python数据库操作及爬取大学排名。
直接上代码:
# -*- coding: utf-8 -*- """ Created on Thu May 30 10:22:37 2019 @author: 小米 """ import csv import os import requests import pandas from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = 'utf-8' return r.text except: return "" def fillUnivList(soup): data = soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def writercsv(save_road,num,title): if os.path.isfile('test_launch1.csv'): with open('test_launch1.csv','a',newline='')as f: csv_write=csv.writer(f,dialect='excel') for i in range(num): u=allUniv[i] csv_write.writerow(u) else: with open('test_launch1.csv','w',newline='')as f: csv_write=csv.writer(f,dialect='excel') csv_write.writerow(title) for i in range(num): u=allUniv[i] csv_write.writerow(u) title=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研究合作","成果转化"] save_road="C:pachong.csv" def main(): url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html' html = getHTMLText(url) soup = BeautifulSoup(html, "html.parser") fillUnivList(soup) writercsv(save_road,10,title) main()
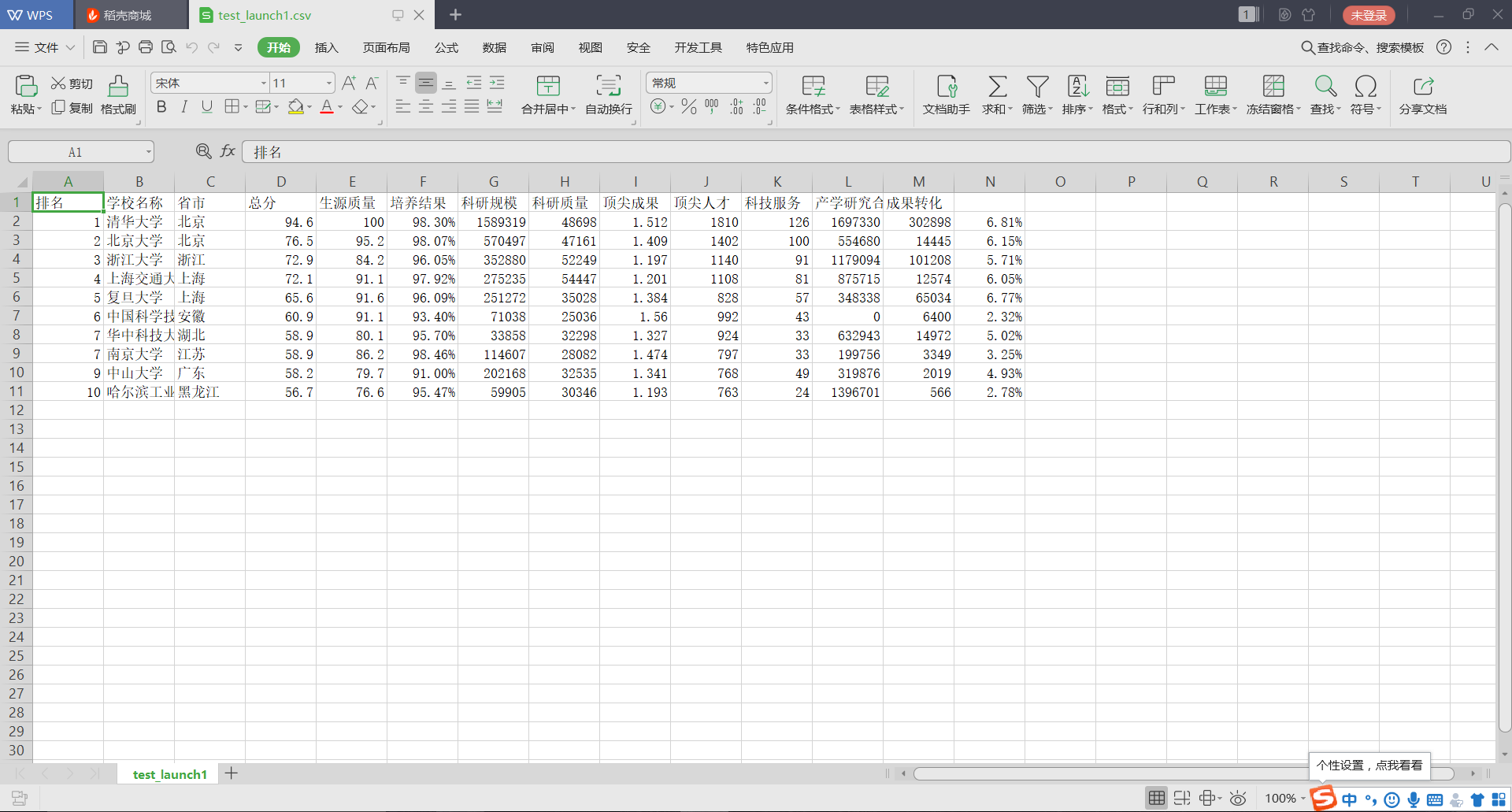
运行结果如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号