

- 需求
爬起链家深圳二手房的详情信息,存储到excel表中.并对深圳二手房数据进行分析
以下数据只是简单的获取第一页的二手房源信息,通过xlwt写入excel并保存
from lxml import etree
import requests
import xlwt
import re
# 1.构造url列表
# 2.遍历,发送请求,获取响应
# 3.保存
url="https://sz.lianjia.com/ershoufang/rs%E6%B7%B1%E5%9C%B3/"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
# 获取页面源码数据
page_text = requests.get(url=url,headers=headers).text
# 实例化etree对象进行数据解析
tree=etree.HTML(page_text)
li_list = tree.xpath('//*[@id="content"]/div[1]/ul/li')
all_house_lst=list()
for li in li_list:
detail_url=li.xpath('./div[1]/div[1]/a/@href')[0]
title=li.xpath('./div[1]/div[1]/a/text()')
name=li.xpath('./div[1]/div[2]/div/a[1]/text()')
price=li.xpath('./div[1]/div[6]/div[1]/span/text()')
unitprice=li.xpath('./div[1]/div[6]/div[2]/span/text()')
desc=li.xpath('./div[1]/div[3]/div/text()')
# print(title)
# print(price)
# print(desc)
# print(unitprice)
# print(name)
# 将爬取到的所有二手房的详细信息整合到house列表中
house_dic ={"title":title,"name":name,"desc":desc,"price":price,
"unitprice":unitprice,"detail_url":detail_url}
all_house_lst.append(house_dic)
# house_list=[title,name,desc,price,unitprice,detail_url]
print(all_house_lst)
#将数据列表存储到Excel表格Lianjia_I.xlsx中
workBook = xlwt.Workbook(encoding="utf-8")
sheet = workBook.add_sheet("Lianjia")
headData = ["标题","小区名称", "详情", "价格(万)", "单价","链接"]
# 写入表头
for col in range(len(headData)):
sheet.write(0, col, headData[col])
title_rows = 1
for i in range(len(all_house_lst)):
dic = all_house_lst[i]
sheet.write(title_rows+i,0,dic["title"])
sheet.write(title_rows+i,1,dic["name"])
sheet.write(title_rows+i,2,dic["desc"])
sheet.write(title_rows+i,3,dic["price"])
sheet.write(title_rows+i,4,dic["unitprice"])
sheet.write(title_rows+i,5,dic["detail_url"])
workBook.save(".\Lianjia_I.xls")

以下将上面的函数做进一步封装通过pandas写入csv并保存数据
from lxml import etree
import requests
import pandas as pd
"""
1.构造url列表
2.遍历,发送请求,获取响应
3.保存
"""
class LianjiaSpider():
def __init__(self):
self.headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
self.url="https://sz.lianjia.com/ershoufang/rs%E6%B7%B1%E5%9C%B3/"
def get_url_list(self):
url_list = [self.url.format(i) for i in range(1, 101)]
return url_list
def parse_html(self,url):
page_text = requests.get(url,headers=self.headers).text
return page_text
def get_data(self,page_text):
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="content"]/div[1]/ul/li')
data = pd.DataFrame(columns=["标题","小区名称", "详情", "价格(万)", "单价","链接"])
for li in li_list:
info_dicts = {}
info_dicts["标题"] = li.xpath('./div[1]/div[1]/a/text()')
info_dicts["小区名称"] = li.xpath('./div[1]/div[2]/div/a[1]/text()')
info_dicts["详情"] = li.xpath('./div[1]/div[3]/div/text()')
info_dicts["价格(万)"] = li.xpath('./div[1]/div[6]/div[1]/span/text()')
info_dicts["单价"] = li.xpath('./div[1]/div[6]/div[2]/span/text()')
info_dicts["链接"] = li.xpath('./div[1]/div[1]/a/@href')
df = pd.DataFrame(info_dicts, index=[0])
data = data.append(df)
return data
def run(self):
save_data = pd.DataFrame(columns=["标题","小区名称", "详情", "价格(万)", "单价","链接"])
url_list = self.get_url_list()
for url in url_list:
# 2.发送请求,获取响应
page_text = self.parse_html(url)
# 3.获取所需要的数据
data = self.get_data(page_text)
# 4.保存数据
save_data = save_data.append(data)
save_data.to_csv('./链家深圳二手房房源数据.csv', index=False,encoding='utf-8')
if __name__ == '__main__':
lianjia = LianjiaSpider()
lianjia.run()

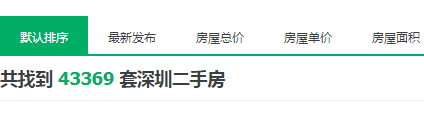
通过爬取数据发现即使我们通过遍历页数达到翻页100页的效果也只能拿到数据3000条,与其提示的数据信息43369数据量还差的很多.我们发现通过区域检索的时候有些区域二手房数量也会超过3000条,这样我们必须还得继续按照区域下面的划分进行逐一爬取,比较麻烦暂不放代码了,爬取的思路是相同的



import requests from bs4 import BeautifulSoup import pandas as pd import xlwt headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36", "Cookie": "admckid=1810201905171489967; mapping_hist=szeJ.T08vNTMyvykjNKylKTM7WM.Q1M.MwMTY2NwAAeF0H_g**; viewlist=szeJxlkwuOhDAMQ29Uxfnn_hdbt4UV0oiRmMLDNXZYCwh3LB0RF1-yuObfRPVSLi2n.VRE14JCm5fghp7DBrpc0AubFY0RC-vNWpsuU1V_WQv1Cr260imQbm.Wu5Nshqs_LKWiZO2lSomEJrYu0svo10dUL5sqs18Cv7rJ16BUaOGyA5eQL2vuvtnJqGUh1JXD7gyGv-OX.hsotYMyoGW-T1c2jU-5XruPBSZ6WM_essZ8L6vJjEaOBZRM8cirm37YCeRlmZdn.i9rtwrqRN.IskNpPVfs5bi0SFsddtdl0eb0f9hw5EQ_fjV6RnWOB3bA1gMVj4dpjkQY750ckPRxqlA-Rd0uZF-WaTFtCvH-GwQT2EEY92e-2YOpCwPsveI.D6a2e.MWx4DLU_5ZFl7wh72GcQwjOW-GYI93.op9D6fvO5PWm7UsbmedsGceqg0M4-vh9cvBpi5DUrsBN.fk1VvcM5OVelhVkC1-CVe3WbfVHtR6P6KilP8BSDCuxg**"} city=["luohuqu","futianqu","nanshanqu","yantianqu","baoanqu","longgangqu","longhuauqu","pingshanqu","dapengxinqu","guangmingqu"] for i in city: url="https://sz.lianjia.com/ershoufang/%s" % i # print(url) page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(page_text,"html.parser") pages = soup.find("div",class_="page-box house-lst-page-box")["page-data"] maxPage = eval(pages)["totalPage"] # print(maxPage) for i in range(1,maxPage): url_page=url+"/pg{}".format(i) response = requests.get(url=url_page,headers=headers).text soup=BeautifulSoup(response,"lxml") detail_url_list = soup.find_all("div", class_ = "info clear") datas=list() for i in detail_url_list: detail_url = i.find("a")["href"] # print(detail_url) detail_text= requests.get(url=detail_url,headers=headers).text soup=BeautifulSoup(detail_text,"lxml") data={} # headData = ["addr", "price", "unitprice", "housestyle", "floor", "orietation", "area", "year", "info", # "subway"] # 获取价格 price=soup.select('body > div.overview > div.content > div.price > span.total') for price in price: data["price"]=price.get_text() # 获取单价 unitprice = soup.select('body > div.overview > div.content > div.price > div.text > div.unitPrice > span') for unitprice in unitprice: data["unitprice"]=unitprice.get_text() # 获取户型 housestyle = soup.select('body > div.overview > div.content > div.houseInfo > div.room > div.mainInfo') for housestyle in housestyle: data["housestyle"]=housestyle.get_text() # 获取楼层 floor=soup.select('body > div.overview > div.content > div.houseInfo > div.room > div.subInfo') for floor in floor: data['floor']=floor.get_text() # 获取朝向 orietation = soup.select('body > div.overview > div.content > div.houseInfo > div.type > div.mainInfo') for orietation in orietation: data["orietation"]=orietation.get_text() # 获取面积 area=soup.select('body > div.overview > div.content > div.houseInfo > div.area > div.mainInfo') for area in area: data['area']=area.get_text() # 获取建筑时间 year=soup.select('body > div.overview > div.content > div.houseInfo > div.area > div.subInfo') for year in year: data['year']=year.get_text() # 获取地址 addr=soup.select('body > div.overview > div.content > div.aroundInfo > div.communityName > a.info') for addr in addr: data['addr']=addr.get_text() # 获取区域 info = soup.select('body > div.overview > div.content > div.aroundInfo > div.areaName > span.info > a:nth-child(1)') for info in info: data["info"]=info.get_text() # 获取地铁 subway = soup.select('body > div.overview > div.content > div.aroundInfo > div.areaName > span.info > a:nth-child(2)') for subway in subway: data["subway"]=subway.get_text() # df = pd.DataFrame(data, index=[0]) # datas = headData.append(df) # print(data) datas.append(data) # print(datas) workBook = xlwt.Workbook(encoding="utf-8") sheet = workBook.add_sheet("Lianjia") headData = ["addr","price","unitprice","housestyle","floor","orietation","area","year","info","subway"] for col in range(len(headData)): sheet.write(0, col, headData[col]) title_rows = 1 for i in range(len(datas)): dic = datas[i] sheet.write(title_rows + i, 7, dic["addr"]) sheet.write(title_rows + i, 0, dic["price"]) sheet.write(title_rows + i, 1, dic["unitprice"]) sheet.write(title_rows + i, 2, dic["housestyle"]) sheet.write(title_rows + i, 3, dic["floor"]) sheet.write(title_rows + i, 4, dic["orietation"]) sheet.write(title_rows + i, 5, dic["area"]) sheet.write(title_rows + i, 6, dic["year"]) sheet.write(title_rows + i, 8, dic["info"]) sheet.write(title_rows + i, 9, dic["subway"]) workBook.save(".\Lianjia_I.xls")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号