keepalived+nginx实现高可用集群
keepalived+nginx实现高可用集群
2019-11-06 15:08:13 Asnfy 阅读数 210更多
分类专栏: Linux运维
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/Powerful_Fy/article/details/102935557
keepalived介绍
keepalived通过VRRP(Virtual Router Redundancy Protocl)来实现高可用,在这个协议里会将多台功能相同的服务器组成一个小组,这个小组里会有1个master角色和n个backup角色(n>=1)。
master会通过组播的形式向各个backup发送VRRP协议的数据包,当backup收不到master发来的VRRP数据包时,就会认为master宕机了,此时就需要根据所有backup配置的权重大小来决定谁成为新的mater。
Keepalived要有三个模块,分别是core、check和vrrp。其中core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析,check模块负责健康检查,vrrp模块是来实现VRRP协议的。
使用keepalived实现高可用
需求场景:一台nginx服务器(A机器)代理着多台web服务器实现负载均衡,如该机器出问题,将导致所有web服务器无法访问,那么需要添加一台备用负载均衡服务器(B机器),使用keepalived将A机器与B机器通过virtual_ipaddress(VIP)关联起来,当A机器因为宕机等情况不能工作时,B机器会自动切换为主负载均衡服务器分配请求到后面的web服务器,即实现高可用负载均衡
A机器(master):主负载均衡(192.168.234.128)
B机器(backup):备负载均衡 (192.168.234.130)
在两台机器都安装好nginx和keepalived
nginx安装:https://blog.csdn.net/Powerful_Fy/article/details/102491381
安装keepalived:yum -y install keepalived
1.在A机器(master)操作:
清空keepalived配置文件:
[root@master ~]# > /etc/keepalived/keepalived.conf
- 1
添加如下内容:
global_defs {
notification_email {
asnfy@qq.com
}
notification_email_from root@asnfy.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_nginx {
script "/usr/local/sbin/check_ng.sh" #检测nginx服务状态的脚本路径
interval 3 #检测间隔:3s
}
vrrp_instance VI_1 {
state MASTER #定义角色为master,B机器定义为backup
interface ens33 #指定网卡名称,vppr协议通过该网卡与B机器通信
virtual_router_id 50 #定义路由器id
priority 100 #定义权重,master为100,backup<100
advert_int 1
authentication { #定义认证信息
auth_type PASS #定义认证类型为密码验证
auth_pass keepalived123 #定义密码
}
virtual_ipaddress { #定义VIP
192.168.234.100
}
track_script { #引用上方vrrp_script定义的脚本路径执行脚本
chk_nginx
}
}
创建检测nginx状态的脚本:
[root@master ~]# vi /usr/local/sbin/check_ng.sh
- 1
添加以下内容:
#!/bin/bash
#时间变量,用于记录日志
d=`date --date today +%Y%m%d_%H:%M:%S`
#计算nginx进程数量
n=`ps -C nginx --no-heading|wc -l`
#如果进程为0,则启动nginx,并且再次检测nginx进程数量,
#如果还为0,说明nginx无法启动,此时需要关闭keepalived
if [ $n -eq "0" ]; then
systemctl start nginx
n2=`ps -C nginx --no-heading|wc -l`
if [ $n2 -eq "0" ]; then
echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log
systemctl stop keepalived
fi
fi
赋权:
[root@master ~]# chmod 755 /usr/local/sbin/check_ng.sh
- 1
启动keepalived服务:
[root@master ~]# systemctl start keepalived
- 1
#此时杀掉nginx进程后再次查看,如果发现还nginx进程还在,可以从启动时间发现nginx已经被keepalived启动,表示A机器(master)配置成功
2.在B机器操作:
清空keepalived配置文件:
[root@backup ~]# > /etc/keepalived/keepalived.conf
- 1
添加如下内容:
global_defs {
notification_email {
asnfy@qq.com
}
notification_email_from root@asnfy.com
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_nginx {
script "/usr/local/sbin/check_ng.sh"
interval 3
}
vrrp_instance VI_1 {
state BACKUP #定义角色为backup
interface ens33
virtual_router_id 50 #需要与master配置的相同
priority 90 #权重小于master的数值
advert_int 1
authentication {
auth_type PASS
auth_pass keepalived123
}
virtual_ipaddress {
192.168.234.100 #VIP与master相同
}
track_script {
chk_nginx
}
}
新增检测nginx状态的脚本:
[root@backup ~]# vi /usr/local/sbin/check_ng.sh
- 1
添加以下内容:
#时间变量,用于记录日志
d=`date --date today +%Y%m%d_%H:%M:%S`
#计算nginx进程数量
n=`ps -C nginx --no-heading|wc -l`
#如果进程为0,则启动nginx,并且再次检测nginx进程数量,
#如果还为0,说明nginx无法启动,此时需要关闭keepalived
if [ $n -eq "0" ]; then
systemctl start nginx
n2=`ps -C nginx --no-heading|wc -l`
if [ $n2 -eq "0" ]; then
echo "$d nginx down,keepalived will stop" >> /var/log/check_ng.log
systemctl stop keepalived
fi
fi
赋权:
[root@backup ~]# chmod 755 /usr/local/sbin/check_ng.sh
- 1
启动keepalived服务:
[root@backup ~]# systemctl start keepalived
- 1
此时keepalived+nginx配置的高可用负载均衡就配置好了,当master检测到nginx进程数为0时(nginx服务挂了),会去启动nginx,如果脚本启动nginx后进程数还是为0就表示nginx启动不了,master机器会关闭keepalived服务,当keepalived服务关闭后,backup会自动切换为master接收请求
测试效果:
浏览器访问VIP: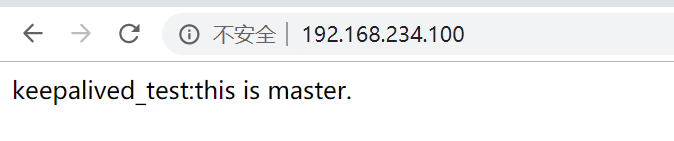
#该页面是手动添加到A机器(master)的nginx默认虚拟主机指定的目录下的,作为测试使用,同时B机器(backup)也添加了测试页面,当前结果表示访问VIP请求到了A机器
关闭A机器keepalived服务:
[root@master ~]# systemctl stop keepalived.service
- 1
再次访问VIP: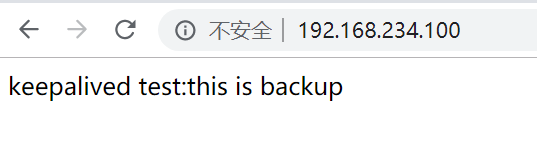
#结果显示请求到了B机器(backup),backup切换master成功
在关闭A机器的keepalived服务后,浏览器访问VIP加载了10秒左右返回结果,说明当A机器出现宕机等原因不能接收请求时,切换到B机器只需要30秒以内的时间即可完成
补充:
1.当master机器keepalived服务关闭后,查看指定网卡(ip add命令)会显示vip已经消失,而backup机器的网卡会加载VIP,当master机器恢复正常后,vip会被重新加载,backup机器的VIP会消失
2.存在多台backup机器的情况下,根据配置文件中priority定义的权重值确定优先级,值越大,master宕机时,优先切换为master
3.公网环境中,VIP为域名解析的IP地址
4.如果出现master和backup机器的网卡同时出现VIP,即为脑裂(一个整体的负载均衡系统,分裂为两个独立节点,这时两个节点开始争抢共享资源,结果会导致系统混乱,数据损坏)
5.如果启用了防火墙,需要添加允许vrrp协议通信
6.master和backup在加载VIP后,都会记录日志信息(/var/log/message)可以通过查看日志信息查看VIP加载和节点切换情况的信息

 浙公网安备 33010602011771号
浙公网安备 33010602011771号