运用jieba库分词并生成词云库。
话不多说,直接上代码。
import jieba
txt = open("C:\\Users\\Administrator\\Desktop\\流浪地球","r", encoding='utf-8').read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
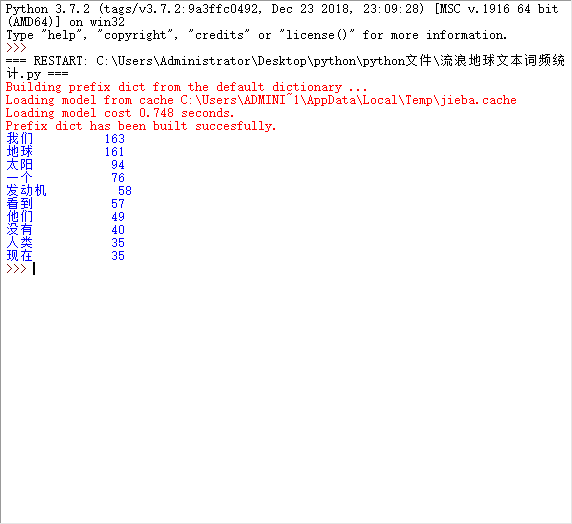
for i in range(15):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))
def create_word_cloud(filename):
text = open("{}.txt".format(filename)).read()
# 结巴分词
wordlist = jieba.cut(text, cut_all=True)
wl = " ".join(wordlist)
# 设置词云
wc = WordCloud(
# 设置背景颜色
background_color="white",
max_words=2000,
font_path='C:\Windows\Fonts\simfang.ttf',
height=1200,
width=1600,
max_font_size=200,
random_state=100,
)
myword = wc.generate(wl)
plt.imshow(myword)
plt.axis("off")
plt.show()
wc.to_file('p.png')
if __name__ == '__main__':
create_word_cloud('C:\\Users\\Administrator\\Desktop\\阿Q正传')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号