搜索引擎(1)—— 概述与功能架构
1 背景
做搜索引擎有有2年时间了,算是有个基本的入门。决定写一个系列博客,记录下自己所认识的搜索引擎,也希望对新入行的朋友有些帮助。
2 概述
搜索与推荐
互联网上有海量的信息,从互联网上获取信息或娱乐,最主要的2个途径就是搜索和推荐。
-
搜索:是用户主动去查询与获取自己想要的信息,用户有明确的意图,知道自己想要什么。基本所有app的首页,都会有一个搜索框,提供搜索功能。
-
推荐:web或app主动向用户推荐他可能感兴趣的内容,用户从被推荐的内容中,挑选自己感兴趣的内容观看,是一个偏被动的过程。新浪官网首页,淘宝首页等这些页面提供的大量信息,都是推荐,有些是非个性化的,有些是个性化的。今日头条的信息流,也是典型的个性化推荐产品。
搜索与推荐的最大差异,就是主动与被动。
搜索领域
当前搜索推荐都涉及互联网的各个领域,可以简单的粗分成这2类
- 综合领域:像百度、google、搜狗、360等,搜索全网内容,一般叫大搜。一般搜索的内容是互联网上的网页,多数是通过爬虫获取到,通过网页的标题和正文来搜索。
- 垂直领域:像视频、音乐、电商、小说等,只搜索特定领域的内容,一般叫垂搜或小搜。垂域搜索的数据,往往是非常结构化的,比如淘宝里的商品,优酷里的影片信息等,与网页相比,文本偏短。
除此之外,还有像地图、酒店、机票等各种垂直领域的搜索。每个领域都有自己的一些特殊业务诉求。
搜索功能
一般搜索产品都至少包括2个功能:
- suggest(智能提示或联想):用户在搜索框输入过程中,下拉列表展现的补全结果,猜用户想搜索的内容,用户一旦点击,就可以立即发起搜索请求,减少用户输入动作,提高用户体验。
- 搜索:用户在搜索框输入完内容,点击搜索按钮或回车,看到完整搜索结果。
- 相关搜索(related searches):google和百度搜索结果页的底部,都有展示相关搜索,即搜索query_a的用户,也喜欢搜索query_b, query_c等。
suggest和相关搜索技术相对简单些,可以算是搜索的一个子集,所以后面不再多介绍。
几个基本概念
首先介绍几个缩写基本概念:
-
缩写
-
query:搜索关键字,也叫keyword
-
doc:被搜索的内容,比如一个网页,一部影响,一件商品,在索引里是一条记录,都叫一个doc
-
QU:query understanding,查询理解,即对query进行分析,得到一些用户意图相关的信息,辅助检索
-
index:索引
-
term:query分词后,每个词,称为一个term
-
-
正排索引:以doc作为key,以这个doc包含的term或属性信息作为value,就是常规的数据库存储结构。便于通过docId,查询这个doc的属性信息。想像一下,如果要检索出所有包含“apple”的网页,需要将索引里所有doc遍历一遍。
-
倒排索引:与正排相反,以term作为key,以包含这个term的所有doc的ID作为value,构建出的KV结构。如果要检索出包含“apple”的网页,只需要以apple作为key,一把就能取出所有包含apple这个词的网页。
3. 流程和架构
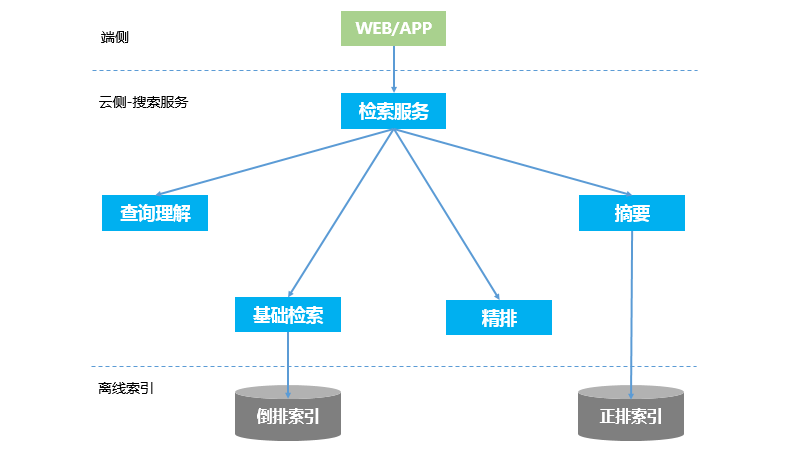
搜索引擎的在线检索架构如图1所示。主要包含以下几个模块:查询理解(QU),基础检索,精排(重排),摘要(高亮、飘红)。除此之外,可能还会有运营干预之类的模块。
垂搜与大搜的架构基本一致。相比大搜,垂搜在某些模块上会简化。比如摘要,垂搜会比大搜简单很多。
- 倒排索引:
下面简单介绍下每个模块的功能
3.1 检索服务(编排)
图1中的检索服务,实际上是个编排模块,接受端侧的搜索请求,负责整个在线检索的流程串通,本身没有实质性的功能。所以,也是其中最简单的一个模块。
编排模型会依次调用查询理解、基础检索、精排、摘要这4个模块,每一个模块的输出,作为下一个模块的输入。
3.2 查询理解(QU)
QU的功能,是对用户输入的query进行分析,以支撑后续的搜索排序效果。
QU的主要功能包括:
-
分词:搜索|是|什么
-
实体识别:人名、地名、影片名、机构名、歌曲名等等
-
意图/需求识别:常见的意图类型包括:问答、新闻、软件下载、视频、小说等
-
同义词识别:
-
查询改写:
-
纠错:搜索阴晴 -> 搜索引擎
-
词权重计算:计算query分词后,每个term的权重是多少
-
核心词选择:query分词后,哪些词是必须命中的,即核心词只要没命中这个内容就不会被搜索出来
-
紧密度分析:query中,相邻两个词之间的紧密关系,是否需要连续命中
QU中很多模块的效果,依赖于NLP能力,例如分词、实体识别、意图识别等。像纠错、改写等,也强依赖于用户的行为日志。
3.3 基础检索
基础检索(粗排)是做第一轮检索,从全量索引中召回网页候选集(例如top1000),并做一个排序。整个搜索的过程,就像是一个漏斗筛选的过程,基础检索是第一次筛选,如果没有被筛选出来,就不会成为本次的搜索结果。
由于基础检索涉及的网页量非常大,对性能要求高,所以一般只用少量最重要的特征,相对简单的策略来做召回。不亦使用太多的特征和太复杂的模型。
检索的过程主要分2步,
-
根据query的核心词term,从倒排索引中取出倒排拉链。每个核心词对应一个倒排拉链,多个核心词的拉链取交,得到基础检索的一个候选集合。
-
对候选集中的每个doc,计算它与query的匹配分数以及doc本身的质量得分,合并后得到一个总的分数并做降序排序。最终,再按一个阈值(例如1000)做截断,作为基础检索的结果。
一个网页是否能被基础检索召回,主要取决于几个因素:1)doc是否满足term倒排求交条件;2)doc与query的相关性得分;3)doc本身的质量(静态特征,与query无关)
3.4 精排
精排是对基础检索召回的结果,做一个更精准的排序。由于基础检索召回的数量有限(1000条以内),相比粗排,精排需要处理的doc数量少了很多,就可以用更丰富的特征,更复杂的算法模型(LTR),以得到更精准的排序效果。
除了使用排序模型,精排也可以使用一些人工策略来调权。
在精排之后,也会根据运营干预的策略,对结果做进一步的调整干预。
最终,根据翻页参数,只返回10或15条结果给上游。
3.5 摘要
精排返回的结果,还要补充些信息,才能在终端界面上展示。例如淘宝搜索结果,需要展示商品的图片、标题、销量等一系列信息。
一般的垂直领域,只要把doc的几个属性展示出来即可。网页搜索比较特殊,一般网页正文很长,但是最终展示的只有简短的三两行文字片段。这个片段,就是网页的摘要信息。摘要模块的主要目标,主要就是从网页正文中,抽取出匹配最好的那一两个片段,并把与query匹配的那些词标红,让用户直观的看到这个网页与query的匹配关系。
4 结束语
上述是在线检索的一个基本流程,每一个模块展开,都有大量的内容。后续展开详解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号