
理解操作系统3——内存模型和地址空间
一、从分层存储器体系谈起
根据冯诺依曼计算机体系结构,计算机是以存储器为核心的。
分为五大部件:运算器、控制器、存储器、输入设备、输出设备。
存储器又包括寄存器、内存;CPU整合了寄存器、运算器、控制器;输入输出设备统称I/O设备(外部存储器即磁盘也属于I/O范畴);
内存(RAM)是计算机系统中重要的资源。内存属于掉电易失性。
经过整合一下,计算机大概分层这三大组件:CPU(还包括缓存Cache)、内存、I/O设备(磁盘属于I/O设备的一种);
操作系统是怎样对内存创建抽象模型并且怎样管理内存呢?
另外又不得不先提到一个概念存储管理。人们提出了分层存储器体系。
理想情况下,人们希望有这样一个存储器:私有的、容量无限大、速度无限快,并且是永久性掉电不易失的。
很遗憾目前没有这种的技术手段去实现这一目标。存储系统层次存储体系的提出就是解决这个矛盾的。
综合考虑了容量、速度、成本三大因素。
以存储器为核心的计算机系统结构当然希望存储器与运算器/控制器交换数据的速度越快越好,最好和运算器/控制器的运行速度一样快。
显然数据交换速度成了制约运行效率的重要因素。
寄存器的速度是最快的,然后是缓存的速度,再后面是内存,最慢的是磁盘。速度一次递减;
但是越靠近CPU,速度越高,其成本越高,造价越高也就限制了容量的大小。
寄存器的容量最小,然后缓存大一些,但还是不够大,可能就几十M。再后面是内存,可以做到几个G。最后是磁盘可以做到几百G;
不过利用程序的局部性原理,尽量将CPU此时可能大概率访问到的少量数据放到寄存器、缓存中。这样就减少CPU和低速率存储器的数据交换,也就能提高计算机整体的运行速率了。
这是利用这种局部性和存储器分层体系,很好地解决了容量、成本、速度三者的矛盾关系。达到了某种程度的平衡。
那么操作系统是如何适配这个存储器分层体系的?->操作系统的工作就是将这个体系抽象为一个有用的模型,并管理这个模型;
寄存器已经融入了CPU当中,当然是由CPU来管理。
高速缓存也是很底层的东西,直接交给硬件来完成就好了,也是融入到了CPU当中。
内存:一般是一个独立的器件,掉电易失的。操作系统整理建立了对内存的模型来管理内存这一重要资源,并且不断优化管理内存;-->也就是我们要讨论的内存模型了
磁盘:磁盘是大容量、低速、非易失性存储器,操作也将它们做了抽象并加以管理。也就是文件系统了。
====================================================
二、为什么需要存储器抽象,即为什么需要内存模型?
我们来试想一个没有存储器抽象的计算机是什么样的?
那么呈现给编程人员的存储器模型就是一个简单的物理内存。即从0到某个上限的地址集合。
每个地址(映射)对应着一个可容纳一定数目的二进制位的存储单元,通常是8个,即一个字节。
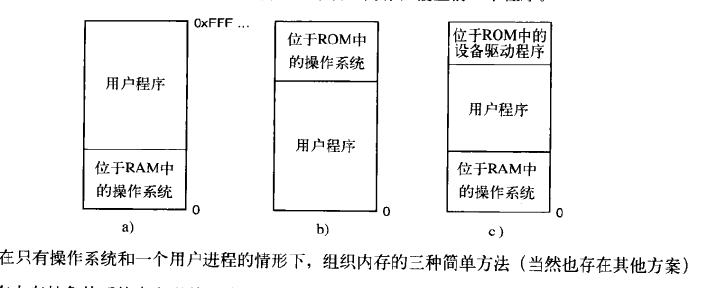
a方案在当时被用在大型机和小型计算机上;
b方案被用在掌上电脑和嵌入式系统中;
c方案被用于早期的个人计算机。
a、c的方案缺点是用户程序可能出现错误并摧毁操作系统。因为操作系统的地址空间是它们能够访问得到并且修改的。
另外不适用内存抽象的情况下运行多道程序也是可能的。操作系统只需要把当前内存中所有内容保存到磁盘文件中。然后把下一个程序读入到内存中即可。
在某一个时间内存中只有一个程序,那么久不会发生冲突。这就有点类似于交换的概念了。
当然不采用交换也可以实现在内存中运行多道程序,IBM 360早期模型是这样解决的,内存被划分称为2KB的块,然后每个块被分配一个4位保护键。保存键存储在CPU的特殊寄存器中。保护键来控制程序对内存的访问。只有操作系统可以修改保护键。如果一个运行中的进程其访问保护键与其PSW码不同的话,硬件就会捕捉到这一事件,防止其访问这部分内存。但是这个方法还是有缺陷,由于程序本身引用的都是绝对物理地址,所以有可能跳转到不正确的地方。IBM 360的补救措施是在程序装载的时候,使用静态重定位技术修改地址。但是这种方式又降低了程序装载的速度。
在同时打开多个程序的情况下,直接暴露物理地址给程序去寻址是十分危险的。它们很容易地破坏操作系统。
这就需要让每个程序都是用一套私有的地址空间来进行内存寻址,既可以起到保护内存空间的作用,又不影响装载速度。
为了保证多个应用程序同时处于内存中并且不相互影响,需要解决两个问题:保护、重定位。
一个更好的办法是创造一种对内存的抽象->地址空间。
地址空间创造了一种抽象的内存。地址空间是一个进程可用于寻址内存的一套地址集合。每个进程都有自己的地址空间。
并且这个地址空间独立于其他进程的地址空间。除了一些特殊情况下,进程需要共享它们的地址空间外。
====================================================
三、如何实现内存抽象——内存是怎样被管理的?
以前应用程序都是直接运行在物理内存上,访问的都是物理地址,这会导致地址空间不隔离,容易造成内存崩溃的各种风险,甚至影响操作系统本身。而且程序运行时的地址就很不确定。
所以对内存和使用和分配就很重要,如何将计算机上有限的物理内存分配给多个程序使用,以发挥出内存最大的效率?
静态的重定位技术,即在装载时确定最终的物理地址,会导致装载速率较慢的问题。
但是在多道编程环境下,无法将程序总是加到固定的内存地址上,也就是无法使用静态地址翻译。
因此,必须在程序装载完毕之后才能计算物理地址,也就是在程序运行时才进行地址翻译,这种翻译称为动态地址翻译,也就是动态重定位技术。
最初实现地址空间的方式是使用一种简单的动态重定位技术。简单来说就是把每个进程的地址空间映射到物理内存的不同部分。
使用的经典方法是给每个CPU配置两个特殊的硬件寄存器——基址寄存器和界限寄存器;
当一个进程运行时,程序的起始物理地址被装载到基址寄存器中,程序的长度被装载到界限寄存器中。
例如当第一个程序运行时,基址和界限值分别为0和16384;当第二个程序运行时,基址和界限值分别是16384和32768;
每次一个进程访问内存,取一条指令,读或写一个数据字时,CPU硬件会把地址发送到内存总线前,自动把基址值加到进程发出的地址值上。然后检查是否超出了界限寄存器的值。
如果超出了,就会产生错误并终止访问。这种方法有个缺点就是每次访问内存都需要进行加法和比较运算,效率是比较差的。
目前的解决方法就是在物理地址和应用程序之间增加一个中间层——虚拟地址(Virtural Address)。
应用程序只需要关心虚拟地址空间,然后操作系统负责将虚拟地址映射成实际的物理地址。->用一个专门的硬件取管理地址的映射,这就叫做MMU(Memory Management Unit),通常被集成到CPU中,不作为独立器件存在。
只要妥善地控制这个虚拟地址到物理地址的映射过程,就能保证各个应用程序所访问的内存空间跟另一个程序相互不重叠。以达到应用程序之间的实际物理空间相互隔离的效果。

物理地址如果暴露给进程会使得它们很容易破坏操作系统,用户程序可以寻址内存的每个字节。而且使用这个物理地址模型,要运行多个程序是很困难的。
多个应用程序同时处于内存,并且不互相影响,则需要解决两个问题:保护和重定位。
一个很好的办法就是对物理内存进行抽象,即内存模型,内存地址空间。每个进程都有一个自己的地址空间。地址空间为应用程序创造了一种抽象的内存。就像进程的概念创造了一类抽象CPU以运行程序一样。地址空间就是一个进程可用于寻址内存的一套地址集合。
====================================================
四、谈谈存储器管理
这里的存储器管理其实默认指狭义上的,即内存的管理+虚拟存储器的管理。一般不包括磁盘管理(也就是文件系统),磁盘管理属于操作系统的另一大方面的知识。其实虚拟存储器管理本身就是涉及到磁盘和内存之间的信息流动。这里埋个引子,后面再展开讨论。
内存管理无非就是把内存进行了抽象,抽象成某个内存模型。抽象的目的是为了解决不抽象情况下使用内存所存在的问题,有问题就有了改进的需求。
第二、三节的就是在讨论为什么要进行内存抽象建模(存在的需求和问题)、如何进行抽象建模(地址空间);
在继续讨论存储器管理的各项机制和策略之前,理解存储器管理的需求是很有用的。
主要有五大需求:
1、重定位 //第三节中讲到的,程序中引用地址需要重定位才能访问正确的位置且不干扰其他程序;
2、保护 //多个程序运行时,必须保证相互独立,不能互相干扰。尤其是不能干扰到操作系统;
3、共享 //有时候有需要多个程序之间能有一块共享的内存,你我都可以进行读写。这就是程序之间通信的需求,在不违背1、2的情况下在内存的管理过程中又要保证一定的灵活性;
4、逻辑组织 //内存的地址空间被组织成线性的一维的地址空间。程序本身还可以别划分成模块。不同模块的特性是不同的,有的只能读、有的可读可写、还可以考虑分开独立编译装载。还得有机制可以让某个模块被多个进程共享。那么这个该逻辑组织如何设计来保证这个需求呢?
5、物理组织 //广义上将计算机的存储器分为两级内存(主存)和外存(辅存);外存就是磁盘,大容量,掉电不丢失但是读写速度慢。内存读写速度快,但是成本高,掉电丢失数据。大容量的磁盘适合长期存储、小容量的内存适合保存当前要用的程序和数据。操作系统要关心的是内存和外存之间信息流的组织。让程序员负责这个信息流是不切实际的,需要交给操作系统来办。这里也是操作系统存储器管理的本质所在!!
====================================================
五、交换、分段和分页
第二节讲到了多道程序情况下,直接访问物理地址式的内存管理,存在的问题是重定位和保护!以及使用静态重定位解决重定位问题,但是又导致程序加载太慢。
第三节讲道理对内存进行抽象,创造了每个进程独有的地址空间。并使用虚拟地址访问内存,由MMU转换成物理地址。也就是在程序运行时才进行地址翻译,这就是动态重定位技术。
我们貌似解决了内存管理问题,实际上还有很多问题要解决。回头再看看第四节讲到的五大需求,都实现了吗?
5.1交换管理
参考链接:基本内存管理:https://www.cnblogs.com/edisonchou/p/5090315.html
上面的链接里有谈到了物理内存如何分区 固定分区or非固定分区?空闲的空间如何管理?进程随着运行过程中需要增大空间该如何解决,且如何保证不影响到其他进程?如何保证内存空间利用率高?分区导致的内存空间碎片化问题如何解决?
如果在多进程的环境下,有很多程序都要运行时,内存的空间不够用怎么办?
我们在第四节讲到的虚拟存储器管理就是指虚拟内存技术。其核心思想是把物理内存空间从主存扩大到磁盘空间中。 这就好像使得内存空间增大了一样,实际上是虚拟的。这其实是利用率局部性原理,把程序不经常访问的部分放置在虚拟内存(磁盘空间)中。
如果有需要再把虚拟内存中的程序换入到内存中,内存中不需要访问得程序换出到虚拟内存中。这个过程交做交换。
但是由于磁盘的数据访问速度比内存慢,频繁地进行交换必然导致程序运行速度下降。所以不能进行频繁的换进换出操作。
目前我们的内存管理都是以整个程序(即进程)为单位进行换进换出,这会导致换进换出较为频繁。该如何解决这个问题?后面的分页就是用来解决该问题的。
5.2 分页管理
分页的主要目的是提高内存的利用率。首先每块页分成多大,分成几种,由硬件决定然后由操作系统选择。虚拟地址空间按页分割,进行映射。把常用的代码和数据按页装载到内存中。把不常用的代码保存在磁盘中。
以页为单位来存取和交换这些数据非常方便。硬件本身就支持这种以页为单位的操作方式。
把虚拟空间的页映射到物理内存中的物理页。没有映射到内存中的虚拟页,就留在了磁盘中,这部分虚拟页叫作磁盘页。然后我们在需要进行交换时,按页进行交换即可,及一旦发现虚拟页在内存中没有相应映射物理页,就将该虚拟页从磁盘换进到内存中,完成率映射。
例如程序运行过程中,需要用到某虚拟页VP1,但是VP1不在内存中,硬件就会捕捉到这个错误,即页错误。然后操作系统接管进程,负责将VP1从磁盘中读取出来,装入内存。并将内存中物理页和虚拟页建立映射关系。
所有的硬件都采用一个叫MMU的部件来进行页映射,Memory Management Unit 内存管理单元。页映射模式下,CPU发出的是Virtual Address,程序看到的是虚拟地址。经过MMU之后,变成了Physical Address。一般MMU都集成在CPU内部,不作为独立组件存在。
所以这种分页式管理很灵活,同时结合了交换的原理,按页进行映射,暂时不将整个程序映射到内存中,部分虚拟页留在磁盘中,根据需要交换进内存。而且利用局部性原理,减少不必要的交换。提高了内存的利用率(内存都是在跑有用到的代码),又解决了空间不够的问题(交换技术,分页映射)。
在分页系统的模型下,程序发出的虚拟地址分成两个部分:页号+页内偏移值;
虚拟地址到物理地址翻译的过程就是,从虚拟页到物理页面的映射(Mapping)。MMU都要保存一个页表,页表存放的是虚拟页到物理页的映射。每当映射关系变化,页表都会有更新(虚拟页进出物理页)。页表是由硬件提供支持的,是一个硬件数据结构。所以对用户来说是透明的,无需关心实现细节。
分页的好处是:不会产生外部碎片(页外碎片),整个内存空间利用率很高。而且进程所占的物理上的内存空间可以是不连续的,这非常好。很好地解决了两个问题:1)空间浪费碎片化问题、2)程序大小受限问题,不受内存大小影响(分页+交换共同实现的);
分页技术的存在才能真真切切高效实现虚拟存储器的效果,光有交换是不够的。
到此我们很好解决了五大需求中的重定位、保护、物理组织需求。
5.3 分段管理
分页系统有个问题缺点:一个进程只能占有一个虚拟地址空间。在此种限制下,一个程序的大小至多只能和虚拟空间一样大,其所有内容都必须从这个共同的虚拟空间内分配。
假如一个程序要占用16G的内存空间,但是内存只有8G的话。只采用分页系统的话,这个16G大小程序无论如何是无法映射到8G内存当中的。怎么解决这个问题呢?
分段管理就是将一个程序按照逻辑单元分成多个程序段,每一个段使用自己单独的虚拟地址空间。
对于编译器来说,我们可以给其5个段,占用5个虚拟地址空间。一个段占用一个虚拟地址空间,不会发生一个段增长时碰撞到另一个段的问题。避免了空间不够导致的编译失败。
总结来看,段是信息的逻辑单位。段的长度不固定,决定于用户所编写的程序。通常由编译器在对源程序进行编译时,根据信息的性质来划分。段的目的是便于存储保护和信息的共享;
分段系统能反映程序的逻辑结构,也便于段的共享和保护。这里的分段管理又满足了保护和逻辑组织的需求。
加上分段管理之后,这时候我们再来看MMU的虚拟地址到物理地址的转化过程:
逻辑地址是段标识+段内偏移量。CPU通过查询段表,将逻辑地址转化为线性地址。
然后如果开启了分页功能后,MMU还需要根据页表来讲线性地址转化为物理地址。
所以MMU这个硬件电路,它包含了两个部件,一个是分段部件,一个是分页部件。通过分段机制(逻辑地址转化为线性地址)、分页机制(线性地址转化为物理地址),最终将逻辑地址映射为物理地址。这里我们就看到了完整的虚拟地址到物理地址的地址空间转化过程。分段和分页对于程序来说都是透明的,在操作系统+硬件层面完成的工作。
5.4 段页式管理
页是信息的物理单位;分页是为了实现离散分配的方式,以消减内存的外碎片(但是可能有内碎片,因为页可能填不满),提高内存的利用率。页的大小固定,且由系统决定。机器硬件实现将逻辑地址划分成页号和页内地址两部分。页是为了管理主存的方便而划分的,对用户是透明的;
段是信息的逻辑单位;段的长度不固定,决定于用户所编写的程序。通常由编译器在对源程序进行编译时,根据信息的性质来划分。段的目的是便于存储保护和信息的共享;
段页式存储管理:分页系统能够有效提高内存的利用率,分段系统能反映程序的逻辑结构,便于段的共享和保护。将分页和分段两种存储方式结合起来,就形成了段页式存储管理方式。
程序员按照分段系统结构把地址分为段号+段内位移量;
地址变换机构将段内位移量分解为页号+页内位移量;
系统为每个进程设置一个段表,包括每段的段号,该段的页表起始地址和页表长度。每个段有自己的页表,记录段中每一页的页号和存放在主存中的物理块号。
====================================================
六、谈谈虚拟内存
虚拟内存使得用户感觉内存得到了增加。实际上虚拟内存其实就是存放在磁盘中的一些页文件,或者叫磁盘页。
CPU是不会直接读取磁盘中的这些磁盘页的。必须把磁盘页交换进内存中才行。这个过程也是位于磁盘中的虚拟页建立与内存中物理页映射的过程。

====================================================
七、程序和内存
一个正常程序占用的内存:
栈区:编译器自动分配释放,存放函数的参数值,局部变量值;操作方式类似于数据结构中的栈。
堆区:一般由程序员手动分配释放,若程序员不释放,程序结束时可能由OS回收。与数据结构中的堆是两回事。分配方式倒是类似于链表。
全局区(静态区):程序结束后系统释放。
文字常量区:
或者可看成三个部分:
程序段:只读的程序
数据段:静态数据
堆栈:动态数据
其他:
函数体中定义的变量在栈上
函数体外定义的变量在静态区中
堆:是大家共有的空间,分为局部堆和全局堆。全局堆就是所有没有分配的空间,局部堆是用户分配的空间。堆在操作系统对进程初始化时候分配。运行过程中也可以向系统要额外的堆,
但是记得用完了要还给操作系统,要不然就是内存泄漏。
栈:是线程独有的,保存其运行状态和局部自动变量的。栈在线程开始的时候初始化,每个线程的栈相互独立。
从数据结构角度分析:
是堆栈两种不同的数据结构;
栈是先进后出,堆是随机存储;
栈有一定的结构,操作的时候相对比较快;对在malloc的时候进行动态内存分配,由于其具有动态性,其分配和释放都需要一定开销,效率相对较低。
用户态切换成内核态为什么开销大:
1、首先用户态切换成内核态有哪些情况:1)系统调用、2)异常事件、3)外围设备的中断;
2、开销大,在于这个过程需要很多额外工作。因为内核代码对用户的不信任,系统调用的返回过程有很多额外工作,比如检查是否需要调度。
3、系统调用一般要保存用户的上下文,进入内核时,需要保存用户态的寄存器,返回时需要恢复这些寄存器。
4、每个进程都有两个栈:一个内核态的栈,一个用户态的栈。系统调用时需要进行栈的切换。
5、保存现场,在内核态执行,恢复现场。
这是超越操作系统边界的开销:
1、在执行时间上的开销超过程序调用;
2、开销:建立中断、异常、系统调用号与对应服务例程映射关系的初始化开销
3、建立内核堆栈
4、验证参数
5、内核态映射到用户态的地址空间,更新页面映射权限
6、内核态独立地址空间
====================================================
相关链接:
内存系统为什么要分段: https://blog.csdn.net/f905699146/article/details/72887398
cpu访问内存为什么要分成各种段:https://new.qq.com/omn/20180118/20180118G048AJ.html
计算机层次化存储体系:https://blog.csdn.net/guohexiaoming/article/details/89209061
计算机体系结构和存储分层体系:https://blog.csdn.net/qq_42381849/article/details/90231377
内存管理下-段式内存管理:https://www.cnblogs.com/edisonchou/p/5115242.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号