本操作 ************************/
linkedList.addFirst(0); // 添加元素到列表开头
linkedList.add(1); // 在列表结尾添加元素
linkedList.add(2, 2); // 在指定位置添加元素
linkedList.addLast(3); // 添加元素到列表结尾
System.out.println("LinkedList(直接输出的): " + linkedList);
System.out.println("getFirst()获得第一个元素: " + linkedList.getFirst()); // 返回此列表的第一个元素
System.out.println("getLast()获得第最后一个元素: " + linkedList.getLast()); // 返回此列表的最后一个元素
System.out.println("removeFirst()删除第一个元素并返回: " + linkedList.removeFirst()); // 移除并返回此列表的第一个元素
System.out.println("removeLast()删除最后一个元素并返回: " + linkedList.removeLast()); // 移除并返回此列表的最后一个元素
System.out.println("After remove:" + linkedList);
System.out.println("contains()方法判断列表是否包含1这个元素:" + linkedList.contains(1)); // 判断此列表包含指定元素,如果是,则返回true
System.out.println("该linkedList的大小 : " + linkedList.size()); // 返回此列表的元素个数
/************************** 位置访问操作 ************************/
System.out.println("-----------------------------------------");
linkedList.set(1, 3); // 将此列表中指定位置的元素替换为指定的元素
System.out.println("After set(1, 3):" + linkedList);
System.out.println("get(1)获得指定位置(这里为1)的元素: " + linkedList.get(1)); // 返回此列表中指定位置处的元素
/************************** Search操作 ************************/
System.out.println("-----------------------------------------");
linkedList.add(3);
System.out.println("indexOf(3): " + linkedList.indexOf(3)); // 返回此列表中首次出现的指定元素的索引
System.out.println("lastIndexOf(3): " + linkedList.lastIndexOf(3));// 返回此列表中最后出现的指定元素的索引
/************************** Queue操作 ************************/
System.out.println("-----------------------------------------");
System.out.println("peek(): " + linkedList.peek()); // 获取但不移除此列表的头
System.out.println("element(): " + linkedList.element()); // 获取但不移除此列表的头
linkedList.poll(); // 获取并移除此列表的头
System.out.println("After poll():" + linkedList);
linkedList.remove();
System.out.println("After remove():" + linkedList); // 获取并移除此列表的头
linkedList.offer(4);
System.out.println("After offer(4):" + linkedList); // 将指定元素添加到此列表的末尾
/************************** Deque操作 ************************/
System.out.println("-----------------------------------------");
linkedList.offerFirst(2); // 在此列表的开头插入指定的元素
System.out.println("After offerFirst(2):" + linkedList);
linkedList.offerLast(5); // 在此列表末尾插入指定的元素
System.out.println("After offerLast(5):" + linkedList);
System.out.println("peekFirst(): " + linkedList.peekFirst()); // 获取但不移除此列表的第一个元素
System.out.println("peekLast(): " + linkedList.peekLast()); // 获取但不移除此列表的第一个元素
linkedList.pollFirst(); // 获取并移除此列表的第一个元素
System.out.println("After pollFirst():" + linkedList);
linkedList.pollLast(); // 获取并移除此列表的最后一个元素
System.out.println("After pollLast():" + linkedList);
linkedList.push(2); // 将元素推入此列表所表示的堆栈(插入到列表的头)
System.out.println("After push(2):" + linkedList);
linkedList.pop(); // 从此列表所表示的堆栈处弹出一个元素(获取并移除列表第一个元素)
System.out.println("After pop():" + linkedList);
linkedList.add(3);
linkedList.removeFirstOccurrence(3); // 从此列表中移除第一次出现的指定元素(从头部到尾部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
linkedList.removeLastOccurrence(3); // 从此列表中移除最后一次出现的指定元素(从尾部到头部遍历列表)
System.out.println("After removeFirstOccurrence(3):" + linkedList);
/************************** 遍历操作 ************************/
System.out.println("-----------------------------------------");
linkedList.clear();
for (int i = 0; i < 100000; i++) {
linkedList.add(i);
}
// 迭代器遍历
long start = System.currentTimeMillis();
Iterator<Integer> iterator = linkedList.iterator();
while (iterator.hasNext()) {
iterator.next();
}
long end = System.currentTimeMillis();
System.out.println("Iterator:" + (end - start) + " ms");
// 顺序遍历(随机遍历)
start = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); i++) {
linkedList.get(i);
}
end = System.currentTimeMillis();
System.out.println("for:" + (end - start) + " ms");
// 另一种for循环遍历
start = System.currentTimeMillis();
for (Integer i : linkedList)
;
end = System.currentTimeMillis();
System.out.println("for2:" + (end - start) + " ms");
// 通过pollFirst()或pollLast()来遍历LinkedList
LinkedList<Integer> temp1 = new LinkedList<>();
temp1.addAll(linkedList);
start = System.currentTimeMillis();
while (temp1.size() != 0) {
temp1.pollFirst();
}
end = System.currentTimeMillis();
System.out.println("pollFirst()或pollLast():" + (end - start) + " ms");
// 通过removeFirst()或removeLast()来遍历LinkedList
LinkedList<Integer> temp2 = new LinkedList<>();
temp2.addAll(linkedList);
start = System.currentTimeMillis();
while (temp2.size() != 0) {
temp2.removeFirst();
}
end = System.currentTimeMillis();
System.out.println("removeFirst()或removeLast():" + (end - start) + " ms");
}
}
下面介绍LinkedList实现Deque接口的方法
public class Test {
public static void main(String[] args) {
Deque<Integer> deq = new LinkedList();
deq.add(1);
deq.add(2);
deq.add(3);
deq.add(4);
deq.add(5);
System.out.println(deq); // [1, 2, 3, 4, 5]
//1. peek()和element()方法 都是获取(不移除此双端队列)队列的头部
// 区别:peek(),如果链表为空,则返回null。element(),如果链表为空,则抛异常。
System.out.println(deq.peek()); // 1
System.out.println(deq.element()); // 1
//2. peekFirst() 获取但不移除此列表的第一个元素;如果此列表为空,则返回 null。
// peekLast() 获取但不移除此列表的最后一个元素;如果此列表为空,则返回 null。
System.out.println(deq.peekFirst()); //1
System.out.println(deq.peekLast()); //5
//3. poll() pop() 获取并移除此列表的头(第一个元素) pop()出栈 push压栈
// poll()和 pop()区别: 如果此列表为空,pop()抛出NoSuchElementException,poll()则返回 null
System.out.println(deq.poll()); //1
System.out.println(deq); //[2, 3, 4, 5]
System.out.println(deq.pop()); //2
System.out.println(deq); //[3, 4, 5]
//4. pollFirst() 获取并移除此列表的第一个元素;如果此列表为空,则返回 null。
// pollLast() 获取并移除此列表的最后一个元素;如果此列表为空,则返回 null。
System.out.println(deq.pollFirst()); //3
System.out.println(deq.pollLast()); //5
//5 push(E e) 将元素推入此列表所表示的堆栈 ,
// 如果成功,则返回 true,如果当前没有可用空间,则抛出 IllegalStateException。
deq.push(520131);
System.out.println(deq); //[520131, 4]
}
}
13、HashSet类实现原理
HashSet实际上是一个HashMap实例,都是一个存放链表的数组。它不保证存储元素的迭代顺序;此类允许使用null元素。HashSet中不允许有重复元素,这是因为HashSet是基于HashMap实现的,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个固定对象private static final Object PRESENT = new Object();
HashSet中add方法调用的是底层HashMap中的put()方法,而如果是在HashMap中调用put,首先会判断key是否存在,如果key存在则修改value值,如果key不存在这插入这个key-value。而在set中,因为value值没有用,也就不存在修改value值的说法,因此往HashSet中添加元素,首先判断元素(也就是key)是否存在,如果不存在这插入,如果存在着不插入,这样HashSet中就不存在重复值。
所以判断key是否存在就要重写元素的类的equals()和hashCode()方法,当向Set中添加对象时,首先调用此对象所在类的hashCode()方法,计算次对象的哈希值,此哈希值决定了此对象在Set中存放的位置;若此位置没有被存储对象则直接存储,若已有对象则通过对象所在类的equals()比较两个对象是否相同,相同则不能被添加。
package HashSet类的常用方法;
import java.util.AbstractSet;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class Test3 {
public static void main(String[] args) {
//继承关系: class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable
/*1. 字段
//基于HashMap实现,底层使用HashMap保存所有元素
private transient HashMap<E,Object> map;
//定义一个Object对象作为HashMap的value
private static final Object PRESENT = new Object();
*/
/*2. 构造方法
2.1//初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75。
public HashSet() {
map = new HashMap<>();
}
2.2// 构造一个包含指定 collection 中的元素的新 set。
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
2.3//构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
2.4//构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
2.5 在API中我没有看到这个构造函数,今天看源码才发现(原来访问权限为包权限,不对外公开的)
* 以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
* dummy 为标识 该构造函数主要作用是对LinkedHashSet起到一个支持作用
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
*/
/*3.普通方法
* 前言:HashSet的方法和ArrayList的方法大同小异,差别在于:
HashSet是无序的,所以涉及到index索引的方法在HashSet里面都没有.
*/
HashSet set1 = new HashSet();
HashSet set2 = new HashSet();
for (int i = 0; i < 4; i++) {
set1.add(i); //[0, 1, 2, 3]
}
for (int i = 2; i < 6; i++) {
set2.add(i); //[2, 3, 4, 5]
}
set1.add(set2);
System.out.println(set1); //[0, 1, 2, 3, [2, 3, 4, 5]]
set1.addAll(set2);
System.out.println(set1); //[0, 1, 2, 3, 4, 5, [2, 3, 4, 5]]
//迭代器遍历
Iterator iterator = set1.iterator();
while(iterator.hasNext()){
Object next = iterator.next();
System.out.print(next); //012345[2, 3, 4, 5]
}
System.out.println(set1.contains(3)); //true
set1.remove(set2);
System.out.println(set1); //[0, 1, 2, 3, 4, 5]
set1.clear();
System.out.println(set1); //[]
}
}
14、TreeSet实现原理及源码分析
TreeSet是Set接口的子接口SortedSet的唯一的实现类,TreeSet对其中的元素进行排序。
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, Serializable
可以看到TreeSet继承了AbstractSet并实现了NavigableSet、Cloneable和Serializable等接口,其中NavigableSet接口是基于TreeMap实现的,他需要依赖元素的自然排序或者传入一个定制的comparator比较器,这样才能实现元素之间的比较并对元素进行排序,如果一个类并没有实现Comparable接口并重写comparaTo()方法,那么在添加到TreeSet时会抛出java.langClassCastException。
1、TreeSet和TreeMap的关系
TreeSet是基于TreeMap实现的,而TreeMap是基于红黑树的数据结构实现的,也就是自平衡的排序二叉树,那么TreeSet也是基于红黑树的树结构实现的,通过TreeSet的构造方法就可以看出,TreeSet就是特殊的TreeMap,而且TreeSet中很多方法都是基于TreeMap中的方法实现的。
TreeSet的构造方法:
private transient NavigableMap<E,Object> m; //使用一个可序列化的NavigableMap来实现TreeSet
// 使用一个特定的不可更改的Object来作为TreeMap的value
private static final Object PRESENT = new Object();
//构造器1,直接传入一个NavigableMap来实现TreeSet
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
//构造器2
//传入一个TreeMap来实现TreeSet,根据自然排序来实现元素间的比较和排序,因此插入的元素必须实现Comparabel接口并实现comparaTo()方法
//并且传入的元素的compareTo()方法的结果必须是一致的,否则会抛出ClassCastException
public TreeSet() {
this(new TreeMap<E,Object>());
}
//构造器3
//传入一个构造器,使用构造器2,并向TreeMap中传入比较器Comparator,在添加元素的时候,使用Comparator接口的Compara()方法对元素进行比较
//和排序
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
//构造器4
//使用构造器1,并把Collection c中的元素添加到TreeSet中
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
//利用构造器3,将排序集的比较器传入,并将排序集s中的元素添加到TreeSet中
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
从TreeSet的构造函数中可以看出,TreeSet就是value为不可变的Object对象的TreeMap。
此外,TreeSet中的很多函数都是基于TreeMap中的函数实现的,例如:
迭代器:
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
isEmpty()方法:
public boolean isEmpty() {
return m.isEmpty();
}
还有很多方法都是这样基于TreeMap实现的,具体可以看TreeSet的源码。
2、元素的排序方式
TreeSet的元素排序的两种方式:自然排序(Comparable接口)和定制比较器(comparator接口)
自然排序:对于实现了comparable接口的对象,在被添加进TreeSet的时候,TreeSet会把该对象提升为Comparable类型,并调用comparaTo()方法,根据方法的返回值进行排序。
定制比较器comparator:在创建TreeSet的时候,可以传入定制的比较器Comparator,如果传入了Comparator的子类对象,Tadd()方法的内部会自动调用Comparator接口中的compare()方法,调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数。
*TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException),TreeSet如果传入Comparator, 就优先按照Comparator的顺序比较
comparable和comparator的区别:
Comparable:此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法。
他们都是用来实现集合中元素的比较、排序的,只是comparable是在集合内部定义的方法实现的排序,而comparator是在集合外部实现的排序。
comparator位于包java.util下,而comparable位于包java.lang下。
package TreeSet类的常用方法;
public class Test4 {
public static void main(String[] args) {
//1.继承关系
/* public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
*/
//2.变量
/* private transient NavigableMap<E,Object> m;
//PRESENT会被当做Map的value与key构建成键值对
private static final Object PRESENT = new Object();
*/
//3.构造方法
/* //3.1默认构造方法,根据其元素的自然顺序进行排序
public TreeSet() {
this(new TreeMap<E,Object>());
}
//3.2构造一个包含指定 collection 元素的新 TreeSet,它按照其元素的自然顺序进行排序。
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
//3.3构造一个新的空 TreeSet,它根据指定比较器进行排序。
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
//3.4构造一个与指定有序 set 具有相同映射关系和相同排序的新 TreeSet。
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
//3.5
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
*/
//4.主要方法
/* 1、add:将指定的元素添加到此 set(如果该元素尚未存在于 set 中)。
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
2、addAll:将指定 collection 中的所有元素添加到此 set 中。
public boolean addAll(Collection<? extends E> c) {
// Use linear-time version if applicable
if (m.size()==0 && c.size() > 0 &&
c instanceof SortedSet &&
m instanceof TreeMap) {
SortedSet<? extends E> set = (SortedSet<? extends E>) c;
TreeMap<E,Object> map = (TreeMap<E, Object>) m;
Comparator<? super E> cc = (Comparator<? super E>) set.comparator();
Comparator<? super E> mc = map.comparator();
if (cc==mc || (cc != null && cc.equals(mc))) {
map.addAllForTreeSet(set, PRESENT);
return true;
}
}
return super.addAll(c);
}
3、ceiling:返回此 set 中大于等于给定元素的最小元素;如果不存在这样的元素,则返回 null。
public E ceiling(E e) {
return m.ceilingKey(e);
}
4、clear:移除此 set 中的所有元素。
public void clear() {
m.clear();
}
5、clone:返回 TreeSet 实例的浅表副本。属于浅拷贝。
public Object clone() {
TreeSet<E> clone = null;
try {
clone = (TreeSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.m = new TreeMap<>(m);
return clone;
}
6、comparator:返回对此 set 中的元素进行排序的比较器;如果此 set 使用其元素的自然顺序,则返回 null。
public Comparator<? super E> comparator() {
return m.comparator();
}
7、contains:如果此 set 包含指定的元素,则返回 true。
public boolean contains(Object o) {
return m.containsKey(o);
}
8、descendingIterator:返回在此 set 元素上按降序进行迭代的迭代器。
public Iterator<E> descendingIterator() {
return m.descendingKeySet().iterator();
}
9、descendingSet:返回此 set 中所包含元素的逆序视图。
public NavigableSet<E> descendingSet() {
return new TreeSet<>(m.descendingMap());
}
10、first:返回此 set 中当前第一个(最低)元素。
public E first() {
return m.firstKey();
}
11、floor:返回此 set 中小于等于给定元素的最大元素;如果不存在这样的元素,则返回 null。
public E floor(E e) {
return m.floorKey(e);
}
12、headSet:返回此 set 的部分视图,其元素严格小于 toElement。
public SortedSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
13、higher:返回此 set 中严格大于给定元素的最小元素;如果不存在这样的元素,则返回 null。
public E higher(E e) {
return m.higherKey(e);
}
14、isEmpty:如果此 set 不包含任何元素,则返回 true。
public boolean isEmpty() {
return m.isEmpty();
}
15、iterator:返回在此 set 中的元素上按升序进行迭代的迭代器。
public Iterator<E> iterator() {
return m.navigableKeySet().iterator();
}
16、last:返回此 set 中当前最后一个(最高)元素。
public E last() {
return m.lastKey();
}
17、lower:返回此 set 中严格小于给定元素的最大元素;如果不存在这样的元素,则返回 null。
public E lower(E e) {
return m.lowerKey(e);
}
18、pollFirst:获取并移除第一个(最低)元素;如果此 set 为空,则返回 null。
public E pollFirst() {
Map.Entry<E,?> e = m.pollFirstEntry();
return (e == null) ? null : e.getKey();
}
19、pollLast:获取并移除最后一个(最高)元素;如果此 set 为空,则返回 null。
public E pollLast() {
Map.Entry<E,?> e = m.pollLastEntry();
return (e == null) ? null : e.getKey();
}
20、remove:将指定的元素从 set 中移除(如果该元素存在于此 set 中)。
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
21、size:返回 set 中的元素数(set 的容量)。
public int size() {
return m.size();
}
22、subSet:返回此 set 的部分视图
返回此 set 的部分视图,其元素范围从 fromElement 到 toElement。
public NavigableSet<E> subSet(E fromElement, boolean fromInclusive,
E toElement, boolean toInclusive) {
return new TreeSet<>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
//返回此 set 的部分视图,其元素从 fromElement(包括)到 toElement(不包括)。
public SortedSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
23、tailSet:返回此 set 的部分视图
返回此 set 的部分视图,其元素大于(或等于,如果 inclusive 为 true)fromElement。
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new TreeSet<>(m.tailMap(fromElement, inclusive));
}
//返回此 set 的部分视图,其元素大于等于 fromElement。
public SortedSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
*/
}
}
15、Hashtable与HashMap的区别
- 继承的父类不同。Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
- 线程安全性不同。HashTable的方法是同步的,HashMap不支持线程的同步,即任一时刻可以有多个线程同时写HashMap;可能会导致数据的不一致。如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力.,这个区别就像Vector和ArrayList一样。
- key和value是否允许null值。 HashTable的key和value都不允许null值。 HashMap的 key 和 value 允许null值, 但是key值只能有一个null值,允许多条记录的值为Null。因为hashmap如果key值相同,新的key, value将替代旧的。
- 是否提供contains方法。 HashMap包含了containsvalue和containsKey 方法,不包含有contains,而 HashTable只有一个 contains(Object value) 功能 和 HashMap中的 containsValue(Object value)功能一样。
- 内部实现使用的数组初始化和扩容方式不同。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
- hash值不同。哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
16、hashmap和treemap什么区别?
无序: 不保证元素迭代顺序是按照插入时的顺序。
1. 底层实现不同。HashMap:数组方式存储key/value 。TreeMap:基于红黑二叉树的NavigableMap的实现,两个线程都不安全
2. HashMap 键允许为空,TreeMap键不能为空。
3.判断重复元素(指的键)不同,HashMap的键重复标准为重写equals() 和HashCode() , TreeMap 的键重复标准是比较器返回为0.
存入TreeMap的元素应当实现Comparable接口或者实现Comparator接口,两个相比较的key不得抛出classCastException。主要用于存入元素的时候对元素进行自动排序,迭代输出的时候就按排序顺序输出
4.TreeMap无序的,保存的记录根据键排序,默认是升序排序,也可以指定排序的比较器,当用Iterator 遍历TreeMap时,得到的记录是排过序的。而HashMap 是无须的 ,自然排序。
5.TreeMap添加的类型取决于第一个添加的键的类型(加上泛型就没有区别了)
参考链接:
https://www.cnblogs.com/chenssy/
https://www.jianshu.com/p/02a0e2947d47
https://www.cnblogs.com/dolphin0520/p/3933551.html

