
nnU-Net学习笔记(一):论文阅读
nnU-Net学习笔记(一):论文阅读
源码地址:https://github.com/MIC-DKFZ/nnUNet
论文: https://arxiv.org/abs/1809.10486
1.动机:
- 最近的网络修改在特定适用于某些问题(过拟合),确切架构、预处理、训练、推理和后处理的相互依赖的选择很常导致U-Net在作为基准时表现不佳。
- 有些网络结构的修改提高了网络性能,是因为网络尚未完全针对当前任务进行优化
- 本文认为,在分割方法中,非架构方面的影响要大得多,同时也被严重低估了
2.主要工作:
提出了一种框架,它的特点是:
- 在网络结构上只对U-Net进行了微小修改
- 能够自动调整其体系结构以适应给定的图像几何形状
- 彻底定义了其他所有步骤,这些步骤可能造成网络结构的提升或者下降:预处理(例如重新采样和归一化),训练(例如损失,优化器设置和数据增强),推理(例如基于补丁的策略和在测试时增强和模型的集成)以及潜在的后处理(例如强制单连通分量,如果适用)。
3.方法:
-
网络结构
-
修改了:使用Leaky ReLU替代ReLU,使用实例规范化替换批规范化
-
2D U-Net:虽然沿Z周 的有价值信息不能被聚合和考虑,但是有证据显式在各向异性的数据集中,3D分割方法的表现可能会恶化(各向异性:数据集的各向异性指的是数据中特征的不对称性。这可能是因为图像的缩放、旋转、对称性等因素造成的。各向异性会影响模型的性能,因此需要对数据进行预处理以减少各向异性的影响。)
-
3D U-Net:由于gpu显存的影响,我们只能在patches上训练这种架构,这样对于较小图像的数据集不是一个问题(大小是针对每个患者的体素数量而言的),但是在具有大图像的数据集中,由于有限视场,不能收集足够的上下文信息
-
U-Net Cascade:首先用低分辨率图像粗分割,再用全分辨率图像细分割。目的是解决 3D Unet在大图像尺寸数据集上的缺点。阶段一:3D U-Net在下采样后的图像上训练,然后该网络的分割结果被上采样到原始体素间距,并作为额外的(独热编码)输入通道传递给第二个3D U-Net(将分割结果以独热编码的形式concat到全分辨率图像上然后由第二个3D U-Net进行分割)。阶段二:在全分辨率的patches上训练3D U-Net。
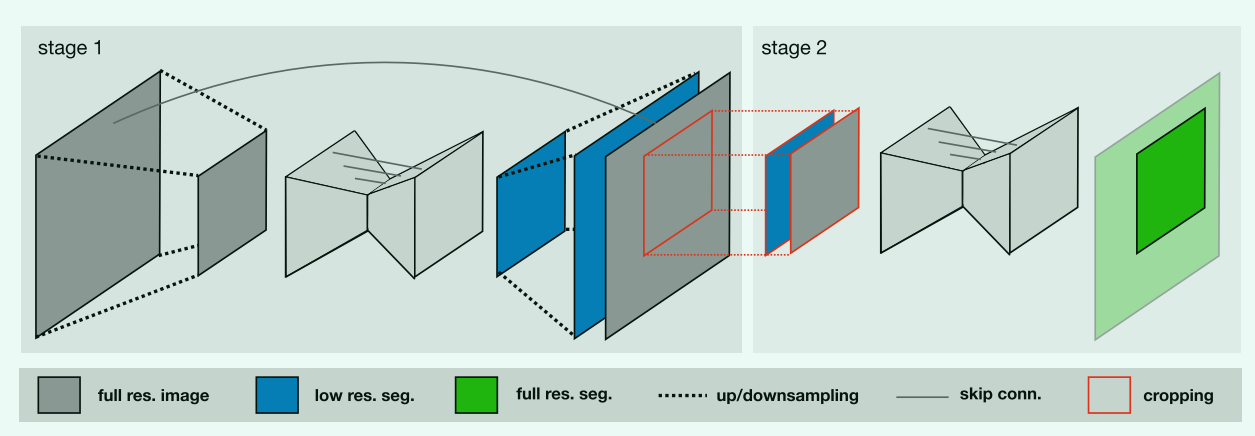
-
网络拓扑结构的动态自适应:不同数据集的图像大小不一,因此输入的patch大小,对于每个维度池化操作的数量(也意味着卷积层的数量)必须能够根据图像大小自动调整,以允许空间信息的充分聚合。本文不仅考虑图像几何形状的适应,还考虑了可用内存等技术限制,指导原则是动态地权衡批处理大小和网络容量。
对于2D U-Net:
- 输入patch大小为256×256,批量大小为42,最高层的特征映射数为30(特征映射数量在每次下采样时加倍)
- 自动调整这些参数以适应每个数据集的中位面大小(我们使用平面内分辨率最低的平面,对应分辨率最高)
- 沿着每个轴进行池化,直到该轴的特征图大小小于8(但不多于6次池化操作)
对于3D U-Net:
- 在最高分辨率层使用30个特征图。我们从输入patch大小为128 × 128 × 128的基础配置开始,批量大小为2
- 将输入patch大小的纵横比与数据集在体素上的中位数形状匹配。如果数据集的中位形状小于1283,则使用中位形状作为输入补丁大小,并增加批量大小(以使处理的体素总数与128 × 128 × 128和批量大小为2相同)
- 沿着每个轴池化操作(最多5次),直到特征图的大小为8。。
对于任何网络,将每个优化步骤处理的体素总数(即输入patch体积×batch size)限制为数据集的5%,如果超量,我们减小批大小(最小为2)
-
-
预处理
-
裁剪:所有数据被裁剪到非零值区域
-
重采样:所有图像数据都被重新采样到各自数据集的中位体素间距,其中图像数据使用三阶 spline 插值,相应的分割掩码(一个与图像相同大小的二进制图像,其中每个像素的值表示对应的输入图像像素是否属于特定的对象或区域)使用最近邻插值。
U-Net级联的必要性由以下确定:如果重采样数据的中值形状超过三维U-Net(批大小为2)可作为输入的patch的体素的4倍以上,则它符合U-Net级联的条件,并且该数据集被额外重采样到较低的分辨率。如果数据集是各向异性的,则首先对高分辨率轴进行下采样,直到它们与低分辨率轴/轴相匹配,然后才同时对所有轴进行下采样。
-
标准化:
- CT图像则收集训练数据集的分割掩码中出现的所有强度值,并通过裁剪到这些强度值的[0.5,99.5]百分位数来对整个数据集进行归一化,然后根据所有收集的强度值的均值和标准差进行ZScore归一化。
- MRI或其他图像模式,简单的Z评分归一化。
如果裁剪将数据集中图像的平均大小(以体素为单位)减少1/4或更多,则规范化只在非零元素的掩码内进行,掩码外的所有值都设置为0。
-
-
训练过程
使用五重交叉验证进行训练,
损失函数:\(L_{total}=L_{dice}+L_{cross-entropy}\),对于3D U-Net,计算批中每个样本的Dice损失和批中的平均值。对于其他网络,将批中的样本解释为伪体,并计算批中所有体素的Dice损失。
Dice损失函数:\(L_{dc}=-\frac{2}{\abs{K}}\sum_{k \in K}\frac{\sum_{i \in I}u_i^kv_i^k}{\sum_{i\in I}u_I^K+\sum_{i \in I}v_i^k}\)
其中u是网络的Softmax输出,v是真值分割图的独热编码。 u和v都具有形状\(i×k\),\(i∈I\)为\(\frac{训练块的像素数}{批中的像素数}\),\(k∈K\)为类。
其他参数:在所有实验中使用初始学习速率为\(3×10^{-4}\)的Adam优化器。 我们将迭代定义为超过250个训练批次的迭代。 在训练期间,我们保持验证(\(l_{MA}^v\))和训练(\(l_{MA}^{t}\))损失的指数移动平均值。 当\(l_{MA}^{t}\)在过去30个历元内没有改善至少5×10-3时,学习速率降低因子5。 如果\(l_{MA}^v\)在最近60个历元内没有改善超过5×10-3,但在学习速率小于10-6之前没有改善,则自动终止训练。
-
数据增强:
在训练过程中应用了以下增强技术:随机旋转、随机缩放、随机弹性变形、Gamma校正增强和镜像。如果一个3D U-Net的输入patch尺寸的最大边长是最短边长的两倍以上,使用2D数据增强来代替,并对每个样本逐条应用它。U-Net级联的第二级接收前一步的分割结果作为额外的输入通道。 为了防止强烈的共适应,我们应用随机形态学算子(erode, dilate, open, close),并随机删除这些分割的连通分量。
-
模型推理
推断也都基于patch进行。 由于网络准确性朝着patch的边界降低,因此,当汇总跨patch的预测时,我们将靠近中心的体素的权重设置为高于靠近边界的体素的权重。 通过按patch大小/ 2选择patch以使其重叠,我们通过沿所有有效轴镜像所有patch来进一步利用test time data augmentation(测试时间数据增强)
-
后处理
对训练数据执行所有ground truth分割标注的连通成分分析(它通过分析图像中相连的像素组,以找出图像中的物体和背景。连通成分分析的目的是将图像中的每个物体分为一个独立的连通块,并为其分配一个唯一的标识符)。 如果一个类在所有情况下都在单个连通分量中,则将其解释为数据集的一般性质。 因此,在相应数据集的预测图像上,除了该类的最大连通分量以外,所有连通分量都将被自动删除,以减少假阳性区域。
-
集成与结果提交
为了进一步提高分割性能和鲁棒性,文章中的三个模型中的两个可能的组合被集成到每个数据集。 对于最终提交,自动选择在训练集交叉验证中获得最高Forground Dice Score的模型(或集合)。
Forground Dice Score:用于评估预测的前景与真实前景的相似度,Foreground Dice Score是两个图像的交并集与它们的并集的比率。公式如下:\(Foreground Dice Score = 2 * |A∩B| / (|A| + |B|)\),其中:
- A是预测的前景图像
- B是真实前景图像
- |A|和|B|分别表示A和B中非零元素的个数
- |A∩B|表示A和B的交集中非零元素的个数
Foreground Dice Score通常用于评估图像分割任务的准确性,范围从0到1,值越接近1,预测的前景与真实前景的相似度就越高。
4.实验与结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号